








JAVA NIO: 非阻塞(Non-blocking)服务器设计
JAVA NIO存在已经有很长时间了,也许你运用它已经到达炉火纯青的地步了,但是怎样用它来设计一个高并发的服务器,你有想法吗?
小弟第一次写,看到这篇文章时内心激动不已,内心一直告诉自己一定要转载出来让更多的人看到。错误肯定是有的,希望大家不吝赐教 (^_^)
原文作者: Jakob Jenkov
原文地址: http://tutorials.jenkov.com/java-nio/non-blocking-server.html
这篇是小弟对原文的一个意译
申明本文所有想法以及图片均来自 Jakob Jenkov
—————————–正文开始———————————-
即使对JAVA NIO non-blocking工作原理很了解(Selector, Channel, Buffer etc.),要设计一个非阻塞的服务器依然是很难的。和阻塞IO相比非阻塞IO有很多的挑战。本教程主要讨论设计非阻塞服务器面临的主要挑战,同时也描述一些潜在的解决方案。
找一个好的有关设计非阻塞服务器的资料是比较困难的。教程中提供的解决办法都是基于我本人的工作和想法。如果你有别的办法或者有更好的主意,我非常高兴听到!你可以给我发送邮件或者在Twitter上给我留言。
教程中描述的想法都是围绕JAVA NIO来设计的。我相信这些想法也能使用在那些拥有某种Selector-like(类似JAVA NIO中的Selector设计方法)构造的语言中。目前为止据我所知,那种构造都是有底层OS系统提供的,所以你可以利用这个机会在其它语言中试试。
非阻塞服务器 - GitHub 仓库
我创建了一个简单的项目用来验证自己的想法。
https://github.com/jjenkov/java-nio-server
(好戏开始了)
Non-blocking IO Pipelines 非阻塞IO管道
一个非阻塞IO管道是一条处理非阻塞IO的组件链(a chain of components)。使用一个非阻塞的方式进行读写操作,非阻塞IO管道的示意图:
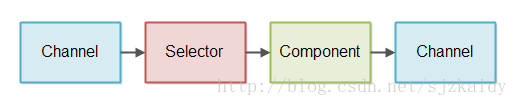
组件使用一个Selector来检查Channel中是否有数据要读取。然后组件读取数据又基于这些数据生成输出数据。输出的数据写再一次到Channel中。(一个神秘的组件 到底是何方神圣 ????????)
一个非阻塞管道并不一定需要同时支持执行读数据和写数据的两种操作。(它们分工很明确)有些管道只用来读取数据,有些管道只写数据。
上图中仅仅显示了一个组件。一个非阻塞管道在处理数据时可能包含不止一个组件。管道的长度依赖于它需要做的具体的事情。(简单说逻辑越复杂一般就越长)
非阻塞管道有可能同时从多个Channels中读取数据。比如,从多个SocketChannels中读取数据。
上图中的流程控制也是很简单的。组件通过Selector来初始化从Channel中读取数据。并不是像图显示的那样Channel把数据推送到Selector,然后到Selector中!
非阻塞IO管道 vs 阻塞IO管道
非阻塞IO管道 和 阻塞IO管道最大的不同的地方是它们怎样从底层Channel(Socket or File)中读取数据。
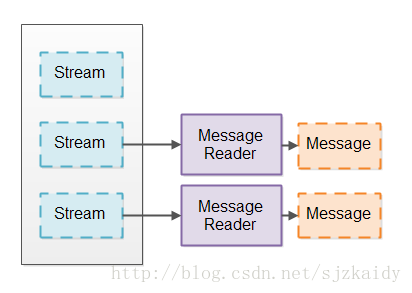
IO管道通常是从某些流(socket or file)中读取数据 然后 把数据分割成相关的消息(messages,消息出来了 ^_^)。这个类似于分词器把数据流分割成一块块数据用来进行解析。这里我们是把数据流分割成更大的消息。我把从流转化成消息的组件称为Message Reader(消息读者)。下面是Message Reader转化流的示意图:

阻塞IO管道使用InputStream类的接口一次一个字符的从底层的Channel中读取数据,这里可能阻塞一直到有数据可读。这个是阻塞式Message Reader的实现导致的。
对于流 使用阻塞IO接口简化了Message Reader的实现,阻塞式Message Reader永远不用处理从流那里没有读取到数据的情况,还有只从流那里读到部分数据,之后数据解析时需要进行恢复。
类似的 一个阻塞式的Message Writer(也是一个组件用来往流中写数据) 永远不用处理只有部分数据被写,剩下的写入在之后恢复进行的情况
阻塞式IO管道的弊端
虽然很容易实现一个阻塞式Message Reader,但是它有一个不幸的弊端那就是,它需要为每一个需要分割成消息的流提供一个独立线程。原因就是每一个流对应的IO接口一直被阻塞直到可以从中读取到数据。这意味着一个单独的线程不可能尝试着先读一个流,没有读到数据,然后又去读另外一个流。
在一个需要处理并发链接很大的服务器上,IO管道作为服务器的一部分。服务器需要为每一个接入的活链接分配一个线程。对于一个在任意时刻有几百个并发链接的服务器来说可能不是问题。但是对于一个拥有上百万并发链接的服务器来说,这类型的设计就捉襟见肘了。(我们来做一个算术)每一个线程需要320K(32位JVM) – 1024K(64位JVM) 内存用来分配栈(Stack)。所以1,000,000个线程将大约会花费1TB内存!!这还仅仅只是一个开始,因为数据处理过程中还需要为对象分配内存。
为了控制线程数量,许多服务器设计的时候使用线程池(e.g. 100个线程),一次从一个接入链接中读取数据。接入的链接被保存到队列中(队列 上场了),然后线程池以队列中保存的顺序一个一个读取数据。示意图:
然后,这种设计要求接入链接合理的发送数据。如果接入的链接可能很长一段时间不活动,当这样的线程数量非常多时可能阻塞线程池中所有的线程。这意味着服务器的响应变慢甚至无响应。
有些服务器通过弹性的控制线程池中的线程数量来尝试减轻这种问题(举个例子:tomcat配置中有两个参数:初始线程数量 和 最大线程数量)。举个例子,当线程池中的线程用光了,线程池就会创建更多的线程来处理。这种办法能够减轻上面的问题,但是毕竟能创建的线程数量是有上限的,所以对于1,000,000个慢的链接基本不能适应。
基础的非阻塞IO管道设计
非阻塞式IO管道能使用单线程从多个Stream中读取数据,这个要求Stream必须能切换到非阻塞模式。当处于非阻塞模式时,从Stream中读取数据可能返回0个或者更多的字节数据。返回0个字节表示没有读取到数据,返回1+以上的字节表示实际读取到了数据。
(当使用返回值时,程序员就需要判断了,到底有没有数据。简单的写IF else,但是不高明,请接着看)
为了避免判断Stream返回是否是0个字节,我们使用了JAVA NIO Selector(Selector登场了,注意这里我们是把判断逻辑委托给Selector了而不是不判断!!!)。Selector可以注册一个或者更多的SelectableChannel实例,我们调用Selector的select() 或 selectNow()方法来获取那些含有需要读取数据的SelectableChannel实例(调用者不用再关心0个字节的问题了),设计图如下:
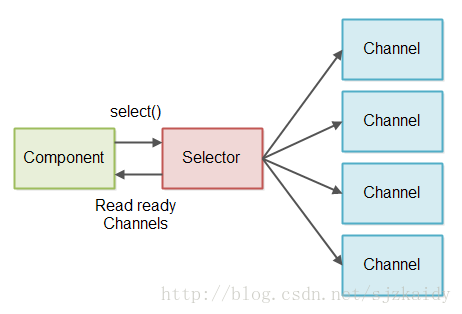
读取部分消息
当我们从SelectableChannel读取数据时,我们并不能肯定这个数据块包含的是不足一个消息或者是不止一个消息。(那么问题来了)一个数据块可能包含不完整的消息、完整的消息或者很多个消息,比如1.5倍或者2倍个消息。这种情况如图:
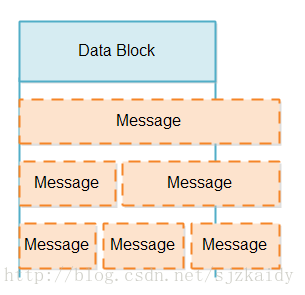
处理部分消息(不完整的消息)有两个挑战:
- 判断下你的数据块是否包含一个完整的消息
当剩下的消息到达之前,只有部分消息我们能做什么
判断是否包含完整的消息,我们同样委托给Message Reader,它检查数据块中是否包含有完整的消息,如果包含一个或者更多的完整消息,就把它们发送到管道的下个流程进行处理。判断是否包含完整消息这个过程是非常频繁的,所以这个过程要尽可能的快。(这里是一个瓶颈点)
对于不完整的消息当然要存储起来,等到Channel把剩下数据发送过来后再发送给下一个流程处理。
(数据 和 消息 不是同一个东西,比如说Socekt发送报文,都是一部分一部分数据的发送,每部分数据本身来说是完整的,但是对于客户端来说不是完整的,因为他们要把所有的数据块按照之前的顺序拼接起来才有效消息)
Message Reader的职责就是检查消息的完整性,以及存储不完整的消息。为了不把多个Channel的数据相互弄混淆了,于是每个Channel都创建一个独立的Message Reader,设计图如下:
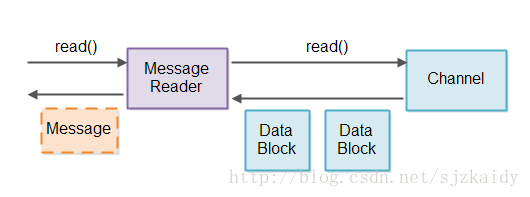
当从Selector中查询到有Channel有数据需要读取,Message Reader就和那个Channel关联起来并读取数据把数据转化成消息。当得到一个完整的消息时就把消息发送给管道的下个流程进行处理。
Message Reader当然和具体的协议规范有关,它需要知道待读取数据的消息格式。如果尝试实现一个跨协议的服务器,那它需要把Message Reader设计成一个可插拔的模块(看人家的意识多强大),比如使用一个Message Reader工厂类作为配置文件的参数。(tomcat服务器配置文件中有大量的这样的用法)
存储部分消息
现在我们确定了在接受部分消息时Message Reader的职责需要把它们存储起来,直到接收到完整的消息。我们需要给出一个存储部分消息的实现方法。
我们考虑以下两点设计:
- 我们要使拷贝的数据尽可能的小,因为越多的拷贝性能越低。
- 为了使解析数据能够简单点,我们希望把完整消息存储在连续的字节数组中。
一个Message Reader 一个Buffer
很明显部分消息需要存储在某种类型的Buffer中。一个直接简单的设计就是使Message Reader内部拥有一个Buffer。但是,这个Buffer到底要多大呢?它要尽可能的存储更多的数据甚至非常多的数据。所以如果消息有1MB大小,那Message Reader 内的Buffer的大小至少是1MB。
当有上百万的链接时,为每一个链接分配一个1MB的Buffer是不现实的,1,000,000 x 1MB = 1TB 内容!如果最大的消息有16MB 或者 128MB怎么办???
大小可变的Buffer
另外一个办法就是Message Reader中的Buffer大小是可改变的,Buffer大小开始非常小,当收到超过这个大小的消息时扩增Buffer的大小。这样一来每个链接的Buffer大小不用非得要1MB了,每个链接的Buffer大小和消息一致。
有好多办法实现一个大小可变的Buffer,下面我们一一讨论每种办法的利与弊:
通过复制改变大小
最开始我们使用一个很小的Buffer比如4KB,如果消息放不下,我们创建一个大一点的Buffer比如8KB,然后把4KB中的数据拷贝到新的8KB Buffer中。
这种设计的好处是,每个消息都存储在一个连续的字节数组中,使得解析消息变得非常简单。
这种设计的弊端是,对于大的消息来说会导致需要拷贝很多的数据。
为了减小拷贝数据你可能会结合整个处理流程的消息大小分析出一个折中大小,用来减少拷贝量。比如说 你发现请求响应的数据都非常小不足4KB,这样Buffer的大小设置成4KB。
然后你又发现请求数据大于4KB,因为它们含有file。但是整个流程中的消息大小不超过128KB,于是又创建了一个大小为128KB的Buffer。
最后你发现非常规情况下请求的数据大小超过了128KB,所以最后一个Buffer的大小可能是尽可能的大。
通过分析系统的整个处理流程得到了三种尺寸的Buffer。不管怎么说还是减少了拷贝量,少于4KB的数据不用拷贝,比如:1,000,000个并发链接花费的大小为:1,000,000 x 4KB = 4G 对于现在(2015)的服务器来说不是事。大小在4KB到128KB之间的消息将会拷贝一次,只有少于4KB的消息拷贝到128KB中。大于128KB的消息会拷贝两次,第一次拷贝4KB,第二次拷贝128KB的消息,所以对于大消息会有132KB的数据需要拷贝。假设没有太多的大于128KB的请求消息。(如果大部分都是大于128KB的话那这种情况不适合了)
当消息被全部处理完后分配的内存变成空闲,对于之前同一个链接当有新消息来到时又从最小的Buffer开始。在多个链接之间共享内存是很有必要的,大部分时候不是所有的链接都需要大Buffer。
有一个完整的关于可变大小的数组的项目教程Resizable Arrays
使用追加改变大小
另外一个办法是通过多个数组来改变Buffer大小,当你需要改变数组大小时,只需要简单的创建一个新的数组然后把剩下的数据写进去。
有两种办法扩增Buffer的大小,一种办法就是分配一多个独立的数组并记录下它们;另一个办法是创建一个非常大的共享的数组,分片使用,然后把相关联的片记录到Buffer中。个人观点,分片的办法稍微好点,但是它们之间的区别非常小。
通过创建独立的数组或者使用共享数组分片的办法来改变Buffer大小的优点就是在数据写入的过程中不需要进行拷贝。所有从socket(Channel)读取的数据都直接拷贝到数组或者片区中。
这种办法的缺点是数据不是保存在单独的连续的数组中。在解析消息的时候需要同时对每个数组或者片区进行检查,所以这种模型不是很好。
TLV 消息编码
有些协议使用TLV(T: Type L:Length V:value)格式来编码消息。这意味着当收到消息时,消息本身含有消息大小的字段。这样你就知道应该为一个完整的消息分配多少内存。
TLV编码格式使内存管理变得很简单,我们知道为一个完整的消息分配多少内存,没有造成内存浪费。
TLV编码格式的弊端在于,在所有的数据达到之前我们已经为它分好了足够多的内存,在网络慢的时请求数据比较大的情况下我们已经分配走了足够多的内存,这样会造成服务器响应变慢。(好多内存都被划走了,但是它们还是空着的,有点 占着茅坑不拉屎的感觉)
对于这个问题一个解决办法就是,包含多个TLV字段(Field)。这样为每一个字段分配内存,而不是分配整个消息大小的内存,并且只有当字段到达的时候才分配内存。但是仍然存在个别特别大的消息带有特别大的字段。
另一个解决办法就是为还没有达到的消息设置一个超时时间,比如:10-15秒。这样对于很多网络慢的发送大消息的情况系统能自我恢复,但是服务器仍然有一段时间响应卡顿。另外对于恶意的DoS攻击,还是会造成内存被全部分配的问题。
TLV编码存在很多不同的变种。使用哪些类型、分配多长的空间都依赖于具体的TLV编码。同样也存在把长度放到第一位、其次是类型 然后是值(LTV编码)的TLV编码,只是属性的顺序不同,但还是一种TLV的变种。
实际上由于TLV编码使得内存管理变得非常简单,因为这个原因使得HTTP1.1协议变得非常糟糕(造成服务器内存提前透支的厉害)。这也是为什么在HTTP2.0中在数据传输时尝试使用TLV编码Frame的原因。这也是为什么我们为自己的项目VStack.co project 使用一种TLV编码设计我们自己的网络协议的原因。
写入部分消息
在非阻塞式IO管道中写入数据也是一个挑战。当调用处于非阻塞模式的Channel的write(ByteBuffer)方法时,没办法保证ByteBuffer中到底有多少数据等待写入。write(ByteBuffer)方法返回了写入数据的长度,所以我们可以通过这个来统计。然而这里的挑战是:要保持记录每次部分写入消息的长度,直到所有数据写入完毕。
我们创建一个Message Writer用来管理写入部分消息到Chennel中。就和Message Reader一样为每一个Channel创建一个Message Writer。在它的内部需要精确的记录当前实际往Channel写入了多少数据。
在大部分情况下消息一到达Message Writer就可以直接写入Channel中,消息也有可能需要放到内部的队列中。然后尽可能的快的把消息写入Channel中。
下面是设计部分消息写入的示意图:
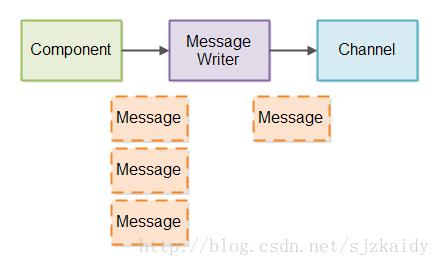
Message Writer需要能够尽可能早的发送部分消息,它会被一次又一次的调用,这样能够发送更多的数据。
如果有很多链接那么就有很多的Message Writer,比如1,000,000,在这么多中判断哪些有数据需要发送也是非常慢的。首先,有很多Message Writer没有需要写入的数据,我们当然不希望判断这些对象。其次,不是所有的Channel都准备好了写入数据,我们不想把时间浪费在尝试往没有准备好的Channel中写入数据。
我们往Selector中注入Channel,这样就可以判断哪些Channel准备好了写入数据。但是我们不能把所有的Channel都注册到一个Selector中啊。想象下有1,000,000个链接 它们大部分的时候不是活跃的,我们把它们都注册到一个Selector中,然后我们调用Selector的select()方法来获取准备好写入的Channel(但是它们大部分都是不活跃的?!)。然后你还是要对Message Write进行判断哪些链接是否有数据需要写入。
为了避免对那些没有数据需要写入的Channel的Message Writer进行判断,我们使用两步走(two-step)办法:
- 当有消息写入Message Writer时,我们把它对应的Channel注册到Selector中(如果还没有注册进去的话)。
- 当服务器有时间时,我们对注入到Selector的Channel进行判断哪些准备好了写入数据。对于准备好写入数据的Channel来说,Message Writer把数据写入进去,当所有数据写入完毕后,把Channel从Selector注册表中再一次移除。
以上两个小步骤能够使Selector中注册的都是准备好写入数据的Channel实例。(减少了很多)
总结下
如上所知非阻塞式IO服务器当有新的请求数据到达时需要一次又一次的检查数据是否是完整的消息。当完整的消息达到之前服务器需要检查一次或者跟多次,仅仅检查一次是不够的。
类似的非阻塞式IO服务器需要一次又一次的检查是否存在需要发送的数据。如果存在服务器要检查对应的链接是否准备好写入数据。由于数据可能是一部分,在开始的时候仅仅对在排队的数据进行检查是不够的。
总的来说非阻塞式服务器所有的执行都存在于三种管道中:
- 数据读取管道从一个打开的链接中检查是否有新的数据进入
- 处理管道处理任何到达的完整的消息
- 数据写入管道检查是否有数据需要写入到任何一个开启的链接中
这三个管道以循环的方式反复执行,你有可能对某一个地方进行优化。比如:可以忽略没有排队消息的写入管道,或者 也可以忽略那些没有新消息到达的处理管道。
下面是完整的服务器循环示意图:
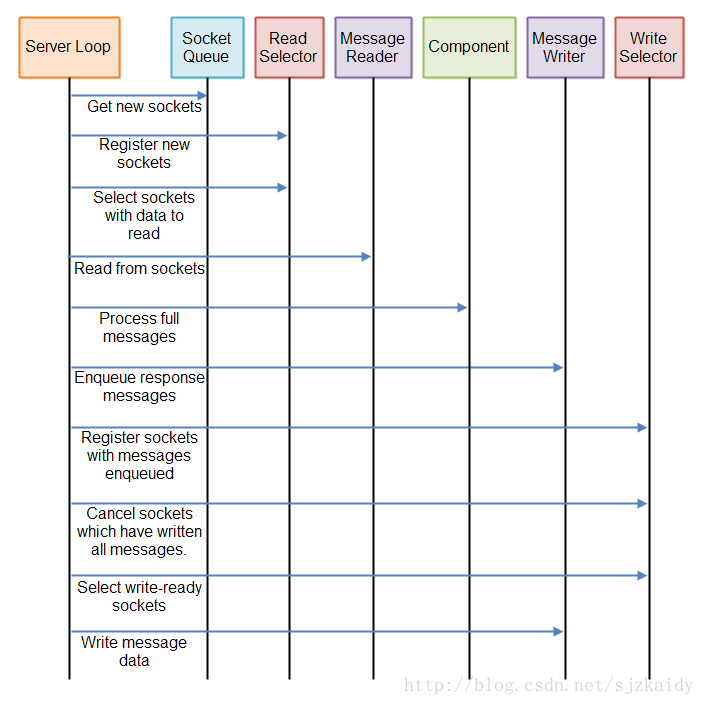
如有还有疑问可以参考项目:
https://github.com/jjenkov/java-nio-server
看看代码可能对你的理解有点帮助
服务器线程模型
Git仓库中的非阻塞式项目实现使用的线程模型中包含两个线程。第一个线程用来接收来自ServerSocketChannel的请求链接。第二个线程用来读取数据、处理数据、返回结果。示意图如下:
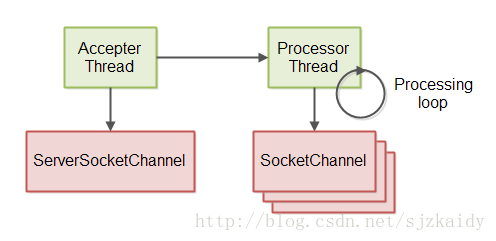
这个服务器处理循环解释了上一节中被处理线程执行的过程。
——————————-完结———————————-














 745
745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









