








背景描述:
假设有99999条数据需要往本地下载,而此时受限于网速,服务器压力等问题,就算此时本地系统已经优化的很好了(单次数据库数据同步能力100条1s~5s,1000条20s~30s等等,按照(总数÷时间=效率)来计算的话,不能难发现数据量越大,收益越大),但是从服务器向本地下载就不如人意(单次数据下载能力100条50s,1000条90s等等,按照(总数÷时间=效率)来计算的话,不难发现,总数越大,效率越大)。
优化建议:
1.从服务器方面:优化服务器的并发量和响应速度,但是,此时要考虑到,服务承载的是整个所有的用户,而且这个用户还是一个不断增加的过程,此时服务器能做的就是添加分布式缓存,以减小对于数据库的开销。但是。往往在这个时候我们要考虑的是,在钱、人、环境限制的情况下,服务器端要求的是稳定。所以,我们就想到了客户端的处理模式,如下↓。
2.从客户端方面:优化客户端对数据处理的逻辑关系,优化业务的处理流程。此时我已经采用的泛型数据处理,来增加对于数据整体逻辑的处理效率。而且对于数据库的操作我也是用了大批量操作对象Adapter适配器来进行协议数据操作。但是问题还是,受限于网速和服务器压力,如何能够快速的将远程的数据下载到本地呢?此时,受他人点波想到了多线程,还有线程之间的通信机制,来进行处理。
着手实现:
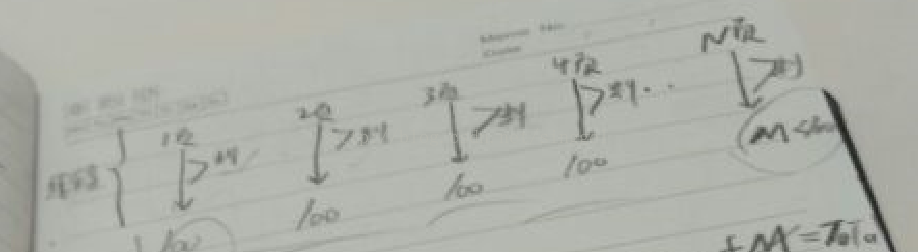
如图中所示,同时开辟多个线程,(比如我们的目的是为了达到将好几页的数据下载到本地),此时要着手保证的是,每次进去哪个线程,要完成怎么样的任务,任务的标准是什么,完成怎么处理,没完成怎么处理,做好判断,与此同时线程开多少也是有根据的,要根据当前CPU和内存的性能,一般来说是两倍,不要想着达到CPU和内存的极限,这样机器反而会更慢,会起到相反的效果。

上一步说过了来利用多线程进行处理大数据量的问题,也已经说了线程的数量不是说你想开多少就开多少,数量确定之后,每个线程做自己的任务,根据任务的标准进行判断任务的完成情况,这个时候要考虑的是,已经先完成任务的线程此时是空闲出来的,这个时候呢,就要处理剩下的其它任务,此时就要判断的是空余出来的多个线程以及多个没有完成任务的安排问题。怎么做才能够使他们避免出现线程的不充分利用,而且剩余任务的正确处理不出现死锁等一系列问题
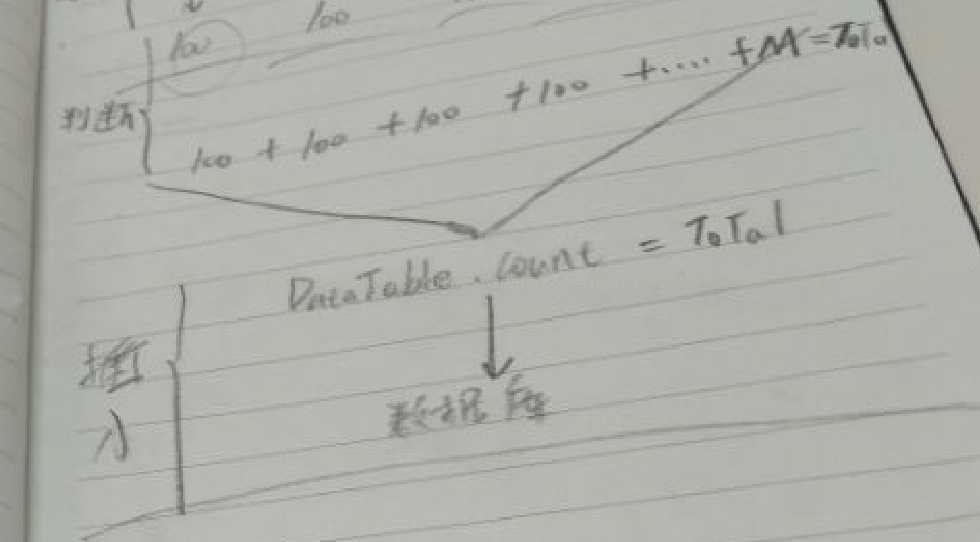
当所有的线程跑完之后,需要进行的就是判断所有的线程是否已经完成任务,当所有的线程完成任务的标准是什么,而且当所有的线程完成任务之后线程是否都已经全部进行了处理,以免浪费内存和CPU的占用。这个时候在系统本地要做的就只需要将数据进行处理。
以上是我遇到当前问题的时候的解决办法和路径,代码正在够写之中,过段时间再放上相关的代码解析。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









