







1、Adaboost
我们先不谈数学模型,先说一下adaboost的原理,这样更方便理解
举个例子,我们说在一个班级上,我们给了十幅图片希望小朋友们可以学习出那些是苹果。
那第一个小朋友可能说苹果是圆的,按照这个规则我们分了一下发现确实可以把一部分苹果分出来,但是又有一些分错了,这时候老师把这些分错的图片放大,那下一个小朋友可能就会更加关注分错的那一部分图片,然后提出一个新的规则可能说苹果是红的。一次下去我们可以学习到很多的弱小的规则,每一次结合前面的规则都有所提升,那最后可以把苹果分出来很清楚,这就是adaboost的思想,每个同学都相当于一个弱小的分类器
gt
,老师就相当于一种算法来引导不同的弱分类器关注不同的方面(上一次分错的方面)
那么在adaboost算法中,我们给每一笔数据一个权重,也就是之前说的图片的大小。权重反应了分类器对这笔数据的关注程度。如果分类器在一笔权重很高的数据上犯了错误,那么就会有更高的错误损失得分。
从这个公式就可以看出我们为了最小化 Euin 就会避免权重高的点犯错误。
那么在adaboost中我们怎么样在每一轮改变数据权重的大小呢?
我们这里每一轮都要训练一个弱分类器 gt ,然后把很多个 gt 组合到一起构成一个强分类器,那么我们就希望每一个 gt 的差距越不同越好。因为如果大部分 gt 都差不多的话,那么组合起来的结果和一个 gt 没什么太大的差别,没有意义。
那么我们来看下面两个公式。
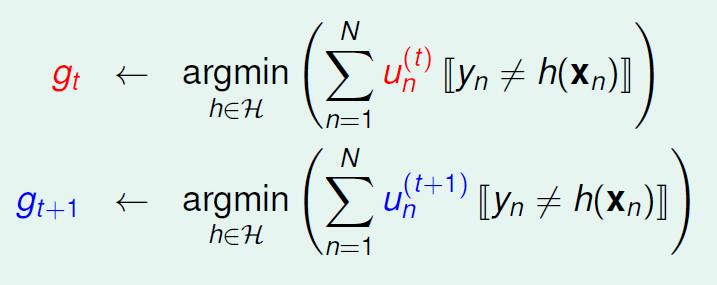
我们说
gt+1
与
gt
不一样,也就是说在训练
gt+1
的时候几乎不会选到
gt
,为什么不会选到
gt
因为,在第二个式子中,
gt
的效果几乎与乱猜没什么太大的差别。也就是在第二个式子中
gt
会造成几乎二分之一的错误率。
那么错误率是什么?
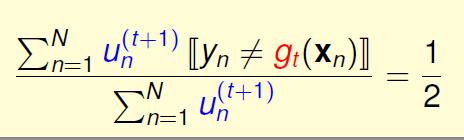
这个看着有点复杂啊,其实很容易理解,我们就是需要正确的点的权重和等于错误的点的权重和嘛。

举个例子就是

所以我们就有了权重的更新公式

对于错误的点,我们放大它的权重,对于正确的点我们缩小它的权重。
有了对每笔数据权重的变化的衡量,我们就可以训练出不同的 gt ,那么我们怎么把 gt 组合起来呢,每个 gt 的话语权应该是不一样的吧,毕竟如果 gt 它的错误率很小也就是 ϵt 很小的话,那么他应该有个较大的话语权。
所以 αt=ln(1−ϵtϵt−−−−√)
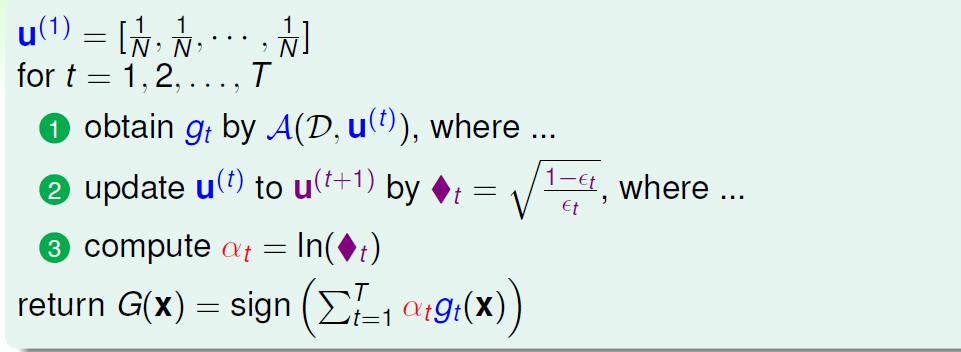
那么现在就有了adaboost 的算法了。

这里有一条结论说,我们的弱分类器只要比随机分类好一点点,那么 T=O(logN)
2、数学模型
adaboost的error function应该是
1N∑Ni=1e−ys
,s是什么,s就是各个分类器的权重累加
为什么是这个,是从数据权重的更新推导得来的。

那么我们要最优化我们的损失函数,这里用梯度下降的方法。梯度下降的方法说我们要在现有的位置找一个最好的方向使得我们的error function下降的最快。然后沿着这个方向下降一点点。
那么同样对应的,我们可以把我们的损失函数变换一下写法。
这里的h(x)就是我们要确定的第t个分类器 gt ,这里就感觉和梯度下降很像的,梯度下降也是在每一轮都加上一个方向,然后使得损失函数越来越小越来越好,那这里就是每一个分类器 gt 都让损失函数越来越小越来越好。
然后通过各种推导证明,就可以得出来 gt 其实就是我们算法中的base algorithm得出来的。因为后来推导发现要error function最小,其实就是在对于每一轮的 ut 来说 Eutin 最小。所以其实就是那个弱分类器算法确定了梯度下降的方向。
有了g(t)之后我们可以确定一个最优的
η
,就是说我们在
gt
方向上可以下降多少。最优化多少。这里确定很简单,就是一个偏导数等于零的计算。

这就是adaboost的数学模型。
gradient boost
那这里我们可以继续扩展一下。adaboost做二分类问题,所以他的error function 是
e−ys
,那我们其实可以把损失函数换成任意的一个,
只要是这种boost的模型,都可以用gradient的方法来最优化损失函数。
例如regression问题。它的 err(sn,yn)=(yn−sn)2 那我们就可以用gradient 的方法来优化它。具体写出来就是
直接将他泰勒展开:


这里就是各种变化,加上一个h(x)的平方是因为我们要限制h(x)的长度。最后得出来的结论就是,我们每一次选择 gt 的时候都是对上一次结果与真实结果的差,也就是余数做regression。也就是要在余数上,平方和最小。
那么我们就可以用cart回归树做这个拟合(regression)
最开始的时候余数就是 yn 本身。然后找一个最优的属性划分,使得两侧的真实值与各自平均值的差的平方和最小。然后求每个值的余数,进行下一次划分。
然后在确定权重,也就是每个
gt
的话语权。

这里还要做一次拟合。这不过这里面可以直接求导置零,求出最好的
η














 3680
3680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









