










下定决心开始写博客,希望能在写博客的过程中,总结思路,加深理解。在这里分享心得体会,共同进步。如有不足之处望批评指正。
本博客包含本人学习SVM和PCA的笔记,简要的说明其原理和方法步奏,人脸识别程序的解释说明,一并奉上完整的Matlab代码和相关的学习资料。
感觉自己在这上面花了不少时间但停留在一个较浅层次的了解上,希望后面学习SVM的朋友们能少走弯路。本人才疏学浅,博客难免有错漏,请见谅。如有转载请注明出处。
废话不多说,开始正文。
一. 支持向量机(SVM)
1.基本原理
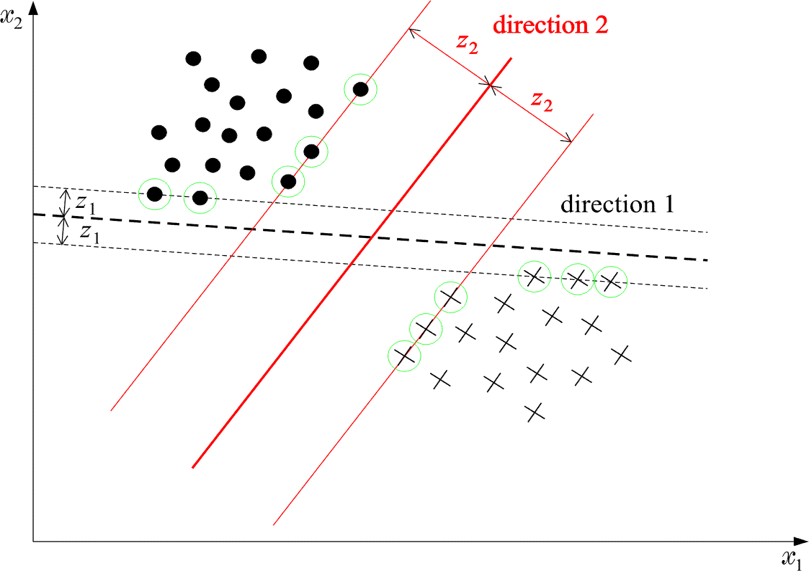
给定训练样本集,在特征空间上找到一个分离超平面,将样本点分到不同的类。其中当且存在唯一的分类超平面,使得样本点距离分类超平面的距离最大。其中,距离超平面最近的点为该超平面的支持向量。
找到超平面后,对于待测点,通过计算该点相对于超平面的位置进行分类。其中,一个点距离分离超平面的距离越大,表示分类预测的确信程度越高。
SVM的数学推导非常繁琐,我个人了解得还不够透彻,推荐去看李航编写的《统计学习方法》,里面的数学理论推导非常详细。还有斯坦福大学的公开课《机器学习》,对这部分讲解得深入浅出,非常推荐。
2.惩罚参数C
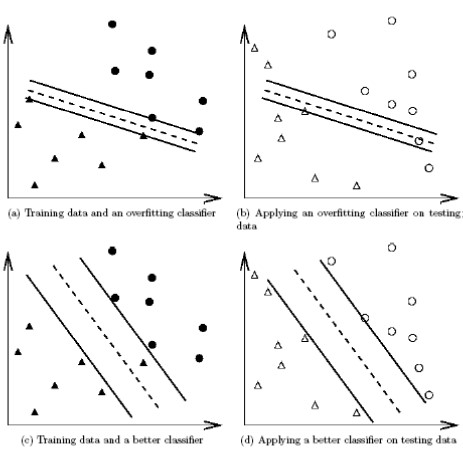
惩罚参数表示对误分类点的惩罚权重。 如下图所示,惩罚参数的设置相当与在训练集的误差和间隔平面的距离上做一个折衷选择。当惩罚参数过大,如(a)易出现过拟合的情况,预测时,易导致误分情况。减小惩罚参数,开始容忍样本点落入间隔平面之内。过小会导致训练集的样本点对结果影响变小分类功能丧失。因此,选择合适的惩罚参数,会大大提高分类器的性能,非常关键。 实际运用过程中,采用交叉验证的方法选择合适的参数C。
在这里简要的提一下交叉验证(Cross Validation)的思想:即将所有的样本分成:训练集(train set),验证集(validation set)和测试集(test set),合适的划分比例如(3:3:4),使用不同的参数训练样本,在验证集上验证表现性能,得到一组最佳参数再应用在测试集上计算最终精度。此方法可大大减少因设置参数花费的时间。
3.核函数
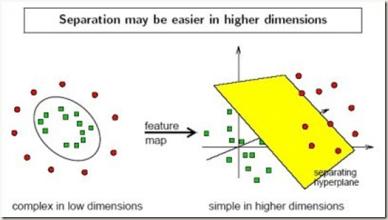
实际的训练集通常是线性不可分的,这就需要运用到核技巧将原空间中的点映射到线性可分的高维空间。
常用的核函数有:线性核函数、多项式核函数、高斯核函数(RBF核函数),sigmoid核函数。
核函数的选择对分类器的影响较大,但是怎样选择我还是只能试,如果有核函数选择的经验,欢迎分享交流。
4.多分类支持向量机
实际分类通常涉及多类问题的区分,而SVM的理论是二类问题的区分,解决多类问题通常的方法如下,前两种方法最常见:
- 一对多(one-vs-rest)
构造k个SVM,分类时将未知样本分类为具有最大分类值的那类。 - 一对一(one-vs-one)
任意两个样本之间设计一个SVM共n(n-1)/2,分类时为得票最多的类。 - 层次分类(H-SVMs)
分层:所有类别分成子类,子类再分,循环得到单独的类。
5.libsvm工具箱
libsvm是台湾大学林智仁教授开发设计的一个简单、快速有效的SVM模式识别和回归的软件包,可在C、Java、Matlab、C#、Ruby、Python、R、Perl、Common LISP、Labview等数十种语言里实现。提供了很多默认参数,使用起来非常方便。下面附上的SVM人脸识别程序在matlab上运行时要提前安装好这个工具包,大大简化程序。
下载地址: https://www.csie.ntu.edu.tw/~cjlin/libsvm/
libsvm的安装教程:http://blog.csdn.net/loadstar_kun/article/details/7712308
注意:请确保先安装好VS,推荐安装VS2010 VS2012,并且Matlab的版本不能太低,如果先不匹配出现一些奇奇怪怪的原因导致安装不成功,我曾经在这上面耗费很多时间最后只好放弃那台电脑了。
二.主成分分析(PCA)
Principle Component Analysis,用于简化数据的复杂性,极大的保留原始数据的特征(差异大的特征),用于降维处理,便于后续进一步计算和操作。
包含如下步骤:
去除平均值(中心化样本)
CenteredMatrix = OriginalMatrix-repmat(mean(OriginalMatrix),numPic,1);
计算协方差矩阵
CovMatrix = CenteredMatrix’*CenteredMatrix;
计算协方差矩阵的特征值和特征向量
[V,D]=eigs(CovMatrix,kdimension);
(通常原始特征维数可能比较高,为避免协方差矩阵过于庞大的情况,协方差矩阵的特征向量通过计算CenteredMatrix*CenteredMatrix’的特征值和特征向量来间接获得)将特征值从大到小排序,保留前N个特征向量(作为新的低维空间的基)
将数据转换到上述N个向量构成的新空间
pcaMatrix = CenteredMatrix*V;
三. 人脸识别程序
本程序主要参考了博文:http://blog.csdn.net/yb536/article/details/40586695,并对其做了一些改动。
1. FaceRecognition.m主程序
将人脸图像生成用于训练和测试的矩阵,并分别生成相对的类别标签矩阵,使用libsvm工具箱操作。
svmtrain
model = svmtrain(train_label,train_data,option);
option的可选项:- -s svm类型:
SVM设置类型(默认0) 0 – C-SVC 1 –v-SVC 2 – 一类SVM 3 – e -SVR 4 – v-SVR
- -t 核函数类型:核函数设置类型(默认2) 0 – 线性:u’v 1 – 多项式:(r*u’v + coef0)^degree 2 – RBF函数:exp(-r|u-v|^2) 3 –sigmoid:tanh(r*u’v + coef0)
- -d degree:核函数中的degree设置(默认3)
- -g r(gama):核函数中的函数设置(默认1/ k)
- -r coef0:核函数中的coef0设置(默认0)
- -c cost:设置C-SVC, -SVR和-SVR的参数(默认1)
- -n nu:设置-SVC,一类SVM和- SVR的参数(默认0.5)
- -p e:设置 -SVR 中损失函数的值(默认0.1)
- -m cachesize:设置cache内存大小,以MB为单位(默认40)
- -e :设置允许的终止判据(默认0.001)
- -h shrinking:是否使用启发式,0或1(默认1)
- -wi weight:设置第几类的参数C为weightC(C-SVC中的C)(默认1)
- -v n: n-fold交互检验模式,n为折数,>2
- -s svm类型:
svmpredict
[predict_label,accuracy/mse,dec_value]=svmpredict(test_facelabel,scaled_testface,model);
说明:主程序运行后来注释掉了交叉验证那部分的代码,以为交叉验证主要用于选取参数,通常遍历可选范围选取最优解,非常耗时。开始时运行那部分代码,得到较好的参数后注释掉,再把直接写入svmtrain可节省实验预测时间。
clc,clear
npersons=40;%选取40个人的脸
%%
%读取训练数据
global picn; %picn存放随机选择的人脸号的索引
picn = randperm(10); %随机从每个人的10张照片抽取p张作为训练集
disp('读取训练数据...')
[f_matrix,train_label]=ReadFace(npersons,0);%读取训练数据
nfaces=size(f_matrix,1);%样本人脸的数量
disp('.................................................')
%低维空间的图像是(nperson*5)*k的矩阵,每行代表一个主成分脸,每个脸k维特征
%对训练集进行降维处理
%计算训练时间
tic;
disp('训练数据PCA特征提取...')
mA=mean(f_matrix);
global k
k=35; %降维至 10 15 25 35 50 70 100维
[train_pcaface,V]=fastPCA(f_matrix,k,mA);%主成分分析法特征提取
disp('.................................................')
%显示主成分脸,即特征脸,低维的基
disp('显示主成分脸...')
%visualize(V)%显示主分量脸 ,即特征脸
disp('.................................................')
%低维训练集归一化
disp('训练特征数据归一化...')
disp('.................................................')
lowvec=min(train_pcaface);
upvec=max(train_pcaface);
train_scaledface = scaling( train_pcaface,lowvec,upvec);
%SVM样本训练
disp('SVM样本训练...')
disp('.................................................')
%交叉验证选择合适的参数
%[bestacc,bestc,bestg] = SVMcgForClass(train_label,train_scaledface,-2,4,-2,2,3,0.25,0.25,0.5);
%选择线性核函数,惩罚参数设置为0.5 0.7 1 1.2 1.5 2.0
model = svmtrain(train_label,train_scaledface,'-s 0 -t 0 -c 1.2');
toc;
disp('读取测试数据...')
disp('.................................................')
[test_facedata,test_facelabel]=ReadFace(npersons,1);
%测试数据降维
disp('测试数据特征降维...')
disp('.................................................')
m=size(test_facedata,1);
for i=1:m
test_facedata(i,:)=test_facedata(i,:)-mA;
end
test_pcatestface=test_facedata*V;
disp('测试特征数据归一化...')
disp('.................................................')
scaled_testface = scaling( test_pcatestface,lowvec,upvec);
%利用训练集建立的模型,对测试集进行分类
disp('SVM样本分类...')
disp('.................................................')
[predict_label,accuracy,decision_values]=svmpredict(test_facelabel,scaled_testface,model); %输出预测结果计算分类精度2.ReadFace.m函数
这里使用的是Orl的人脸库,共40个人,每个人10张脸共400张样本图。
function [f_matrix,realclass]=ReadFace(n_persons,flag)
global picn;
imgrow=112;
imgcol=92; %输入人脸图片的尺寸
np = 5; %np=3,4,5作为测试集
if flag==0
nn=np;
else
nn=10-np;
end
realclass=zeros(n_persons*nn,1);
f_matrix=zeros(n_persons*nn,imgrow*imgcol);
for i=1:n_persons
%路径设置
%函数num2str(i)说明:将数字转化为字符
%路径因不同情况而定
facepath=strcat('E:\Program\imageData\faceImage\orlData\',num2str(i),'\');
cachepath=facepath;
for j=1:nn
facepath=cachepath;
if flag==0
%前np个样本作为训练集
facepath=strcat(facepath,num2str(picn(j)));
else
%后10-np个样本作为测试集
facepath=strcat(facepath,num2str(picn(j+np)));
end
realclass((i-1)*nn+j)=i;
facepath=strcat(facepath,'.pgm');
%函数imread说明:读取输入路径的图片,将每个像素灰度值保存在输出的矩阵中
img=imread(facepath);
f_matrix((i-1)*nn+j,:)=img(:)';
end
end
end3.fastPCA.m函数
function [ pcaA,V] = fastPCA( A,k,mA)
m=size(A,1); %m为读取图片的张数
Z=(A-repmat(mA,m,1)); %中心化样本矩阵
%一般用中心化的矩阵代替原矩阵。将数据集的均值归零(预处理),保留数据之间的变化信息,便于找到区分。
T=Z*Z';
[V1,D]=eigs(T,k);%计算T的最大的k个特征值和特征向量
V=Z'*V1; %协方差矩阵的特征向量
for i=1:k %特征向量单位化
l=norm(V(:,i));
V(:,i)=V(:,i)/l;
end
%单位化后的V才能是真正的低维空间的基,需要满足正交化单位化两个条件
pcaA=Z*V; %线性变换,降至k维 ,将中心化的矩阵投影到低维空间的基中,V就是低维空间的基
end 4.scaling.m函数
function scaledface = scaling( faceMat,lowvec,upvec )
upnew=1;
lownew=-1;
[m,n]=size(faceMat);
scaledface=zeros(m,n);
for i=1:m
scaledface(i,:)=lownew+(faceMat(i,:)-lowvec)./(upvec-lowvec)*(upnew-lownew);
%将图像数据中一个样本的不同维度的值,最小值和最大值规范到-1和1,其他值按比例规范到(-1,1)
end
end5.SVMcgForClass.m子函数
用于交叉验证,选择合适的参数,参考来源:《MATLAB神经网络43个案例分析》北京航空航天出版社
%% 子函数 SVMcgForClass.m
function [bestacc,bestc,bestg] = SVMcgForClass(train_label,train,cmin,cmax,gmin,gmax,v,cstep,gstep,accstep)
%SVMcg cross validation by faruto
%
% by faruto
%Email:patrick.lee@foxmail.com QQ:516667408 http://blog.sina.com.cn/faruto BNU
%last modified 2010.01.17
%Super Moderator @ www.ilovematlab.cn
% 若转载请注明:
% faruto and liyang , LIBSVM-farutoUltimateVersion
% a toolbox with implements for support vector machines based on libsvm, 2009.
% Software available at http://www.ilovematlab.cn
%
% Chih-Chung Chang and Chih-Jen Lin, LIBSVM : a library for
% support vector machines, 2001. Software available at
% http://www.csie.ntu.edu.tw/~cjlin/libsvm
% about the parameters of SVMcg
if nargin < 10
accstep = 4.5;
end
if nargin < 8
cstep = 0.8;
gstep = 0.8;
end
if nargin < 7
v = 5;
end
if nargin < 5
gmax = 8;
gmin = -8;
end
if nargin < 3
cmax = 8;
cmin = -8;
end
% X:c Y:g cg:CVaccuracy
[X,Y] = meshgrid(cmin:cstep:cmax,gmin:gstep:gmax);
[m,n] = size(X);
cg = zeros(m,n);
eps = 10^(-4);
% record acc with different c & g,and find the bestacc with the smallest c
bestc = 1;
bestg = 0.1;
bestacc = 0;
basenum = 2;
for i = 1:m
for j = 1:n
cmd = ['-v ',num2str(v),' -c ',num2str( basenum^X(i,j) ),' -g ',num2str( basenum^Y(i,j) )];
cg(i,j) = svmtrain(train_label, train, cmd);
if cg(i,j) <= 55
continue;
end
if cg(i,j) > bestacc
bestacc = cg(i,j);
bestc = basenum^X(i,j);
bestg = basenum^Y(i,j);
end
if abs( cg(i,j)-bestacc )<=eps && bestc > basenum^X(i,j)
bestacc = cg(i,j);
bestc = basenum^X(i,j);
bestg = basenum^Y(i,j);
end
end
end
% to draw the acc with different c & g
figure;
[C,h] = contour(X,Y,cg,70:accstep:100);
clabel(C,h,'Color','r');
xlabel('log2c','FontSize',12);
ylabel('log2g','FontSize',12);
firstline = 'SVC参数选择结果图(等高线图)[GridSearchMethod]';
secondline = ['Best c=',num2str(bestc),' g=',num2str(bestg), ...
' CVAccuracy=',num2str(bestacc),'%'];
title({firstline;secondline},'Fontsize',12);
grid on;
figure;
meshc(X,Y,cg);
% mesh(X,Y,cg);
% surf(X,Y,cg);
axis([cmin,cmax,gmin,gmax,30,100]);
xlabel('log2c','FontSize',12);
ylabel('log2g','FontSize',12);
zlabel('Accuracy(%)','FontSize',12);
firstline = 'SVC参数选择结果图(3D视图)[GridSearchMethod]';
secondline = ['Best c=',num2str(bestc),' g=',num2str(bestg), ...
' CVAccuracy=',num2str(bestacc),'%'];
title({firstline;secondline},'Fontsize',12);相关学习资料:
基于MATLAB,运用PCA+SVM的特征脸方法人脸识别 http://blog.csdn.net/yb536/article/details/40586695
统计学习方法 李航等 清华大学出版社 http://download.csdn.net/detail/lengwuqin/7509495
《MATLAB神经网络43个案例分析》王小川等 北京航空航天出版社 http://download.csdn.net/detail/lengwuqin/7509495
LIBSVM简介及其使用方法 http://endual.iteye.com/blog/1267442
关于SVM http://www.dataguru.cn/thread-371987-1-1.html
SVM理解 http://blog.csdn.net/viewcode/article/details/12840405
Coursera斯坦福大学机器学习 https://www.coursera.org/learn/machine-learning/home/welcome
Orl人脸数据库 http://download.csdn.net/detail/u014609362/7807751
2016/6/25 于上海














 3897
3897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









