




 本文深入分析了ICTCLAS分词系统的词典结构,介绍了词典加载到内存的过程,以及如何通过二进制读取方式高效访问。详细探讨了词典数据块、词项数组、词频、词内容长度和句柄等关键元素,揭示了词典文件的组织形式及其在内存中的表示。
本文深入分析了ICTCLAS分词系统的词典结构,介绍了词典加载到内存的过程,以及如何通过二进制读取方式高效访问。详细探讨了词典数据块、词项数组、词频、词内容长度和句柄等关键元素,揭示了词典文件的组织形式及其在内存中的表示。
ICTCLAS的词典结构是理解分词的重要依据,通过这么一个数据结构设计合理访问速度高效的词典才能达到快速准备的分词的目的。
通过阅读和分析源代码,我们可以知道,是程序运行初,先把词典加载到内存中,以提高访问的速度。源代码在Result.cpp的构造函数CResult()内实现了词典和分词规则库的加载。如下代码所示:
CResult::CResult()
{
……
m_dictCore.Load("data//coreDict.dct");
m_POSTagger.LoadContext("data//lexical.ctx");
……
}
我们再跳进Load方法具体分析它是怎样读取数据词典的,看Load的源代码:
bool CDictionary::Load(char *sFilename,bool bReset)
{
FILE *fp;
int i,j,nBuffer[3];
//首先判断词典文件能否以二进制读取的方式打开
if((fp=fopen(sFilename,"rb"))==NULL)
return false;//fail while opening the file
//为新文件释放内存空间
for( i=0;i<CC_NUM;i++)
{//delete the memory of word item array in the dictionary
for( j=0;j<m_IndexTable[i].nCount;j++)
delete m_IndexTable[i].pWordItemHead[j].sWord;
delete [] m_IndexTable[i].pWordItemHead;
}
DelModified();//删除掉修改过的,可以先不管它
//CC_NUM:6768,应该是GB2312编码中常用汉字的数目6763个加上5个空位码
for(i=0;i<CC_NUM;i++)
{
//读取一个整形数字(词块的数目)
fread(&(m_IndexTable[i].nCount),sizeof(int),1,fp);
if(m_IndexTable[i].nCount>0)
m_IndexTable[i].pWordItemHead=new WORD_ITEM[m_IndexTable[i].nCount];
else
{
m_IndexTable[i].pWordItemHead=0;
continue;
}
j=0;
//根据前面读到的词块数目,循环读取一个个词块
while(j<m_IndexTable[i].nCount)
{
//读取三字整数,分别为频度(Frequency)/词内容长度(WordLen)/句柄(Handle)
fread(nBuffer,sizeof(int),3,fp);
m_IndexTable[i].pWordItemHead[j].sWord=new char[nBuffer[1]+1];
//读取词内容
if(nBuffer[1])//String length is more than 0
{
fread(m_IndexTable[i].pWordItemHead[j].sWord,sizeof(char),nBuffer[1],fp);
}
m_IndexTable[i].pWordItemHead[j].sWord[nBuffer[1]]=0;
if(bReset)//Reset the frequency
m_IndexTable[i].pWordItemHead[j].nFrequency=0;
else
m_IndexTable[i].pWordItemHead[j].nFrequency=nBuffer[0];
m_IndexTable[i].pWordItemHead[j].nWordLen=nBuffer[1];
m_IndexTable[i].pWordItemHead[j].nHandle=nBuffer[2];
j+=1;//Get next item in the original table.
}
}
fclose(fp);
return true;
}
看完上面的源代码,词典的结构也应该基本清楚了,如下图一所示:
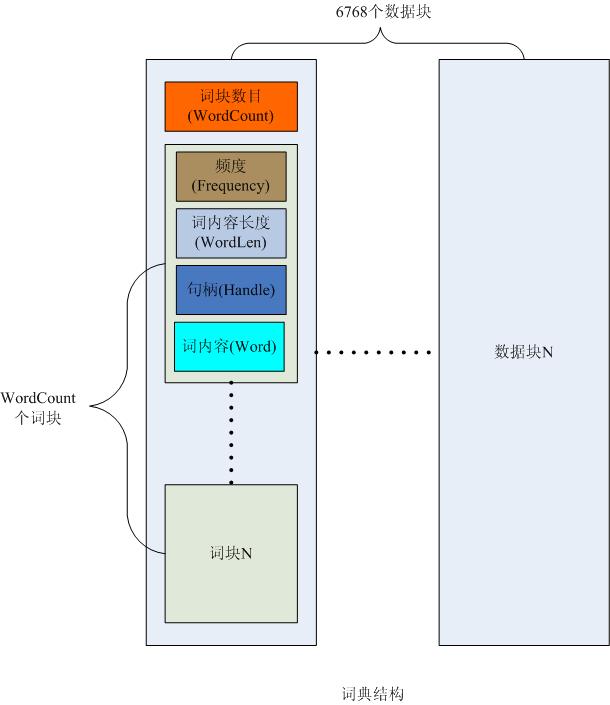
图一
修改表的数据结构和上图差不多,但是在词块数目后面多了一个nDelete数目,即删除的数目,数据结构如下图二所示:
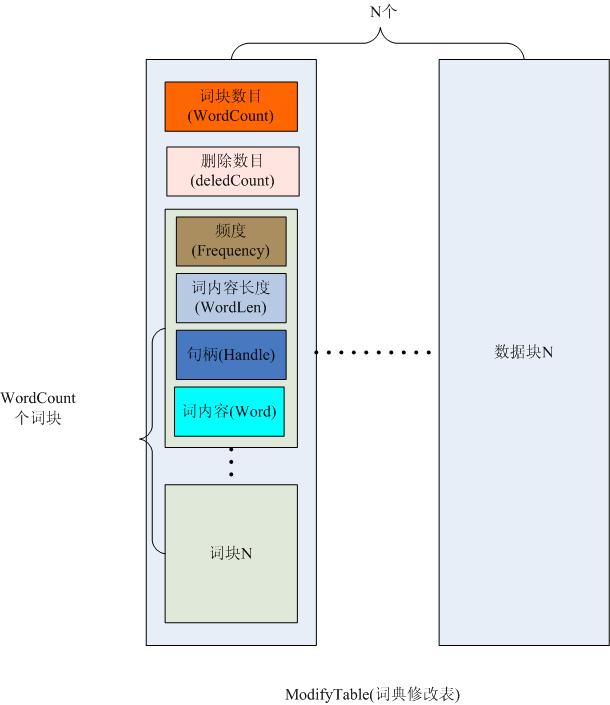
&nbs
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









