







请转移新博客地址:
http://blog.csdn.net/xudailong_blog
老实说:懵逼啊
这次爬取的是智联招聘上的求职数据,虽然没有仔细正确核对一下数据是否具有重复性,随机抽查了些,数据大部分还是能对上来的,这次爬取的智联招聘上的数据90页,每页60条,主要抓取的是android开发工程的数据,
抓取的数据为全国的数据,先上张结果图吧,
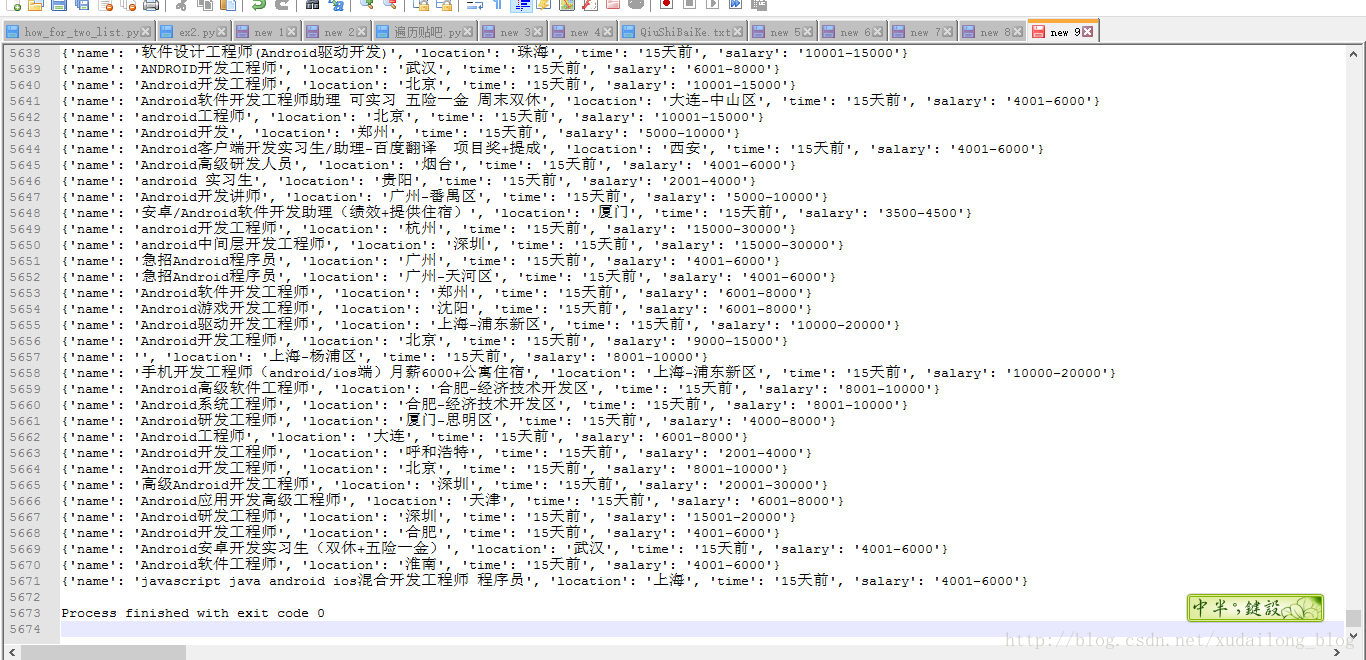
如果是想看大图,可以选中图片,长按,移动到网页最上面的边上就可以了。
ide 部分
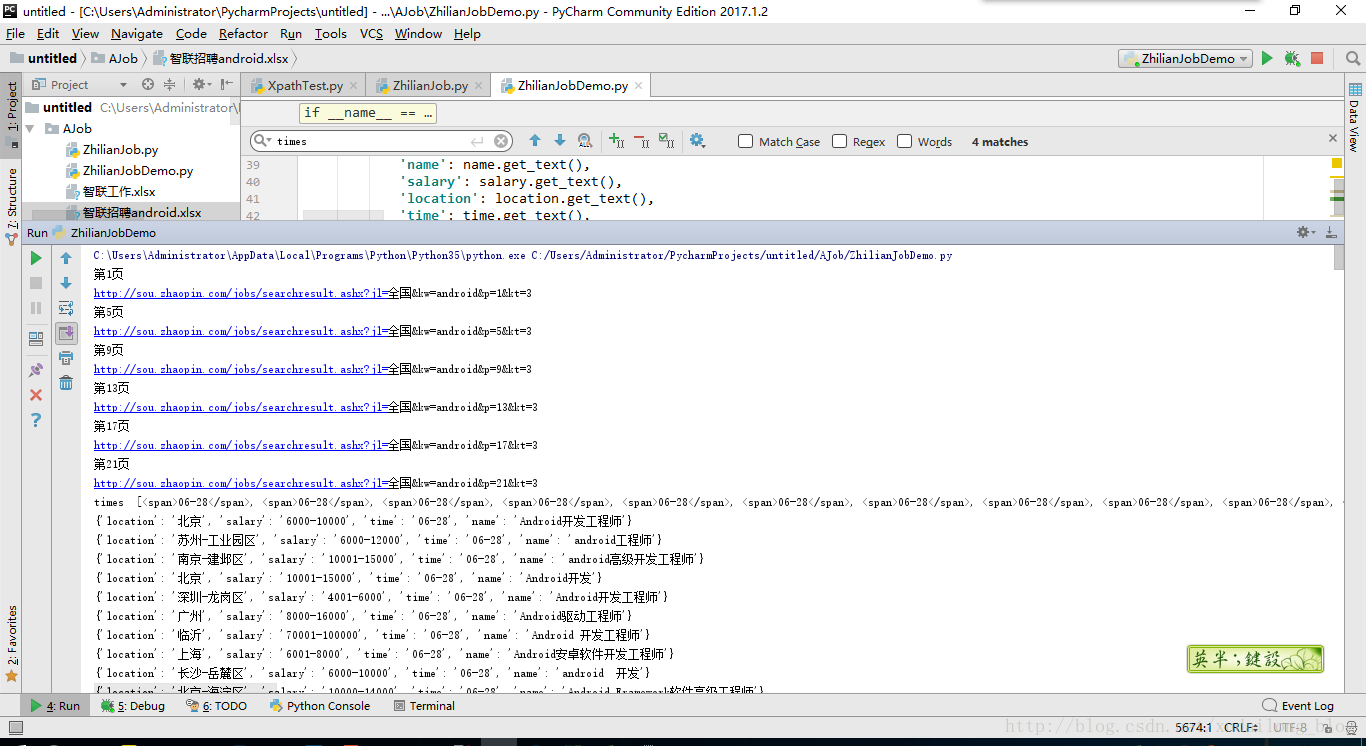
数据用了多线程的方式,这是第一次用,因为这次用了多线程,很多时间都花在怎么把数据存储到excel文件中,后面debug下了,还是不知道怎么存,以后再过来填这个坑吧,确实有点坑,是不是。这次本来用的xpath,第一次用的是直接在浏览器右键copy xpath路径就没事了,谁知,内存地址能搞出来,但就是搞不出文本来。很无奈啊
又改回beautifulsoup 这玩意了,说实话,东西不用了,确实用的也生疏起来,这也是为什么作为一个初学者需要进行多练习吧,这样才能记住东西,
可值得学习的亮点:
url = 'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=全国&kw=android&p={0}&kt=3'.format(page)
print("第{0}页".format(page))以后要多用这样子的形式,显出逼格来,难道不是吗?
这一块,beautifulsoup的强处吧?以后还是多用用这个方法
也贴出来
job_name = soup.select("table.newlist > tr > td.zwmc > div > a")
salarys = soup.select("table.newlist > tr > td.zwyx")
locations = soup.select("table.newlist > tr > td.gzdd")
times = soup.select("table.newlist > tr > td.gxsj > span")
print('times '+str(times))
for name, salary, location, time in zip(job_name, salarys, locations, times):
data = {
'name': name.get_text(),
'salary': salary.get_text(),
'location': location.get_text(),
'time': time.get_text(),
}
print(data)最后就是多进程的地方了,python这玩意,确实,没几行代码,能搞出这么多事情
pool = Pool(processes=6)
pool.map_async(get_zhaopin, range(1, 91))
# wb.save('智联招聘android' + '.xlsx')
pool.close()
pool.join()最后贴出完整代码吧,运行环境pycharm2017 ,python35
# coding:utf-8
import requests
from bs4 import BeautifulSoup
from multiprocessing import Pool
from openpyxl import Workbook
import json
pageNum = 1 # 用来计数,爬取了多少条目的
wb = Workbook()
ws = wb.active
ws.title = '智联招聘'
ws.cell(row=1, column=1).value = '岗位'
ws.cell(row=1, column=2).value = '地址'
ws.cell(row=1, column=3).value = '发表天数'
ws.cell(row=1, column=4).value = '薪资'
def get_zhaopin(page):
global pageNum
url = 'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=全国&kw=android&p={0}&kt=3'.format(page)
print("第{0}页".format(page))
print(url)
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
,
'Cookie': 'JSSearchModel=0; LastCity%5Fid=653; LastCity=%e6%9d%ad%e5%b7%9e; LastJobTag=%e4%ba%94%e9%99%a9%e4%b8%80%e9%87%91%7c%e8%8a%82%e6%97%a5%e7%a6%8f%e5%88%a9%7c%e5%b8%a6%e8%96%aa%e5%b9%b4%e5%81%87%7c%e7%bb%a9%e6%95%88%e5%a5%96%e9%87%91%7c%e9%a4%90%e8%a1%a5%7c%e5%ae%9a%e6%9c%9f%e4%bd%93%e6%a3%80%7c%e5%91%98%e5%b7%a5%e6%97%85%e6%b8%b8%7c%e5%bc%b9%e6%80%a7%e5%b7%a5%e4%bd%9c%7c%e5%b9%b4%e5%ba%95%e5%8f%8c%e8%96%aa%7c%e4%ba%a4%e9%80%9a%e8%a1%a5%e5%8a%a9%7c%e9%80%9a%e8%ae%af%e8%a1%a5%e8%b4%b4%7c%e9%ab%98%e6%b8%a9%e8%a1%a5%e8%b4%b4%7c%e8%82%a1%e7%a5%a8%e6%9c%9f%e6%9d%83%7c%e5%85%a8%e5%8b%a4%e5%a5%96%7c%e5%8a%a0%e7%8f%ad%e8%a1%a5%e5%8a%a9%7c%e8%a1%a5%e5%85%85%e5%8c%bb%e7%96%97%e4%bf%9d%e9%99%a9%7c%e5%85%8d%e8%b4%b9%e7%8f%ad%e8%bd%a6%7c%e5%b9%b4%e7%bb%88%e5%88%86%e7%ba%a2%7c%e5%8c%85%e5%90%83%7c%e6%88%bf%e8%a1%a5%7c%e5%8c%85%e4%bd%8f%7c%e9%87%87%e6%9a%96%e8%a1%a5%e8%b4%b4; LastSearchHistory=%7b%22Id%22%3a%22189ddb74-f21f-45b7-aae7-f4b2669b25a1%22%2c%22Name%22%3a%22python+%2b+%e6%9d%ad%e5%b7%9e%22%2c%22SearchUrl%22%3a%22http%3a%2f%2fsou.zhaopin.com%2fjobs%2fsearchresult.ashx%3fjl%3d%25e6%259d%25ad%25e5%25b7%259e%26kw%3dpython%26isadv%3d0%26sg%3db19e7c6f12a348359a72d76356038a60%26p%3d4%22%2c%22SaveTime%22%3a%22%5c%2fDate(1498753078650%2b0800)%5c%2f%22%7d; SubscibeCaptcha=6A68665FC75D4E6F42128088820FE28E; urlfrom=121126445; urlfrom2=121126445; adfcid=none; adfcid2=none; adfbid=0; adfbid2=0; dywez=95841923.1498753080.1.1.dywecsr=(direct)|dyweccn=(direct)|dywecmd=(none)|dywectr=undefined; dywea=95841923.196580863499777400.1498753080.1498753080.1498753080.1; dywec=95841923; dyweb=95841923.1.10.1498753080'
}
wbdata = requests.get(url, headers=header).text
soup = BeautifulSoup(wbdata, 'lxml')
job_name = soup.select("table.newlist > tr > td.zwmc > div > a")
salarys = soup.select("table.newlist > tr > td.zwyx")
locations = soup.select("table.newlist > tr > td.gzdd")
times = soup.select("table.newlist > tr > td.gxsj > span")
print('times '+str(times))
for name, salary, location, time in zip(job_name, salarys, locations, times):
data = {
'name': name.get_text(),
'salary': salary.get_text(),
'location': location.get_text(),
'time': time.get_text(),
}
print(data)
# ws.cell(row=page+1, column=1).value =name.get_text()
# ws.cell(row=page+1, column=2).value = salary.get_text()
# ws.cell(row=page+1, column=3).value = location.get_text()
# ws.cell(row=page+1, column=4).value = time.get_text()
if __name__ == '__main__':
pool = Pool(processes=6)
pool.map_async(get_zhaopin, range(1, 91))
wb.save('智联招聘android' + '.xlsx')
pool.close()
pool.join()
# for i in range(1,3):
# get_zhaopin(1)
# wb.save('智联招聘android' + '.xlsx')不足之处:
1 ,存储没有做好
2 ,数据进行解析方面做的不到位,没有很耐心的去一个一个认真的解析
3, 部分数据还未写进来。比如公司名称。
4, 对beautifulsoup库又快忘得差不多,需要对mysql,mogodb数据库存储进行学习,加快脚步。














 317
317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









