







标签(空格分隔): 王小草Tensorflow笔记
笔记整理者:王小草
笔记整理时间:2017年2月25日
官方文档原文地址:https://www.tensorflow.org/get_started/mnist/pros
官方文档最近更新时间:2017年2月15日
欢迎机器学习,深度学习爱好者一起交流。
也欢迎关注我的喜马拉雅账号:”好吧我真的叫王草”。分享由集智俱乐部推出的两本好书:《科学的极致:漫谈人工智能》与《走进2050,注意力,互联网与人工智能》。
在上一篇笔记中介绍了用softmax去识别手写数字的图片,正确率只有92%。这篇笔记,仍然聚焦于同一个案例,但使用一个更复杂一点的模型来做训练:卷积神经网络(简称CNN)。从而正确率会到达99.2%。
关于卷积神经网络CNN在我之前的深度学习系列笔记中有详细介绍,欢迎阅读,在这里就不再赘述了。
1.数据准备
前面的过程与上一篇笔记一样:
1.导入tensorflow包
2.下载数据
3.创建会话
4.为输入的样本特征x与标签y建立占位符
代码如下,不再解释,不懂的可以看上一篇笔记
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 加载数据
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
# 创建会话
sess = tf.InteractiveSession()
# 设置占位符
x = tf.placeholder(tf.float32, shape=[None, 784])
y_ = tf.placeholder(tf.float32, shape=[None, 10])2.初始化参数的方法封装
参数在训练中是会不断变更与优化的,所有为参数创建一组变量。因为在神经网络中每层都会有参数,一个一个去创建显然不科学,最好的方式是写一个function去封装创建参数变量的过程。在神经网络里涉及的参数仍然是2类:w,b.
# 创建w参数
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# 创建b参数
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)以上代码中,tf.truncated_normal函数使得w呈正太分布,
stddev设置标准差为0.1。也就是说输入形状大小shape,输出标准差为0.1的正太分布的随机参数作为权重变量矩阵
对于参数b,使用了tf.constant()来创建一组指定大小的常数,常数值为0.1
在方法def中都分别初始化了这两个参数。
注意:在初始化参数的时候,也不是随便给一个值作为初始值的哈。模型对初始的参数是很敏感的,如果参数都很大,那么经过wx+b这个线性函数时,输出的值也会很大,若是经过tanh这个激活函数,输出的结果绝对值都几乎接近于1,也就是说每个神经元的输出都几乎相同,这完全违背了神经网络的初衷,事实上我们希望每个神经网络都能去学习一个不同的特征,他们的输出值应该是有差异的。另一方面,如果w值设置地太小了,经过线性函数wx+b的时候,wx可以忽略不计,于是线性函数的输出都约等于b,经过激活函数后的输出也几乎相同,又造成了神经元彼此雷同的尴尬局面呢。
对于参数b, 因为这里要使用的是RELU这个激活函数,所以最好设置成小一点的正数,从而来避免“神经元死亡”。RELU激活函数是,当输入大于0,则输出=输入值;若输入值小于0,则输出=0,想想,要是b是太大的负数,线性函数的输出也很有可能是负数,经过RELU之后就都变成0了。。。
3.创建卷积层与池化层的方法封装
Tensorflow也在卷积层与池化层给了很多灵活的操作。卷积层与池化层都需要设置一些超参数,比如步长,窗口大小,补全的边界等。那么我们该如何去定义边界,如何去选择步长呢?在这里我们选择使用步长为1,用0补全边界,故卷积层的输出与输入的数据大小是一致的。
在池化层中,使用2*2的窗口选取窗口中的最大值作为输出。
同样,一个神经网络会有很多个卷积层与池化层,我们不可能去一层一层写,为了使代码更简洁,最好将卷积层与池化层的创建封装成两个方法。如下:
# 创建卷积层,步长为1,周围补0,输入与输出的数据大小一样(可得到补全的圈数)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# 创建池化层,kernel大小为2,步长为2,周围补0,输入与输出的数据大小一样(可得到补全的圈数)
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
4.建立第一组卷积层与池化层
一般卷积层之后会跟一个池化层,所以我们将他们的组合看做一个整体。
这层卷积层总共设置32个神经元,也就是有32个卷积核去分别关注32个特征。窗口的大小是5×5,所以指向每个卷积层的权重也是5×5,因为图片是黑白色的,只有一个颜色通道,所以总共只有1个面,故每个卷积核都对应一组5*5 * 1的权重。
因此w权重的tensor大小应是[5,5,1,32]
b权重的tensor大小应是[ 32 ]
初始化这两个权重:
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])记得我们做softmax regression的时候,是将28 * 28的图像数组铺平成了1 * 784的向量,在CNN中,我们需要将其又组合成28 * 28,因为只有一个颜色通道,确切的来说应该是28 * 28 * 1的数组,-1表示取出所有的数据。
x_image = tf.reshape(x, [-1,28,28,1])接下来,将权重w与样本特征x放进卷积层函数中做卷积运算,然后加上偏置项b。将线性输出进入relu激活函数,激活函数的输出就是卷积层的最终输出,输出tensor的大小仍然是28*28
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)卷积层的输出就是接下去池化层的输入,池化层的窗口大小为2*2,故输入的28*28,就变成了输出的14*14大小了
h_pool1 = max_pool_2x2(h_conv1)5.建立第二组卷积层与池化层
第二层卷积层中,窗口大小仍然是5 * 5, 神经元的个数是64,因为上一层的神经元个数是32,所以这一次的参数w的大小是[5,5,32,64],参数b的大小是[ 64 ]
# 初始化参数
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
# 创建卷积层
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# 创建池化层
h_pool2 = max_pool_2x2(h_conv2)经过卷积层tensor的大小是14 * 14,经过池化层tensor的大小变成了7 * 7
6.创建全连接层
在经过一组一组的卷积+池化层之后呢,往往会以一个全连接层结尾.
在全连接层设置1024个神经元,图像目前图像数据的大小是 7 * 7,对于全连接层来说需要将图像数据再次铺平成1 * 49的向量,因为上一层有64个神经元,故铺平之后是 7 * 7 * 64 大小的向量。
# 初始化权重
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
# 铺平图像数据
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
# 全连接层计算
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)为了避免过拟合,这里在全连接层使用dropout方法,就是随机地关闭掉一些神经元使模型不要与原始数据拟合得辣么准确。
# keep_prob表示保留不关闭的神经元的比例。
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)keep_prob表示保留不关闭的神经元的比例。
7. 创建输出层:softmax层
因为是多分类模型,在全连接后面再添加一层softmax层~
总共类别是10,故最后一层为10个神经元
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc28.训练与评估模型
多光鲜亮丽也好多高深莫测也好,最终还是用准确率来一较高下的 。因此现在我们要按照上面创建好的模型来训练,并且评估这个模型预测的好坏。
# # 1.计算交叉熵损失
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
# # 2.创建优化器(注意这里用 AdamOptimizer代替了梯度下降法)
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# # 3. 计算准确率
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# # 4.初始化所有变量
sess.run(tf.global_variables_initializer())
# # 5. 执行循环
for i in range(2000):
# 每批取出50个训练样本
batch = mnist.train.next_batch(50)
# 循环次数是100的倍数的时候,打印东东
if i % 100 == 0:
# 计算正确率,
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_pro: 1.0})
# 打印
print "step %d, training accuracy %g" % (i, train_accuracy)
# 执行训练模型
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_pro: 0.5})
# 打印测试集正确率
print "test accuracy %g" % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_pro: 1.0
})
官方文档上做的是20000次循环(大概半个小时),我为了节约时间自己运行的时候设置了循环2000次,每循环100次的时候,会打印出训练集的误差。打印结果如下:
step 0, training accuracy 0.1
step 100, training accuracy 0.84
step 200, training accuracy 0.9
step 300, training accuracy 0.86
step 400, training accuracy 0.98
step 500, training accuracy 0.94
step 600, training accuracy 0.98
step 700, training accuracy 0.96
step 800, training accuracy 0.9
step 900, training accuracy 1
step 1000, training accuracy 0.94
step 1100, training accuracy 0.94
step 1200, training accuracy 0.98
step 1300, training accuracy 1
step 1400, training accuracy 0.98
step 1500, training accuracy 0.94
step 1600, training accuracy 0.94
step 1700, training accuracy 0.94
step 1800, training accuracy 0.96
step 1900, training accuracy 0.98在最后,会打印出测试集的正确率:
test accuracy 0.9763可以发现用卷积神经网络做这次分类,正确率其实是挺高的,在0.976左右,我这边设置的循环次数是2000,在官网上设置的是20000,正确率可以高高达0.99+,是不是很牛逼哄哄呢~
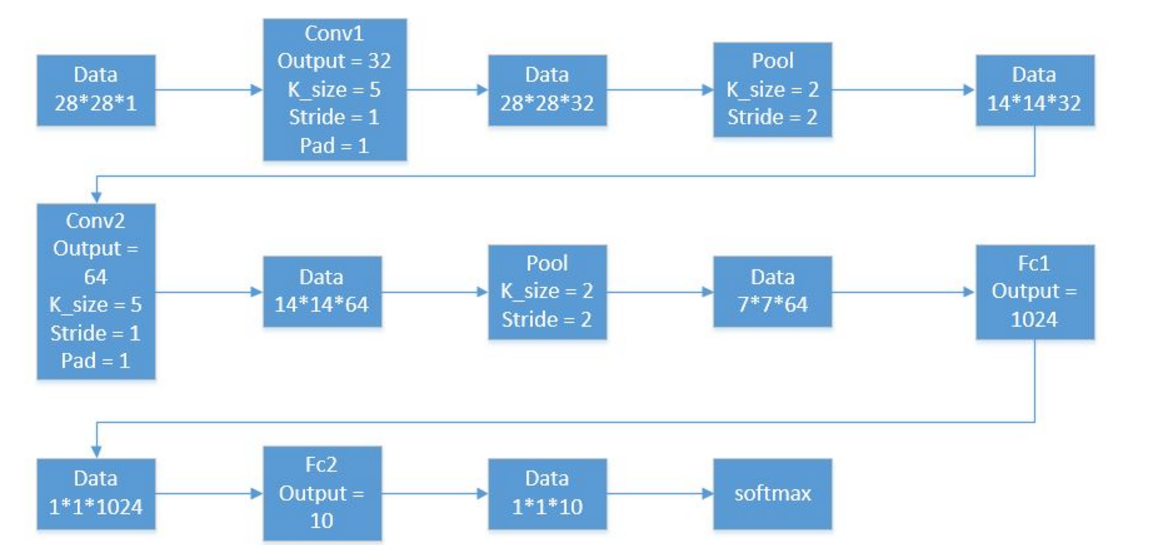
其实我觉得要用tensorflow实现神经网络的运算也许不难,难处应是在对卷积神经网络中各类型的层级的运作理解,这样才会知道每层的计算需要多少维度的权重,每层的输入输出是什么样的数据,理解整个卷积神经网络的每一步结构才能真正理解整个程序的运作,也才能灵活地使用tensorflow提供的各自函数与平台。下面这幅图是我在某个博客上截取的,描述的就是本文案例的整个过程,非常有助于理解,在此分享给大家。
完整代码如下:
#!/usr/bin/python
# -*- coding:utf-8 -*-
from tensorflow.examples.tutorials.mnist.input_data import *
import tensorflow as tf
# 读取数据集,read_data_sets是一个已经封装好的方法,会去直接下载数据并且做预处理
mnist = read_data_sets("MNIST_data/", one_hot=True)
# # 定义数据,设置占位符
# 设置特征与标签的占位符,特征集是n×784维,标签集维n×10维,n是可以调节的
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder("float", [None, 10])
# 设置dropout的占位符,dropout用于防止过拟合
keep_pro = tf.placeholder("float")
# 将平铺的特征重构成28×28的图片像素维度,因为使用的是黑白图片,所以颜色通道维1,因为要取出所有数据,所以索引维-1
x_image = tf.reshape(x, [-1, 28, 28, 1])
# # 定义函数以方便构造网络
# 初始化权重,传入大小参数,truncated_normal函数使得w呈正太分布,
# stddev设置标准差为0.1。也就是说输入形状大小,输出正太分布的随机参数作为权重变量矩阵
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# 初始化偏执项,传入矩阵大小的参数,生成该大小的值全部为0.1的矩阵
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 定义卷基层,步长为1,周围补0,输入与输出的数据大小一样(可得到补全的圈数)
def conv2d(a, w):
return tf.nn.conv2d(a, w, strides=[1, 1, 1, 1], padding='SAME')
# 定义池化层,kernel大小为2,步长为2,周围补0,输入与输出的数据大小一样(可得到补全的圈数)
def max_pool_2x2(a):
return tf.nn.max_pool(a, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# # 进入卷积层与池化层1
# 初始化权重,传入权重大小,窗口的大小是5×5,所以指向每个卷积层的权重也是5×5,
# 卷积层的神经元的个数是32,总共只有1个面(1个颜色通道)
w_conv1 = weight_variable([5, 5, 1, 32])
# 32个神经元就需要32个偏执项
b_conv1 = bias_variable([32])
# 将卷积层相对应的数据求内积再加上偏执项的这个线性函数,放入激励层relu中做非线性打转换,输出的大小是28×28×32
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1) + b_conv1)
# 将卷积层输出的数据传入池化层,根据函的设定,窗口大小维2×2,步长为2,输出的大小就降到来14×14×32
h_pool1 = max_pool_2x2(h_conv1)
# # 进入卷积层与池化层2
# 第2层卷积层由64个神经元,1个神经元要初始化的权重维度是5×5×32
w_conv2 = weight_variable([5, 5, 32, 64])
# 偏执项的数目和神经元的数目一样
b_conv2 = bias_variable([64])
# 将池化层1的输出与卷积层2的权重做内积再加上偏执项,然后进入激励函数relu,输出维度为14×14×64
h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2) + b_conv2)
# 进入池化层,输出减半为7×7×64
h_pool2 = max_pool_2x2(h_conv2)
# # 进入全连接层1
# 初始化全链接层的权重,全了链接层有1024个神经元,每个都与池化层2的输出数据全部连接
w_fc1 = weight_variable([7*7*64, 1024])
# 偏执项也等于神经元的个数1024
b_fc1 = bias_variable([1024])
# 将池化层的输出数据拉平为1行7×7×64列打矩阵,-1表示把所有都拿出来
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
# 全连接计算,线性运算后再输入激励函数中,最后输出1024个数据
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, w_fc1) + b_fc1)
# 使用dropout防止过拟合
h_fc1_drop = tf.nn.dropout(h_fc1, keep_pro)
# # 进入全连接层2
# 初始化权重,全连接层2有10个神经元,上一层打输入是1024
w_fc2 = weight_variable([1024, 10])
# 偏执项为10
b_fc2 = bias_variable([10])
# 全连接的计算,然后再过一个softmax函数,输出为10个数据(10个概率)
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, w_fc2) + b_fc2)
# # 损失函数最小的最优化计算
# 交叉熵作为目标函数计算
cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv))
# 目标函数最小训练模型,估计参数,使用的是ADAM优化器来做梯度下降
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 计算预测正确的个数,tf.argmax是寻找一个tensor中每个维度的最大值所在的索引
# 因为类别是用0,1表示的,所以找出1所在打索引就能找到数字打类别
# tf.equals是检测预测与真实的标签是否一致,返回的是布尔值,true,false
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
# 计算正确率,用tf.cast来将true,false转换成1,0,然后计算正确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
# # 创建会话,初始化变量
sess = tf.InteractiveSession()
sess.run(tf.initialize_all_variables())
# # 执行循环
for i in range(2000):
# 每批取出50个训练样本
batch = mnist.train.next_batch(50)
# 循环次数是100的倍数的时候,打印东东
if i % 100 == 0:
# 计算正确率,
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_pro: 1.0})
# 打印
print "step %d, training accuracy %g" % (i, train_accuracy)
# 执行训练模型
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_pro: 0.5})
# 打印测试集正确率
print "test accuracy %g" % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_pro: 1.0
})














 1175
1175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









