







稍微总结一下:
今天爬的稍微有点打击士气了,但是还是学到了不少东西,
告诉我们,要学会自己去百度,谷歌答案, 自己去思考,不要依赖一些技术交流QQ群,很多都是水群的, 真的帮助你的是很少的。
重点在这里:今天学了将爬取的数据存取到txt ,.xlsx文件,也就是txt文件跟excel 表格中,又一次加强了re模块的正则表达式,
先贴结果图:
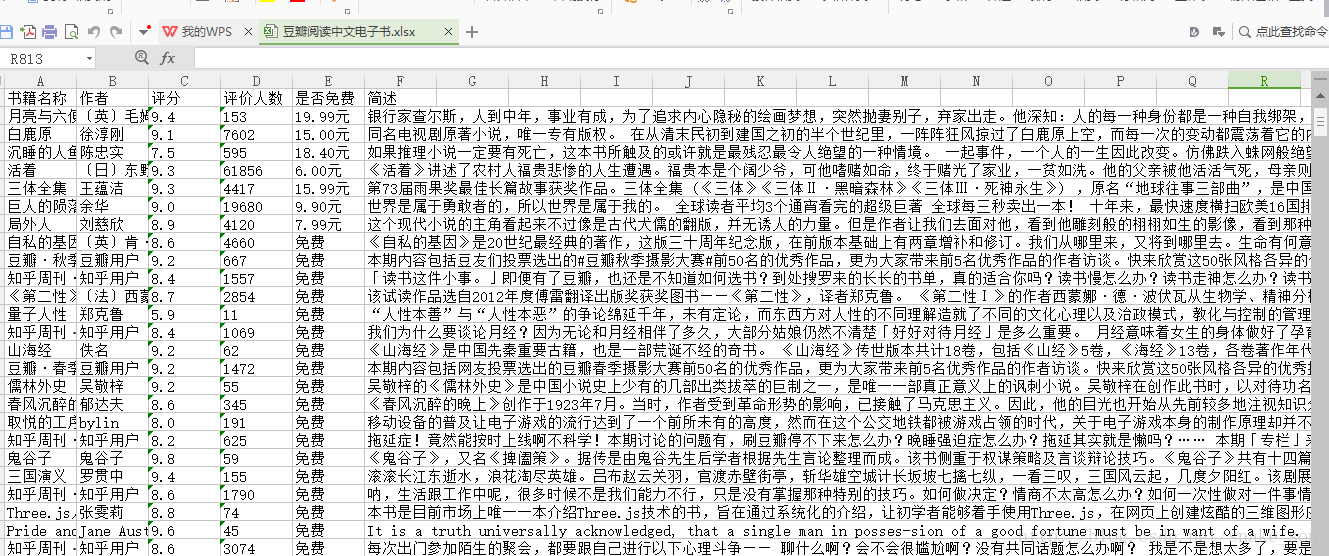

这次爬取的是
贴代码:我是比较习惯先贴上代码, 让大家先把项目贴进去再跑起来看一看的
# encoding=utf8
import requests
import re
from bs4 import BeautifulSoup
import csv
import time
import threading
from openpyxl import Workbook
num0 = 1 # 用来计数,计算爬取的书一共有多少本
url0 = 'https://read.douban.com/kind/0?sort=hot&promotion_only=False&min_price=None&max_price=None&works_type=None' # 原创写作(都是根据热门一栏进行选择)
url1 = 'https://read.douban.com/kind/1?sort=hot&promotion_only=False&min_price=None&max_price=None&works_type=None' # 中文电子书
url2 = 'https://read.douban.com/kind/300?sort=hot&promotion_only=False&min_price=None&max_price=None&works_type=None' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1922
1922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









