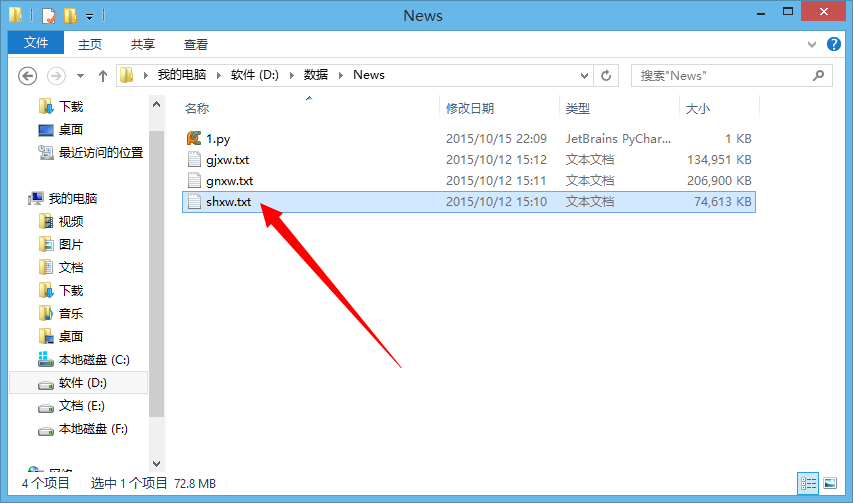
使用结巴中文分词(jiebaR)对之前爬取的新浪新闻 文本进行分词,统计词频之后,使用包wordcloud画词云。 1、读入数据 以下数据是在这里爬取的,这里只对社会新闻类进行测试,文件还是比较大的。分词完有一千多万个词,处理完后有将近30万。 library(jiebaR) library(wordcloud) #读入数据分隔符是‘\n’,字符编码是‘UTF-8’,what=''表示以字符串类型读入 f <- scan('D:/数据/News/shxw.txt'








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3903
3903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






