







之前分析过HashMap,Hashtable的源代码,前者不支持多线程环境,但是如果使用了的话,在一定情况下会导致死锁,以后会分析。后者支持并发,但是每次只能有一个线程来操作。也就是说,这个锁是锁定了整个数组。
鉴于这种情况,Doug Lea 就想出了使用分段锁技术,网上也有一些资料叫做锁分离技术。
原理是这样的,先构造一个ConcurrentHashMap对象,这个对象中有很多个段对象(segment),也就是segment的数组,然后每个segment再引用一个Entry对象作为域字段,这个Entry对象就和HashMap中的Entry对象大同小异了,但是也有差别。这样再添加key-value的时候,先对key进行hash计算,将hash的结果能够均匀映射到这个segment数组的下标上。然后再通过segment进行计算,将hash映射到Entry对象上。每次添加删除操作时,都是在segment对象上做计算,这样就可以保证多个线程同时访问map对象了。但是针对size(),contains()等类似的方法时,就需要查找所有的segment对象,具体逻辑是什么,我们仔细看。上面说的结构如下:
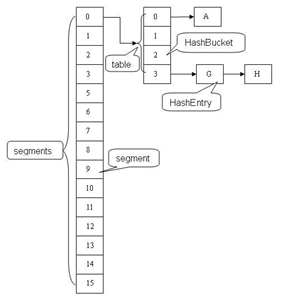
现在先看看map的域字段有哪些:
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
static final int MAX_SEGMENTS = 1 << 16;
static final int RETRIES_BEFORE_LOCK = 2;
final int segmentMask;
final int segmentShift;
final Segment<K,V>[] segments;
transient Set<K> keySet;
transient Set<Map.Entry<K,V>> entrySet;
transient Collection<V> values;从这里看字段非常多,而且字段名也比较奇怪,因此先放在这里,我们一会通过构造函数来分析结果。其中有一个需要说明,就是segments对象,就是我们上面所说的segment数组。这个数组包含了Entry对象。
平时使用默认没有参数的构造函数:
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}它调用了另外一个构造函数:
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}这个构造函数需要三个参数,现在通过代码逻辑以及JDK源码注释来分析一下构造函数做什么了?
第一步,先检查参数大小,第一个loadFactor和HashMap中的loadFactor是一样的作用,加载因子。这个是不能大于0的,另外两个不能小于0.
第二步,检查concurrencyLevel是否大于MAX_SEGMENTS 参数,这个参数的源码注释如下:
/**
* The maximum number of segments to allow; used to bound
* constructor arguments. Must be power of two less than 1 << 24.
*/
static final int MAX_SEGMENTS = 1 << 16; // slightly conservativeMAX_SEGMENTS 用于记录最大可以允许多少个段对象。这里定义的是1<<16. 而且注释还说,这里这个是保守的定义,最大的话不能超过1<<24.由此可以看出concurrencyLevel 的作用就是定义了segments数组的长度,也就是并发级别,允许多少个线程同时使用这个map对象。
第三步开始就很复杂了….
每一段的分析,这一段定义了两个变量,
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}这一段代码只有一个注释:
Find power-of-two sizes best matching arguments
翻译成中文的意思是说,找到最匹配参数的2的N次方的长度。
这一段逻辑如下:
就是ssize每一次乘2,那么sshift就加1,实际上sshift计算结果就是2的N次幂=concurrencyLevel中的N。 如果并发级别是16:
那么sshift计算结果就是4.
ssize的结果是等于concurrencyLevel的。
继续看下一段代码:
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;这里segmentShift 的源码注释是:Shift value for indexing within segments.
中文意思是移动的位数用于段内索引。
segmentMask 注释是:Mask value for indexing into segments. The upper bits of a key’s hash code are used to choose the segment.
中文意思是:用于索引到段,hashcode值的高比特用于选择段。
这里按照默认计算出
segmentShift = 28
segmentMask = 15
initialCapacity 和MAXIMUM_CAPACITY比较,MAXIMUM_CAPACITY的注释是:
The maximum capacity, used if a higher value is implicitly
specified by either of the constructors with arguments. MUST
be a power of two <= 1<<30 to ensure that entries are indexable
using ints.
最大的容量,是哪个容量呢?具体没说,一会看。这个容量的值必须是2的N次幂才可以,且不能大于1<<30.
这里initialCapacity 使用了默认值16.
因此变量c的计算结果应该是1
继续往下看代码:
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;这里cap等于2,MIN_SEGMENT_TABLE_CAPACITY 的意思说每个segment最小应该有的entry数量。这里初始化了segment[0]中的两个Entry对象,并创建了ssize个segment,也就是和并发级别数量一样的segment。
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
this.segments = ss;到这里我们只是看到了每个值的计算过程,但是为什么这么计算,我们不知道,计算的结果做什么用呢?主要用到根据hash值计算段索引了。
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key.hashCode());
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}从这里看,map对象的push操作,其实是将key的hashcode进行hash散列一次,然后根据上面构造函数的初始化值进行查找段,使用段的接口将key-value的值存放到段中的Entry数组中了。构造函数分析到这里可以看出,这里主要矛盾就是hash函数的构造,如果将key值的hashcode值均匀散列到数组下标上。
下一步分析segment对象:这个segment就和hashmap中的entries数组原理差不多了。这里有一个主要的域字段:transient volatile HashEntry
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;可以看到hash,key,next引用都是final类型不可变的。因此一旦创建了entry对象,那么就不能再变化了。因此如果多个key值hash到一个位置上,需要增加,删除操作的时候,就不能直接改变next,针对添加操作,需要将添加的元素放在entry 链表的头部,同时设置next对象为之前链表的头部对象。如果是删除操作,那么需要复制这个删除对象之前所有的entry对象。
segment对象继承了ReentrantLock 锁对象,这个对象用于锁定segment的操作。因此真正的锁是加在segment对象上,因此有多少个segment对象,就能同时支持多少个线程并发执行。














 1300
1300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









