









1.1 generator
1.1.1 职责
generator的目的是从crawldb中根据一定的选取策略,选取一部分url作为本次循环爬取列表(fetchlist)。在生成爬取列表的过程中,需要考虑爬虫的“礼貌”问题——爬虫不能只顾自己以最快的速度将需要爬取的内容全部爬取下来,而不管对所爬取的网站造成多大访问压力,过分的爬取策略可能会被源网站认为是DOS(Denial Of Service)攻击,而被源网站给禁掉IP。爬虫在爬取的过程中,应该在自己力所能及的范围内,将对源网站的访问压力降低大最小。
generator为了遵循“爬虫礼貌”,做了不少努力,在生成fetchlist的时候,实现了如下目标:
目标1)重要程度较高(score)的url应该被优先fetch。
目标2)能够限制一个fetchlist中最多允许有多少个url。
目标3)由于不同的host有不同数量的url,为了避免在fetchlist中,url绝大部分都是来自于host(网页数据量大的),以便于小host的url能有机会被fetch,必须限制每个fetchlist中最多有多少个url。
目标4)同一个host的所有url必须处于同一个partition中,nutch在爬取的时候,就能够采取控制措施(采用顺序处理),以减小对该host的访问压力。假如不满足该目标,nutch对同一个fetchlist采用一个fetcher进行处理,不同的fetcher并发的时候,会造成不同的fetcher抓取同一个host下的不同网页,对该host造成访问压力。
目标5)来自于同一个host的URL在fetchlist中隔得越远越好,通常是将不同host的URL进行交叉,以保证fetcher在顺序访问的时候,以减少nutch对某个host的等待时间。
目标6)url partition的数量最好与fetcher的mapper的数量保持一致,因为这样,正好一个fetchlist会被一个fetcher的mapper task处理,减少了shuffle。
1.1.2 Usage
Generator <crawldb><segments_dir> [-force] [-topN N] [-numFetchers numFetchers] [-adddaysnumDays] [-noFilter] [-noNorm][-maxNumSegments num],参数作用如下:
1) crawldb
crawldb的存储目录,指向crawldb的根目录,非current目录,系统将 crawldb+current作为输入
2) segments_dir
生成的segments的存储目录,是generator的输出目录。一次可以生成多个爬取列表,即多个segment/crawl_generate目录。
3) –force
是否在crawldb被其他正在执行的tool(如updatedb)锁定(crawldb目录中存在.lock文件)时,仍然强制锁定crawldb。注意:如果为true,可能损坏crawldb。至于genenrator为何会锁定crawldb,主要是为了避免在多个generator同时执行时,将相同的url加入到不同的爬取列表中,故避免重复爬取相同的URL,浪费资源。详见“generate.update.crawldb”参数的说明。
4) -topN N
总共最多只选取多少个URL生成fetchlist。考虑分布式执行时,如果有N个reducer,那么每个reducer生成的每个fetchlist中URL个数不超过limit= topN/N个,实际只能是(limit-1)个。如果设置了- maxNumSegments参数的话,每个reducer生成的fetchlist中URL总数为(limit-1)*(maxNumSegments-1)个。
5) –numFetchers numFetchers
生成的crawl_generate目录的个数,底层指定的是partitionJob的reducer的个数。
6) -adddays numDays
为加入到segment的URL设置延迟多少天才被爬取调度器(FetchSchedule)允许加入爬取列表。即:设置URL爬取延迟多少天。
7) –noFilter
是否在生成爬取列表的过程中对URL进行过滤。
8) –noNorm
是否在生成爬取列表的过程中对URL进行规范化。
注意:
nutch在对URL规范化和过滤方面的参数名称设置上,有些摇摆不定,一会用noFilter和noNorm,一会用filter和norm,应该统一并且设置合理的default值。
9) -maxNumSegments num
maxNumSegments表明每个reducer(假设为N个)能最多生成几个fetchlist,每个fetchlist里面有limit=topN/N个,那么如果同时设置了topN和maxNumSegments这2个参数,总共生成的fetchlist里面含有的url个数=(topN/N-1)*N*(maxNumSegments-1)。
1.1.3 Configurable Item
表2 generator的可配置参数
| 参数名 | 含义 | nutch-default.xml中是否已配置 | 默认值 |
| generate.update.crawldb | 是否在generator完成之后,更新crawldb,主要是更新CrawlDatum的_ngt_字段为此次执行generator的时间,防止下次generator(由参数crawl.gen.delay指定的时间之内开始的另一个generator),加入相同的url(备注:即使下次generator加入相同的url,也不会造成逻辑错误,只是会浪费资源,重复爬取相同URL),详见nutch-default.xml。 | 是 | false |
| generate.min.score | 如果经过ScoreFilters之后,url的score值(反应网页重要性的值,类似于PageRank值)仍然小于generate.min.score值,则该url不加入fetchlist中(即跳过该URL),配置了改值,表明generator只会考虑将较重要的网页加入到fetchlist | 是 | 0,表明所有url都不会因为score值在generator阶段被过滤掉 |
| generate.min.interval | 设置该值表示generator只考虑需要频繁采集的url(即:CrawlDatum的fetchInterval较小),对于不需要频繁采集的url,不加入到fetchlist | 是 | -1,表明禁用该检查 |
| generate.restrict.status | 如果一个url的CrawlDatum的status等于该状态,将会被禁止加入到fetchlist,单值字段,只能指定一个状态 | 否 |
|
| generate.filter | 使用配置的URLFilter plugin来对url进行过滤 | 否 | 默认为true,注意:genertor提供的参数是noFilter,该值默认是false,可通过main的args override |
| generate.normalise | 使用配置的URLNormalizer plugin来对url进行normalize | 否 | 默认为true,注意:genertor提供的参数是noNorm,该值默认是false,可通过main的args override |
| generate.max.count | 与generate.count.mode相配合,限制生成的每个fetchlist里属于同一个host/domain/ip的URL最多为(generate.max.count-1)个 | 否 | -1,表示不限制一个fetchlist里面有多少个属于同一个host/domain/ip的url |
| generate.count.mode | byHost/byDomain/byIP三种,表示按照何种方式计数,以达到generate.max.count指定的数量 | 否 | byHost,即根据host来对每个fetchlist中的url进行计数,同一个segment里面属于同一个host的url不能超过generate.max.count,如果超过,则需要将其他属于该host的url放到新的fetchlist中(如果还有新的fetchlist未放满的话) |
| generate.topN | 表示不管生成多少个fetchlist,只包含重要程度排序靠前的N个URL,即所有fetchlist中URL的个数加起来不超过topN,这些url可以属于不同的host/domain/ip | 否 | -1,表示一个segment里的url个数不限制,如果=-1,那么造成生成新的segment的唯一原因——按照generate.count.mode指定的计算方式,达到了generate.max.count上限 |
| generate.curTime | 当前时间,准确地说是generator job开始执行的时间,而不是遍历到该url的时间(考虑到处理该url之前的其他url可能会耗费较长时间,造成计算_ngt_+ crawl.gen.delay > generate.curTime 不准确的问题 | 否 | 用来generator内部通过Configration向mapper传递参数用,不提供配置选项,也不提供main args参数设置 |
| crawl.gen.delay | generator执行时,会使用“_ngt_”(stand for ”nutch generate time“)作为key来来存储上一次对该url调用generator的时间,表明该url已经加入到了某个fetchlist,并可能正在完成fetch->updated的过程当中,而可能这个过程时间较长,也或者过程中出错了,而generator执行的过程当中。在考虑该url是否能加入此次的fetchlist时,需要一种机制来判断是否能将该url加入还是继续等待之前的fetch->updatedb流程完成(这样crawldb中该url的_ngt_会被更新成上次成功执行generator的时间。crawl.gen.deley就是用来解决该问题的,如果”_ngt_”+crawl.gen.delay < 当前时间,则该url可以加入到本次生成的fetchlist中;否则,不加入(跳过该url) | 是 | 604800000ms,即7天 |
| generate.max.num.segments | 每个reducer能生成多少个fetchlist | 否 |
|
| generate.max.per.host.by.ip |
| 否
| deprcated,被partition.url.mode代替 |
| partition.url.mode | 在对生成的fetchlist做划分(partition)的时候,划分的方式是什么,有如下3中:byHost/byDomain/byIP | 否 | 默认是ByHost,partitionJob的分区方式 |
| partition.url.seed | 为了避免在对生成的fetchlist做划分(partition)的时候,对一个URL来说,避免将其每次都划分到同一个parition,即同一个Reducer | 否 |
|
1.1.4 MapReduce Job分析
generator的核心任务是从crawldb中选取一部分url的子集,将其组织成一个爬取队列——fetchlist。该任务又拆具体分成:
1) 由于crawldb中的url是并不是按照score高低排序的,需要对url按照score降序排列。
2) 从排好序的crawldb中,逐个取出url,将其分成maxNumSegments个子集,在此过程中,要同时满足为了保持“爬虫礼貌”而制定的目标2)目标3)。
以图 17来形象化generator需要完成的任务:
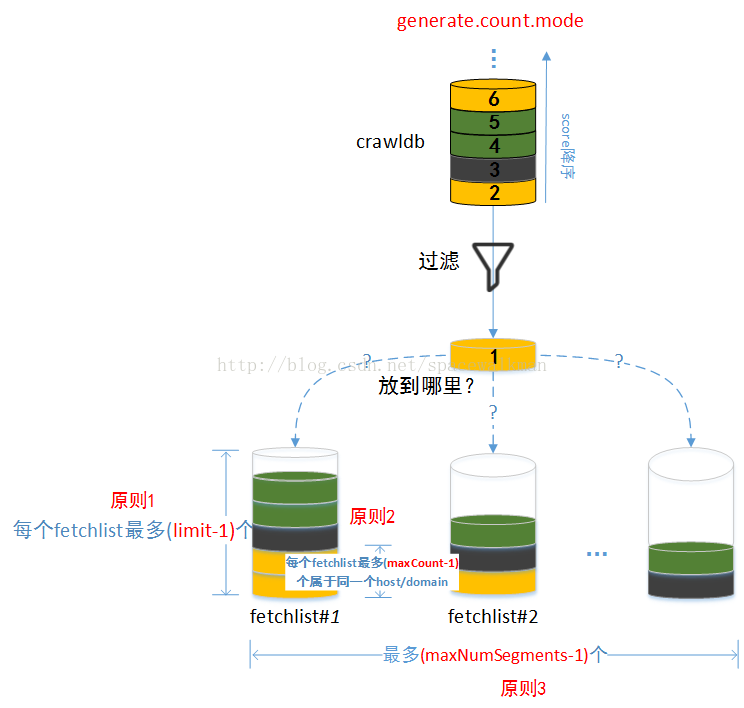
图17 generator需完成的任务示意图
图 17中,同种颜色代表是同一个domain/host的一个url,具体是domain还是host受generator.count.mode参数控制。generator.count.mode并不影响已经按照score排序之后的url之间的相对顺序,url仍然是按照score降序排序,它影响的只是对url的计数“视图”——即哪些url是属于同一个domain或者是host的。如图 18所示,由于属于相同domain的url可能属于不同的host,在generator.count.mode从byDomain切换成byHost之后,原来编号为5和6的url属于了不同的host。
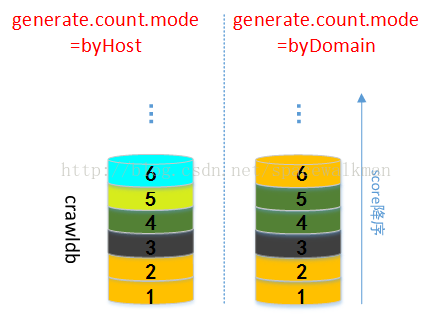
图18 generate.count.mode参数控制下对url的两种计数模式
maxNumSegments参数控制了总共只能生成多少个fetchlist,每个fetchlist里面有多少个url由参数limit控制,limit=topN/N,N为reducer个数。每个fetchlist里面同属于一个domain/host的url(受参数generator.count.mode控制)的url不能超过maxCount(由generate.max.count参数指定,默认为-1,表示不限制)。
如图 17所示,url取出之后,经过一系列“过滤”之后,需要将该url放置到其中一个fetchlist中,或者放到现有的任何一个fetchlist中都违背了上述约束,需要判断能否新建一个新的fetchlist。
考虑图 17中的情况,如果设置图中各参数如下:
limit=7,generate.max.count=3,generator.count.mode=byDomain,maxNumSegments=3,并且现有fetchlist已经加入了如图 18所示的url,针对图中情况,nutch按照图 19所示方式进行处理,主要步骤如下:
1) 从crawldb中取下一个url,如果所有url已经全部处理完,则结束。
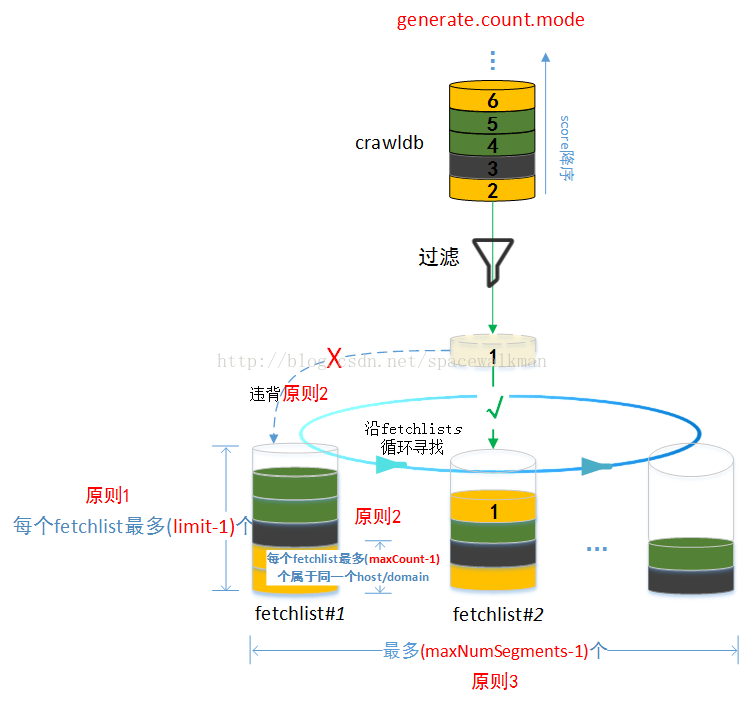
图19 url如何加入fetchlist示意图
2) 遍历现有的fetchlist,找到第一个不违背原则1和原则2的第一个fetchlist。如果能找到,则将该url加入到该fetchlist,然后转1),否则转3)。
3) 判断是否还能继续创建新的fetchlist(当前的fetchlist个数是否已经达到(maxNumSegments-1)个),如果没有,则新建一个fetchlist,将该url加入到该fetchlist中,如果已经达到,则跳过该url,转1)。
nutch采用了3个Job来处理,流程如下图所示:
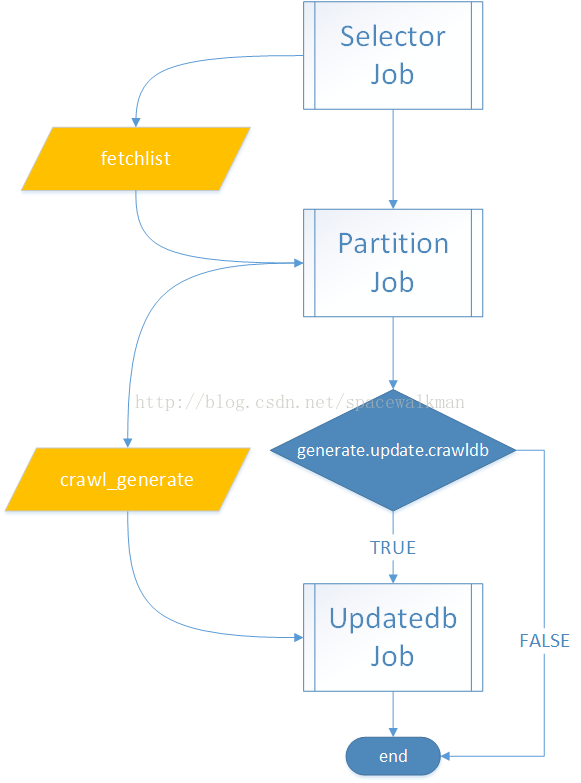
图20 generator采用了3个Job处理
1.1.4.1 Selector Job
1.1.4.1.1 相关数据结构分析
1) SelectorEntry
SelectorEntry其实就是一个简单的struct,里面封装了CrawlDatum、url和segnum(segment编号)。SelectorJob的核心任务就是给SelectorEntry的segnum赋值,即将url分配给相应的segment(记录segnum)。
为什么要使用自定义的SelectorEntry作为中间结果的value类型,而不使用CrawlDatum或者URL(Text)?
由于为了完成目标1) 和目标2),nutch需要同时对URL和CrawlDatum中的score进行读取,而仅仅有片面的URL或者是CrawlDatum都不能满足需要;另外,nutch需要在处理过程中记录每个URL应该划分到那个fetchlist,即segnum。虽然可以采用自定义的metadata key将该编号记录到CrawlDatum的metadata中,但是这样仅仅解决了segnum存储问题,仍然没有解决URL和score需要同时被访问的问题。
1.1.4.2 Partition Job
Partition Job的核心功能是inverse由SelectorEntry封装的URL和CrawlDatum,并对同一个fetchlist中来自于同一个domain/host的URL利用HashComparator进行“打散”,以实现目标5)。其关键性的部分如下:
private static int hash(byte[] bytes, int start, int length) {
int hash = 1;
// make later bytes more significant in hash code, so that sorting by hashcode correlates less with by-host ordering.
for (inti = length - 1; i >= 0; i--)
hash = (31 * hash) + (int) bytes[start + i];
return hash;
}1.1.4.3 Updatedb Job
Updatedb Job的主要职责是在CrawlDatum的MetaData中记录_ngt_(GENERATE_TIME_KEY)为执行,以防止在高并发的场景下(例如对上一次的fetchlist的爬取尚未完成,但是又进行再次执行generator时。PS: _ngt_标志会在updatedb完成之后被清除)。核心处理逻辑如下:
LongWritable oldGenTime = (LongWritable) crawlDatum.getMetaData() .get(Nutch.WRITABLE_GENERATE_TIME_KEY);
if (oldGenTime != null) {//表明上次已经对该url调用过generator了,该url已经在某个segment里面了,可能正在完成fetch->updatedb的过程当中
if (oldGenTime.get() + genDelay > curTime) // 表明尚未超过wait for update的过期时间
return;
}
至此,针对前面提到的为了保持“爬虫礼貌”而需要完成的目标,generator逐项制定了解决方案:
表3 generator保持“爬虫礼貌”的措施
| 目标1) | 对crawldb中的url按照CrawlDatum中的score从高到低降序排列(按照URL重要程度排序) |
| 目标2) | 可设置topN参数,根据reducer的个数计算出每个fetchlist最多不能超过limit个,其中limit=topN/N,N为reducer个数。 |
| 目标3) | 设置了generate.max.count和generate.count.mode可配置参数,后者控制在每个fetchlist中对url的计数方式,可取值byHost/byDomain/byIP,默认为byHost。每个fetchlist中url无论以何种方式计数,都不能>=generate.max.count个(即:最多只能generate.max.count-1个)。 |
| 目标4) | 设置了可配置参数partion.url.mode并且使用自定义的URLPartitioner,根据partion.url.mode的设置,可将属于同一个domain/host/ip的不同的URL shuffle到同一个reducer进行处理 |
| 目标5) | PartitionJob的采用HashComparator来将同一个domain/host的URL进行“hash”处理,使得这些URL在fetchlist中尽量打散。 |
| 目标6) | fetcher使用自定义的InputFormat,mapper处理fetchlist时,不再进行split。 |
另外还有nutch还有其他“礼貌”措施,包括:
1) 将hadoop job的spectaculative属性设置成false,对执行较慢的mapper,不让hadoop框架另外重启一个mapper来reRun该task。
2) 将fetcher的InputFormat的splittable设置成false,不进行拆分,避免拆分之后,同一个domain或者host下的url被并行爬取。参见fether部分。
1.1.5 FAQ
1.1.5.1 fetchlist与segment/crawl_generate是什么关系?
fetchlist是selector Job reducer的输出,是以HDFS临时文件的形式存在的,格式是SequenceFile,逻辑上是<FloatWritable,SelectorEntry>,在selector Job执行成功后会被删除;而segment是partitionJob的reducer的输出,partition Job执行成功后会生成segment/crawl_generate目录,该目录不会被删除。partition Job的输入正是fetchlist。可以说segment/crawl_generate是经过partition之后的fetchlist,在不引起歧义的情况下,2者其实可以通用。
1.1.5.2 每个reducer生成的fetchlist中究竟有多少个url?受哪些参数控制?
每个reducer能生成的fetchlist个数为maxNumSegments个,该参数由命令行传入。而每个fetchlist里面含有多少个url主要由参数topN和reducer的个数N控制,为limit=topN/N个,但是也受到generate.max.count和generate.count.mode参数控制,如果满足1)host/domain的种类足够多,并且2)crawldb中url个数足够多的话,每个fetchlist中URL的个数肯定能达到上限limit,generate.max.count和generate.count.mode参数只能控制里面url的分布而已。但是如果不满足这2个条件中任何一个的话,可能会出现fetchlist“装不满”的情况。
1.1.5.3 能否同时执行多个generator进程?generator执行时锁定crawldb的原因?
generator在执行之前会对Crawldb加锁,另一个generator执行时如果发现crawldb已经被锁定,会直接抛出IOException异常,故不能同时执行2个generator。
至于generator执行时锁定crawldb的原因,主要是考虑到generator本身存在更新crawldb的(写操作)可能性,即:generate.update.crawldb=true时。可能与nutch其他能够写crawldb的tool(例如injector和updatedb)有写冲突,而这种写冲突可能会造成crawldb损坏。如果 generate.update.crawldb=false,在不是高并发的情况下,generator可以不锁定crawldb,即使在高并发的情况下,也不会有损坏crawldb的可能性,但是由于HDFS对文件进行CRC校验,故crawldb存在“读写冲突”时,可能会出现HDFS报校验失败的问题,出现这种情况时,读进程重试即可。
参考文献
- 《Hadoop: The Definite Guide》 3rd,P567~580














 1436
1436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









