







9, 容器
Deque
双向队列
和vector类似, 新增加:
push_front 在头部插入一个元素
pop_front 在头部弹出一个元素
Deque和vector内存管理不同: 大块分配内存
Stack
先进后出结构 只有一个出口
只能访问顶端元素, 不允许遍历
支持操作:
push增加元素
pop移除元素
top获取顶端元素
实际底层使用Deque实现, 但也可以实际制定容器Container
Queue
先进先出结构, 两个出口
不允许遍历
支持操作:
push增加元素
pop移除元素
front获取最前端元素
back获取最后的元素
实际底层使用Deque实现, 但也可以实际制定容器Container
Map - 重点学习
关联容器, 存储对象为key/value pair
不允许重复key
map存储对象必须具备可排序性
类的声明:
template < class _Kty, class _Ty, class _Pr = lass<_Kty>, class _Alloc = allocator < pair < const _Kty, _Ty> > > class map{…………};
注意:
1, 两个> > 之间是有一个空格
2, 其中默认使用lass定义排序行为, 所以我们可以自定义排序行为 - 仿函数实现
3, 注意各种class的顺序!!! 注意排序所使用的可以是在哪里!!!
初步认识仿函数:
1, 定义一个类
struct Employee{
Employee(string& s1): Name(s1){}
string Name;
};
2, 定义一个仿函数
struct ReverseId: public std::binary_function< int, int, bool>{
bool operator() (const int& key1, const int& key2) const {
return (key1 <= key2) ? false : true;
}
};
仿函数就是要重载()小括号操作符! ! !
使用例子:
3, 构建一个序列:
std::pair < int, Employee> item[3] = {
std::make_pair(1, Employee(“Tom”)),
std::make_pair(2, Employee(“Azm”)),
std::make_pair(3, Employee(“Jack”)),
};
4, 定义一个map,是一个按照我们制定排序方法的map
std::map < int, Employee, ReverseId > map1(item, item+3);
5, 在map中插入元素
方法1 : map1.insert(std::make_pair(4,Employee(“Jason”)));
方法2 : map1[5] = Employee(“Hellon”);
6, 删除元素
std::map < int, Employee>::iterator it = map1.begin();
map1.erase(it);
7, 使用[]操作符存取元素
Employee& e = map1[14];
e.SetName(“Wason”);
Multimap
类似map的关联容器
允许key重复
std::multimap < int, Employee, ReverseId > mm1(item, item+3);
如果插入一个重复的key=1的key:
map1.insert(std::make_pair(4,Employee(“Peter”)));
则:
mm1.count(4)得到2 表名其中有两个key为4的元素
Set
关联容器, 存储对象本身即是key也是value
不允许重复key
set对象本身具有可排序性
类的声明:
template < class _Kty, class _Pr = lass <_Kty> , class _Alloc = allocator < pair< const _Kty> > >
class set {…………};
注意:
1,默认采用less作为排序行为, 可以使用仿函数自定义排序行为
2,存储对象必须具备operator < 行为
set初始化:
1, 定义一个类
struct Programmer{
Programmer(const int id, const std::wstring name):
Id(id), Name(name){ }
void Print() const
{
std::wcout<<L"["<<Id<<L"]: "<<Name<<std::endl;
}
int Id;
std::wstring Name;
};2, 定义仿函数
a, 使用ID升序排序
struct ProgrammerIdGreater : public std::binary_function< Programmer, Programmer, bool>{
bool operator() (const Programmer& p1, const Programmer& p2) const {
return (key1 <= key2) ? false : true;
}
};b, 使用Name来进行排序
struct ProgrammerNameComparer : public std::binary_function< Programmer, Programmer, bool>{
bool operator() (const Programmer& p1, const Programmer& p2) const {
return (p1.GetId() <= p2.GetId()) ? false : true;
}
};set相关算法:
1, set_union
std::set < Programmer, ProgrammerIdGreater > dest;
std::insert_iterator < std::set < Programmer, ProgrammerIdGreater > > ii(dest, dest.begin());
std::set_union(ps1.begin(), ps1.end(), ps2.begin(), ps2.end(), ii, ProgrammerIdGreater());
将会把ps1和ps2合并到dest当中,这里将会依照给出的排序规则进行排序!
2, set_intersection
std::set < Programmer, ProgrammerIdGreater > dest;
std::insert_iterator < std::set < Programmer, ProgrammerIdGreater > > ii(dest, dest.begin());
std::set_intersection(ps1.begin(), ps1.end(), ps3.begin(), ps3.end(), ii, ProgrammerIdGreater());
将会把ps1和ps3中全部重复的元素提取出来放在dest中! 这里将会依照给出的排序规则进行排序!
3, set_difference
std::set < Programmer, ProgrammerIdGreater > dest;
std::insert_iterator < std::set < Programmer, ProgrammerIdGreater > > ii(dest, dest.begin());
std::set_intersection(ps1.begin(), ps1.end(), ps4.begin(), ps4.end(), ii, ProgrammerIdGreater());
将会把全部存在于ps1中但不存在于ps4中的元素提取出来放在dest中.
4, 修改set对象中非key成员:
std::set < Programmer, ProgrammerIdGreater >::iterator it = ps1.find(Programmer(L”Bill”, 4));
if( it != ps1.end() )
const_cast < Programmer&>(*it).SetName(L”Bill Gates”);
注意这里的 & 引用 , 如果不加& 那么也是可以通过编译, 但是这样都是修改一个临时对象而已! 并不会实际修改.
10, 仿函数适配器
目的: 将无法匹配的仿函数"套接"成可以匹配的型别
适配器:
binder1st/binder2nd
mem_fun/mem_fun_ref
实在是太难解释binder1st的实际使用原理, 所以先暂时使用老师的ppt:
注意:
1, first_argument_type
2, 操作符()重载
3,实现顺序
4,find_if()内部实现

老师的写法相当复杂!
其实实际写法是:
std::vector < int > ::iterator it = std::find_if(v.begin(), v.end(), std::bind1st( std::not_equal_to < int >(), 0 ) );
这里的0对应上面的value, 即使用0来初始化first_argument_type .
而另外一个bind2nd适配器,是类似的.
区别在于Func操作的作用是 左值 还是 右值 !!
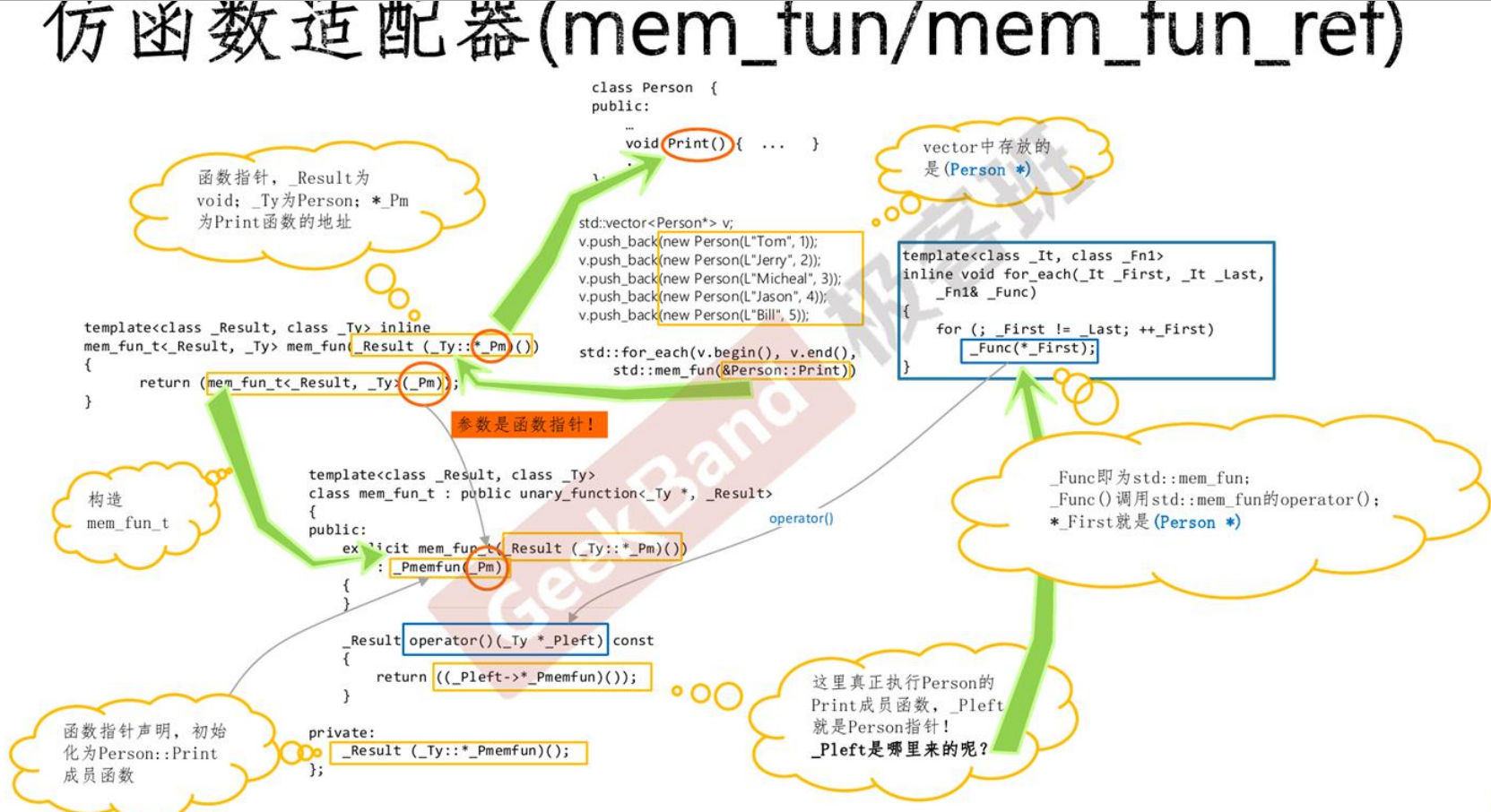
mem_fun/mem_fun_ref:
是用来适配对象的成员函数
比如:
std::vector < Person* > v;
…在v中加入很多成员.
其中Person类有一个成员函数Print() 用于打印信息.
std::for_each( v.begin(), v.end(), &Person::Print );
如果一切顺利的话, 那v中的每个对象都会执行一遍Print()函数, 但很可惜的是, 这里无法编译通过.
因为for_each只接受: Function(Obj) 其中Function为全局函数, 这样的调用.
所以这个时候 牛X的 mem_fun适配器出现了!
std::for_each( v.begin(), v.end(), std::mem_fun(&Person::Print) );
这样就能完美执行!
实现原理…………………………….
= =!
嗯, 看老师的ppt吧:
如果vector中放的不是Person对象的指针,那么就使用mem_fun_ref适配
std::vector v;
…………………
std::for_each( v.begin(), v.end(), std::mem_fun_ref(&Person::Print) );
11,注意问题
1, 尽量使用算法,而不是手写for循环
即使是在delete销毁对象这样的情况下. 为了能够销毁对象, 我们需要专门定义一个struct DeleteElement对象并重载operator()
struct DeleteElement{
template
void operator()(const TElement* p)const {
delete p;
}
};
然后使用for_each来销毁容器中的对象:
std::for_each(v.begin(), v.end(), DeleteElement() );
2, 使用swap来对容器进行缩水
3, 建立指针的容器,而不是对象的容器.
否则会出现很多问题. 比如数据切割,当对象通过基类拷贝,那么派生部分将会被切割掉! (slicing)
拷贝也会造成额外的内存开销.














 110
110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









