







JAVA抓取小说DEMO
之前看一篇小说,发现只有在线的版本,于是动手写了个小程序抓到本地方便在Kindle上看。程序非常简单,不同的网页请自行修改正则等部分。
这里也顺带安利一下小说,哈利·波特的同人,《哈利·波特与理性之道》。
源码放在GitOSC上。
项目结构
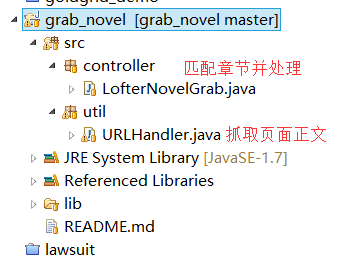
流程图
抓取页面正文的主要代码
// 根据URL获取网页内容,设定编码格式
public static String getURLContext(String targetUrl, String coding)
throws IOException {
StringBuffer res = new StringBuffer();
URL url;
url = new URL(targetUrl);
BufferedReader br = new BufferedReader(new InputStreamReader(
url.openStream(), coding));
if (br != null) {
String s = null;
while ((s = br.readLine()) != null) {
res.append(s);
}
br.close();
}
String result = res.toString();
return result;
}源码中另附了URLConnection方式获取正文。
匹配章节并处理的主要代码
public class LofterNovelGrab {
private static String filePath = "D:/Harry Potter and the Methods of rationality.txt"; // 本地保存地址
private static String mainUrl = "http://hpmor.lofter.com/contents"; // 主页地址
private static String charset = "utf-8"; // 网页编码
private static Pattern chapterPtn = Pattern
.compile(
"<p><a\\s*target=\"_blank\"\\s*href=\"(.+?)\"\\s*>(.+?)</a>\\s*</p>\\s*",
Pattern.DOTALL); // 章节名称与地址的正则
private static Pattern contentPtn = Pattern.compile(
"<div\\s*class=\"txtcont\">\\s*(.+?)\\s*</div>", Pattern.DOTALL); //章节正文正则
public static void main(String[] args) throws IOException {
FileOutputStream fileOut = new FileOutputStream(filePath);
PrintStream p = new PrintStream(fileOut);
int i = 0;
String mainPage = URLHandler.getURLContext(mainUrl, charset);
mainPage = mainPage.replaceAll(" |<br\\s*/>", " "); // 清除章节标题中的空格
Matcher m = chapterPtn.matcher(mainPage);
while (m.find()) {
p.println(m.group(2));
System.out.println(i++ + ".chap : " + m.group(1) + " | "
+ m.group(2));
String content = URLHandler.getURLContext(m.group(1), charset);
Matcher mc = contentPtn.matcher(content);
if (mc.find()) {
String text = mc.group(1);
text = StringEscapeUtils.unescapeHtml4(text); //清除正文的HTML标签
text = text.replaceAll("<p>|</p>|<br\\s*/>", "\n");
text = text.replaceAll("<.+?>|</.+?>", " ");
p.println(text); //存 入文件
}
}
try {
fileOut.close();
} catch (IOException e) {
e.printStackTrace();
}
p.close();
}
}















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









