







之前都只是使用urllib和urllib2这两个类库,接下来要发掘更多好用的工具了,比如这个xpath,对于分析HTML的网页结构实在是太方便。
http://blog.csdn.net/freeking101/article/details/52614291
http://www.w3school.com.cn/xpath/index.asp
大家可以参考一下这个网址学习一下xpath的使用方法,好了下面就说回我的代码实现
首先观察一下马蜂窝的游记HTMLsource
图片1
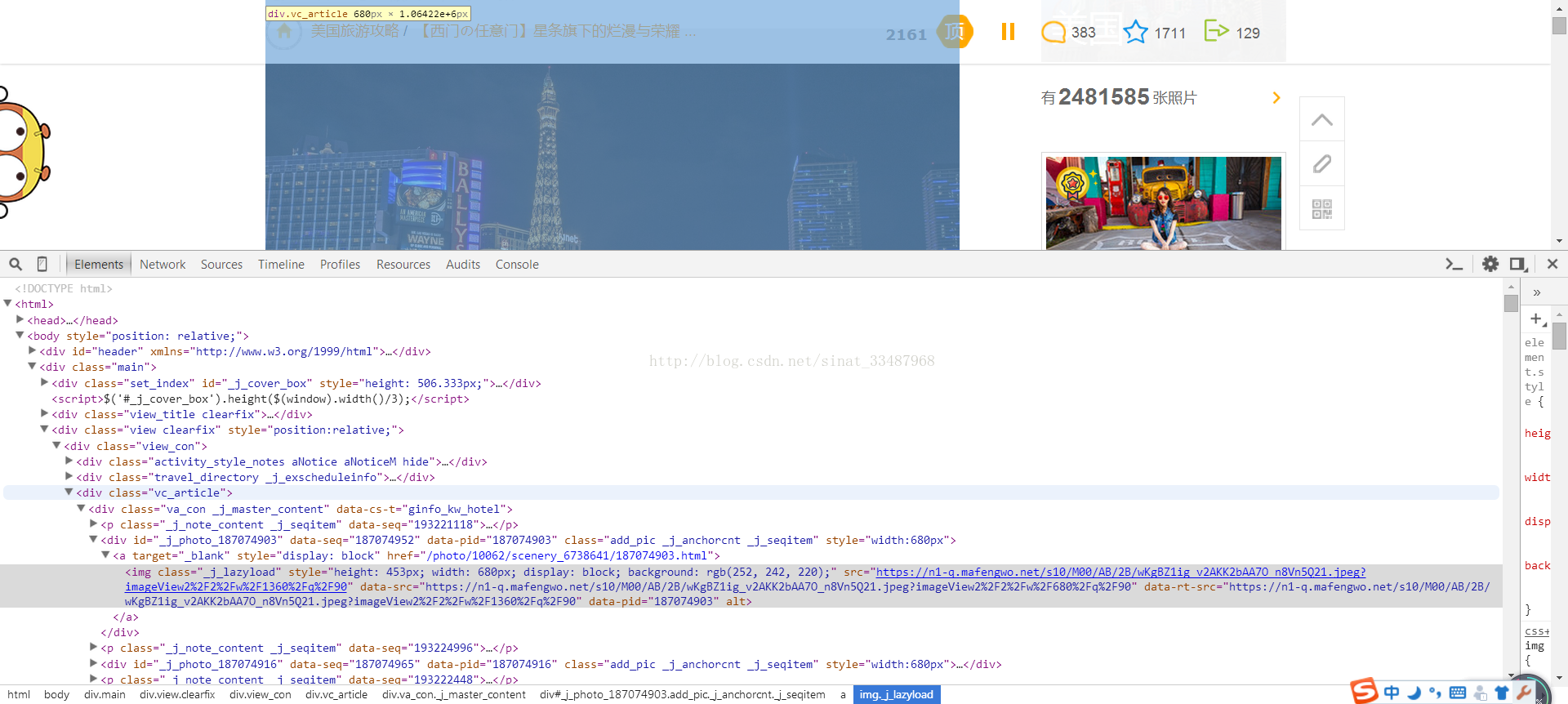
然后就可以写出获得图片地址和保存图片的函数
def writePhoto(soup,path):
print u"开始保存图片"
img=soup.xpath('//img/@data-src')
total_img=0
for myimg in img:
total_img += 1
print myimg
urllib.urlretrieve(myimg,path+'%s.jpg'%total_img)
print u"已经保存第",total_img,u"张照片"
print u"总共保存第",total_img,u"张照片&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3616
3616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









