







大数据学习之大数据概述
1.数据单位
8 bit = 1 Byte 一字节
1024 B = 1 KB (KiloByte) 千字节
1024 KB = 1 MB (MegaByte) 兆字节
1024 MB = 1 GB (GigaByte) 吉字节
1024 GB = 1 TB (TeraByte) 太字节
1024 TB = 1 PB (PetaByte) 拍字节
1024 PB = 1 EB (ExaByte) 艾字节
1024 EB = 1 ZB (ZetaByte) 皆字节
1024 ZB = 1 YB (YottaByte) 佑字节
1024 YB = 1BB(Brontobyte)珀字节
1024 BB = 1 NB (NonaByte) 诺字节
1024 NB = 1 DB (DoggaByte)刀字节
2.数据类型:结构化,非结构化
一类信息能够用数据或统一的结构加以表示,我们称之为结构化数据,如数字、符号;
而另一类信息无法用数字或统一的结构表示,如文本、图像、声音、网页等,我们称之为非结构化数据。结构化数据属于非结构化数据,是非结构化数据的特例。
3.什么是大数据,4个v?
大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)
4.工作流程
采集数据—预处理ET—分析——显示
如图:
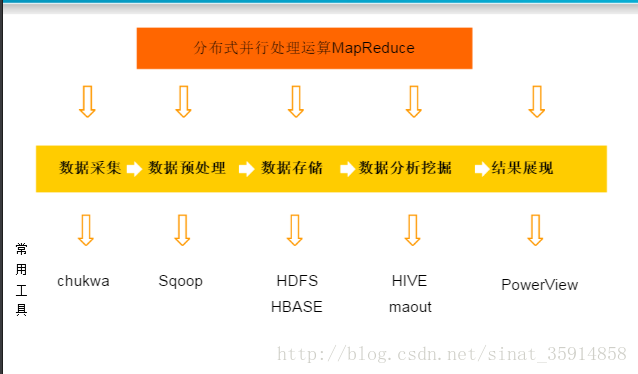
5.计算模式
简述:
是指根据大数据的不同数据特征和计算特征,从多样性的大数据计算问题和需求中提炼并建立的各种高层抽象(Abstraction)和模型(Model)。传统的并行计算方法主要从体系结构和编程语言的层面定义了一些较为底层的抽象和模型,但由于大数据处理问题具有很多高层的数据特征和计算特征,因此大数据处理需要更多地结合其数据特征和计算特性考虑更为高层的计算模式
计算工具

6.分布式系统简述
分布式系统(distributed system)是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。内聚性是指每一个数据库分布节点高度自治,有本地的数据库管理系统。透明性是指每一个数据库分布节点对用户的应用来说都是透明的,看不出是本地还是远程。在分布式数据库系统中,用户感觉不到数据是分布的,即用户不须知道关系是否分割、有无副本、数据存于哪个站点以及事务在哪个站点上执行等。
7.商业化CDH
(1)CDH:全称Cloudera’s Distribution Including Apache Hadoop 是hadoop的一个发行版本
(2)CDH的优点
• 版本划分清晰
• 版本更新速度快
• 支持Kerberos安全认证
• 文档清晰
• 支持多种安装方式(Cloudera Manager方式)
(3)CDH下载地址
• CDH5.4
http://archive.cloudera.com/cdh5/
•Cloudera Manager5.4.3:
http://www.cloudera.com/downloads/manager/5-4-3.html
8.分布式领域CAP理论
- Consistency(一致性), 数据一致更新,所有数据变动都是同步的,即在事务开始或结束时,数据库应该在一致状态;
- Availability(可用性), 好的响应性能;
- Partition tolerance(分区容错性) 可靠性;
- PS:任何分布式系统只可同时满足二点,没法三者兼顾。
9.hadpoo技术栈
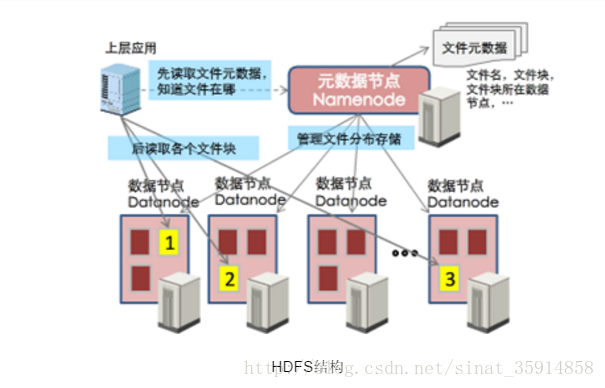
- HDFS:Hadoop Distributed File System
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。结构如图:
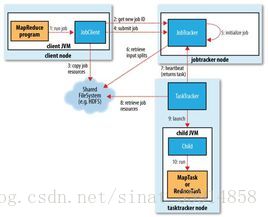
- MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念”Map(映射)”和”Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
具体参看百科 - Hive:hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析
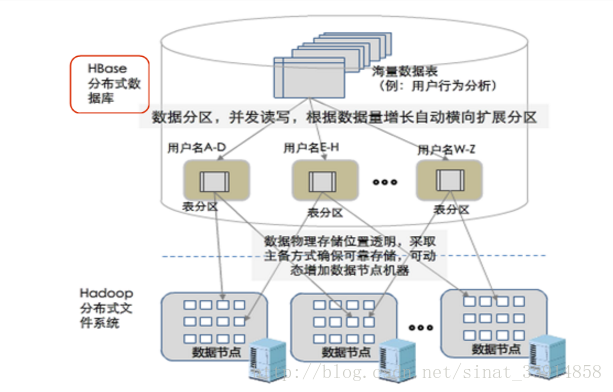
具体参看百科 HBase:HBase是一个分布式的、面向列的开源数据库,HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。结构如图:
Sqoop:一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。结构如图:














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









