










给定一个query和一个text,均由小写字母组成。要求在text中找出以同样的顺序连续出现在query中的最长连续字母序列的长度。例如, query为“acbac”,text为“acaccbabb”,那么text中的“cba”为最长的连续出现在query中的字母序列,因此,返回结果应该为其长度3。请注意程序效率。
想了好多种方法,姑且先说几种有创意的..
第一种,打卡遮盖型
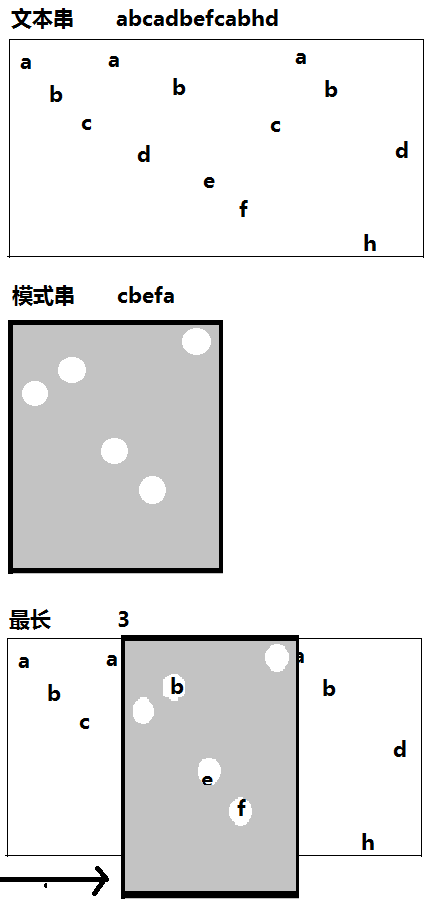
画得有点丑,有点不规范不要在意,能理解就最好.
明显这是一种空间换时间的算法.
时间复杂度就是O(n+m)
空间复杂度O(n*m)
第二种,过火车匹配
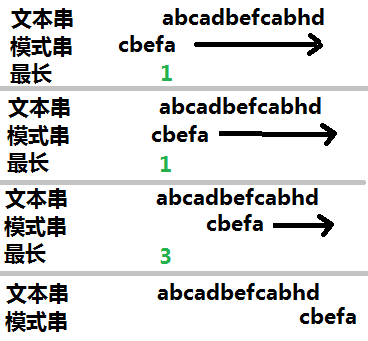
从头过到尾
其实这种就是最普通的一种
时间复杂度O(n*m)
空间复杂度O(1)
第三种,求出next[ ]改进.
正如KMP算法那样,有很多比较是多余可跳过的.
比如说上面的,比较第一个字符a,而后失配时可以直接跳到第4个字符a,再跳到第10个字符a
中间的就可以忽略了,反正都肯定是不匹配的.
不过建立next[ ]也需要一定的时间(O(n²)),对于很长的字符串他的作用才能明显发挥.
void GetNextVal(char *str)
{
int next [ 30 ]= { 0 };
int len=strlen(str);
for( int i = 0 ; i< len ; i++)
{
if( next [ i ] == 0 )
{
int j=i+1;
while (str [ i ] != str [ j ] && j < len || next [ j ] != 0 ) j++;
if( j != len) next[ i ] = j;
else next[ i ] = -1;
}
}
}
第四种,用哈希函数建立索引
这种又是上一种的改进.用哈希建立索引只需要O(n)即可.
比如说:
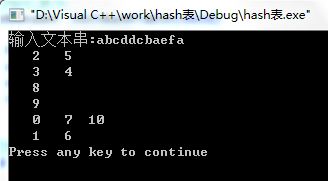
文本串: 157369824704
对于每个字符进行分类,设哈希函数 f(n)=n mod 10 = d;
那么
f(A[0])=[1] mod 10 =1 ;
f(A[1])=[5] mod 10 =5 ;
f(A[2])=[7] mod 10 =7;
f(A[3])=[3] mod 10 =3 ;
f(A[4])=[6] mod 10 =6;.....
这样可以得到一个索引
索引0: 10->null;
索引1: 0->null;
索引2: 7->null;
索引3: 3->null;
索引4: 8 ->11->null;
索引5: 1->null;
索引6: 4->null;
索引7: 2->9->null;
................
然后假设模式串是59826
对 第一个字符使用哈希函数
得到 对应位置是 先比较位置1,得到最长匹配为1
对第二个使用哈希,得到比较位置5,比较成功得到最长匹配为3
对第三个使用哈希.得到比较位置6,得到最长匹配为2
...............
可见这种拥有是时间复杂度O(n)~O(n*m)是效率不错的.
至于空间复杂度,看哈希函数怎么设定了.
以下是我写的代码,对以上几种想法都采取一点而改进成.
主体还是以一定的空间换时间,而后匹配方面采用Sunday算法加速.
用链表的形式来做索引,用数组来表达得到的key值
这样组合起来就得到一个...(后来查了下) 散列表,也叫hash表. (我想了大半个下午原来已经早被发明也还是教科书的东西∑(゚Д゚)
先是散列表的数据结构 代码
#include <stdio.h>
#include <stdlib.h> //malloc需要用
#include <string.h>
#define Len 11
/******************************
哈希表头
******************************/
typedef struct HashHeader
{
struct Node *next;
}HashHeader,*PHashHeader; //写了typedef这两个是结构体,不写则是变量
PHashHeader HashTable[Len];
//初始化表头
PHashHeader InitHashTable(void)
{
PHashHeader node;
node=(PHashHeader)malloc (sizeof(PHashHeader));
node->next=NULL;
return node;
}
//初始化哈希表
void InitTable()
{
for(int i=0;i<Len;i++)
HashTable[i]=InitHashTable();
}
/*******************************
节点
******************************/
typedef struct Node
{
int data;
Node *next;
}Node,*PNode;
PNode PEnd[Len];
//哈希函数
int HashFunc(char c)
{
int key=(int)c % Len;
return key;
}
//加节点
void AddNode(char c,int i)
{
PNode node;
int key=HashFunc(c);
node=(PNode)malloc (sizeof(PNode));
node->data=i;
node->next=NULL;
if(HashTable[key]->next==NULL)
{
HashTable[key]->next=node;
PEnd[key]=node;
}
else if(PEnd[key]->next==NULL)
{
PEnd[key]->next=node;
PEnd[key]=node;
}
else printf("error");
}
void PrintHash()
{
PNode Pr;
for(int i=0;i<Len;i++)
if(HashTable[i]->next!=NULL )
{
Pr=HashTable[i]->next;
while(Pr !=NULL)
{
printf("%4d",Pr->data);
Pr=Pr->next;
}
printf("\n");
}
}
int main()
{
char Tstr[30];
printf("输入文本串:");
gets(Tstr);
int Tlen=strlen(Tstr);
InitTable();
for(int i=0;i<Tlen;i++)
AddNode(Tstr[i],i);
PrintHash();
return 0;
}运行结果:
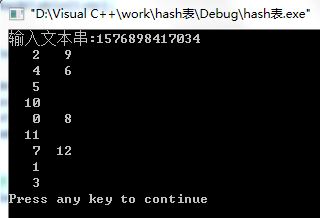
以下则是题目要求的函数
int jiaoji(char *Tstr,char *Mstr)
{
int max=0;
int Tlen=strlen(Tstr);
int Mlen=strlen(Mstr);
InitTable();
int i,j;
for(i=0;i<Tlen;i++)
AddNode(Tstr[i],i);
for(i=0;i<Mlen;i++)
{
j=HashFunc(Mstr[i]);
if(HashTable[j]->next !=NULL )
{
PNode Pr=HashTable[j]->next;
while(Pr != NULL)
{
int data=Pr->data;
int k=max-1; //类似Sunday算法,从尾部开始比较,反正目的只是取最大
while(Tstr[data+k] == Mstr[i+k] && data+k < Tlen && i+k< Mlen)k++;
max=max<k?k:max;
Pr=Pr->next;
}
}
}
return max;
}
int main()
{
char Tstr[30],Mstr[20];
printf("输入较长的串:");
gets(Tstr);
printf("输入较短的串:");
gets(Mstr);
int max=jiaoji(Tstr,Mstr);
printf("最多相交部分长度是%d",max);
return 0;
}上文用到的是较长 和 较短 的字符串, 因为 长的用来做哈希比较好, 这样用短的每个寻址就可以了.
空间复杂度..O(n+m)
时间复杂度 O(n+m)
效率还可以吧..测了几个例子都














 98
98











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









