







任务与代码:
输入一个整数m,表示A链表的长度,再输入m个数作为A链表中的m个数据元素,建立链表A,其头指针为heada。输入一个整数n,表示B链表的长度,再输入n个数表示B链表中的n个数据元素,建立链表B,其头指针为headb。输入i、len、j,将要从单链表A中删除自第i个元素起的共len个元素,然后将单链表A插入到单链表B的第j个元素之前。最后输出操作后的链表B。
11
13 5 14 62 3 43 71 5 72 34 5 (11个数构成链表A)
15
5 20 3 53 7 81 5 42 6 8 4 6 9 10 23(15个数构成链表B )
1 3 5(从单链表A中删除自第1个元素起的共3个元素,然后将单链表A插入到单链表B的第5个元素之前
输出:
5 20 3 53 62 3 43 71 5 72 34 5 7 81 5 42 6 8 4 6 9 10 23
#include<stdio.h> #include<malloc.h> struct node { int data; struct node *next; }; struct node *creat(int m) { struct node *head,*p,*q; head=(struct node *)malloc(sizeof(struct node)); q = head; while(m--) //建立m+1个结点的链表,头结点的数据域存放的是随机数 { p=(struct node *)malloc(sizeof(struct node)); scanf("%d",&p->data); q->next = p; q = p; } q->next = NULL; return head; } int main() { int i,len,j; int m,n; struct node *heada,*headb,*p,*q; //创建链表 scanf("%d",&m); heada = creat(m); scanf("%d",&n); headb = creat(n); scanf("%d%d%d;",&i,&len,&j); //删除结点 p = q = heada; while(--i) //循环i-1次,p,q出现在待删结点前的位置 { p = p->next; q = q->next; } while(len--) //循环len次 { q = q->next; //q出现在最后一个待删结点的位置 } p->next = q->next; //更改待删的前一个结点的地址域使其指向最后一个待删结点之后的结点地址 while(q->next != NULL) q = q->next; //合并链表 p=headb; while(--j) p = p->next; //从头结点遍历到链表B需要更改地址域的结点 q->next = p->next; //更改待插'结点'的地址域 p->next = heada->next; //更改待插'结点'前一个结点的地址域 q = headb->next; while(q != NULL) //遍历合并后的链表 { printf("%d ",q->data); q = q->next; } return 0; }
分析过程:
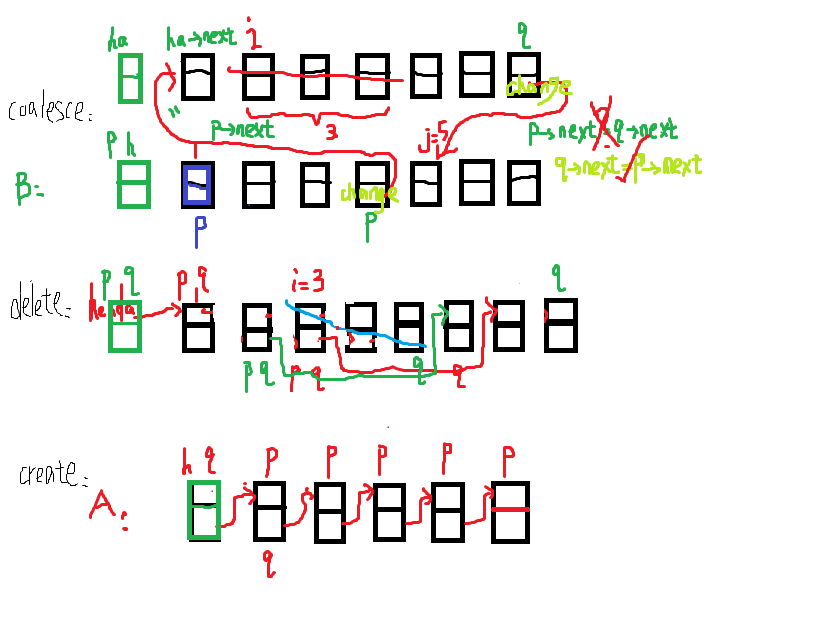
Q&A:
Q:为什么多建建立m+1个结点的链表,头结点的数据域存放的是无效的数据?
A:为了不单独考虑插入结点是首结点,删除结点也有首结点的情况。














 1211
1211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









