








前言:
首先是翻译的几篇有关memory reordering的文章,作者是一个老外,虽然文章是几年前的,但是很值得一读。
最近不知道写些什么东西,拿这个先凑几篇
其次有关什么memory ordering,memory reordering,memory model这些名词,可能很多时候直接e文,没有翻译,个人习惯。
Memory Reording Caught in Act
原文在这里:http://preshing.com/20120515/memory-reordering-caught-in-the-act/
MAY 5, 2012
当使用C或者C++编写lock-free的代码时,你必须特别小心的保证正确的内存顺序。否则的话,会遇到不少“惊喜”。
Intel在它们的x86/64体系结构规范的第三卷8.2.3节列举了几种这样的case。拿最简单的那个例子来说。假设在内存中有两个整数变量x和y,都初始化为0,两个并行运行的processor执行下面的机器码:

别被其中的汇编语言吓到,这其实是描述CPU执行顺序的最佳方式。每个processor将1保存到其中一个整形变量,然后将另外一个变量读取到一个register(这里r1和r2是表示x86 register的符号,比如eax)。
现在,无论哪个processor先把1写到内存,很自然我们期望另一个processor会把这个值读出来,也就是说,代码执行完后,我们应该得到的结果是:r1=1或者r2=1,或者r1和r2都是1。但是,根据Intel的规范,结果并不总是这样,规范说本例还有另外一种合法的结果:r1和r2都是0——一个违反直觉的结果。
因为像其它的处理器家族一样,Intel x86/64处理器在特定的规则下允许将内存指令重排序,只要不会改变单线程程序的执行(as long it never changes the execution of a single-threaded program)。
特别的,每一个processor都允许将一个store的影响推迟到任何读取其它内存的load之后(each processor is allowed to delay the effect of a store past any load from a different location)。结果就是,实际上可能根据如下的指令顺序来执行的:
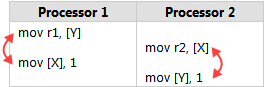
–>spark注:这里作者只是介绍了StoreLoad内存序,实际上基于store和load有4种内存序,这是CPU内存模型的主要部分,在后面的文章中会专门介绍。还有就是MOV r1, [y]实际上有两步:读y写r1;
以P1为例上面的操作实际上是三步:store x; load y; store r1;
Let’s Make It Happen
有人告诉你可能会出现这种结果也是不错的,但是还远不如亲眼看到这种结果。所以我写了一个小程序来说明这种乱序确实会发生,源代码在这里。
示例代码包括Win32和POSIX两个版本,它创建两个工作线程,无限重复上面的事务,然后主线程同步并检查它们的结果。
这是第一个工作线程的代码。X, Y, r1和r2都是全局变量,POSIX信号量用于协调每次循环的开始和结束。
sem_t beginSema1;
sem_t beginSema2;
sem_t endSema;
int X, Y;
int r1, r2;
void *thread1Func(void *param) {
MersenneTwister random(1);
for (;;) {
sem_wait(&beginSema1); // Wait for signal
while (random.integer() % 8 != 0) {} // Random delay
// ----- THE TRANSACTION! -----
X = 1;
asm volatile("" ::: "memory"); // Prevent compiler
r1 = Y;
sem_post(&endSema); // Notify transaction complete
}
return NULL; // Never returns
};这段代码在每次事务之前加了一个随机的短暂延迟,这是为了让线程的运行时间交错。记住,一共有两个工作线程,我们要试着让它们的指令执行产生重叠。随机延迟是使用的是前面几篇文章中中实现的MersennelTwister,比如measuring lock contention。
注spark:这里不需要关注这个MersennelTwister,其实直接使用rand()函数也是一样的,在 main中srand(time(0));测试结果不变,而且碰撞的概率更高。
也不要被代码中的asm volatile吓到,这只是告诉GCC编译器在生成机器码时不要重排store和load操作的指令顺序,防止它在优化时搞什么我们不想要的花样。我们可以检查汇编代码来验证这一点,比如下面的代码片段。如同所期望的那样,store和load指令是期望的顺序。后面的指令将保存结果的register eax写回到了全局变量r1。
$ gcc -O2 -c -S -masm=intel ordering.cpp
$ cat ordering.s
...
mov DWORD PTR _X, 1
mov eax, DWORD PTR _Y
mov DWORD PTR _r1, eax
...主线程代码如下,就是一个管理工作。它在初始化之后无限循环,每次循环之前将X和Y重置为0。
特别注意程序是如何让写共享内存发生在sem_post之前的,以及让所有读共享内存发生在sem_wait之后的。工作线程和主线程之间的通信也采用了同样的机制。
在所有平台上,Semaphores都给我们提供了acquire-release语义,这个后面会仔细分析。这就意味着,我们保证X=0和Y=0的初始化结果会完整的传播给工作线程,r1和r2的结果都会完整的传播回来。换句话说,semaphores防止我们程序框架的memory reordering,让我们专注于测试StoreLoad reordering的情况。
int main() {
// Initialize the semaphores
sem_init(&beginSema1, 0, 0);
sem_init(&beginSema2, 0, 0);
sem_init(&endSema, 0, 0);
// Spawn the threads
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, thread1Func, NULL);
pthread_create(&thread2, NULL, thread2Func, NULL);
// Repeat the experiment ad infinitum
int detected = 0;
for (int iterations = 1; ; iterations++) {
// Reset X and Y
X = 0;
Y = 0;
// Signal both threads
sem_post(&beginSema1);
sem_post(&beginSema2);
// Wait for both threads
sem_wait(&endSema);
sem_wait(&endSema);
// Check if there was a simultaneous reorder
if (r1 == 0 && r2 == 0) {
detected++;
printf("%d reorders detected after %d iterations\n",
detected, iterations);
}
}
return 0; // Never returns
}运行结果显示,发生了很多次的重排序,也就是结果r1和r2都是0:
注spark:下面都是我自己的测试结果。
1 reorders detected after 1 iterations
2 reorders detected after 2 iterations
3 reorders detected after 3 iterations
... ...
31 reorders detected after 799 iterations
32 reorders detected after 1058 iterations而且可以看出概率相当的高,简直是必现,我这里是Mac系统,Intel Core i5处理器;
换到Linux继续测试,Intel x86_64处理器,概率相对低一些:
1 reorders detected after 4760 iterations
2 reorders detected after 6671 iterations
3 reorders detected after 8859 iterations
4 reorders detected after 12980 iterations好了,我们当然期望能消除这种乱序。至少有两种方法可以做到,一个是设置线程的CPU亲缘性,这样两个线程都运行在同一个CPU core上,在Linux:
cpu_set_t cpus;
CPU_ZERO(&cpus);
CPU_SET(0, &cpus);
pthread_setaffinity_np(thread1, sizeof(cpu_set_t), &cpus);
pthread_setaffinity_np(thread2, sizeof(cpu_set_t), &cpus);因为单个processor看到自己的操作肯定不会是乱序的,即使在线程被任意次的抢占和重新调度但。很显然,这并不是好方法。
—>spark注:
可以再引申一下:
在单processor下,下面的执行顺序都是合法的:
1 线程1:x = 1; r2 = y; -> 线程2:r1 = x; y = 1;
仅仅线程2中顺序重排,不违反原则,对x的reads没有和线程1中的写x=1重排序;
2 线程1:r2 = y; x = 1; -> 线程2:y = 1; r1 = x;
仅仅线程1中顺序重排,不违反原则,对y的reads没有和线程2中的写y=1重排序;
单processor上,对同一地址的loads不能提前到它前面的stores而先执行,这应该是所有CPU体系结构的共同原则,否则就是错误!所以将这两个线程绑定在同一个processor上不会再出现r1和r2都是0的情况。
<—over
一个相关的note,在PlayStation3上,没有检测到内存乱序。这显示(但并不能确定)两个PPU内的硬件线程可能像单一的processor在运行,有很细粒度的硬件调度。
Preventing It With a StoreLoad Barrier
另外一个方法就是在两个操作之间引入CPU barrier,这里我们要防止store和它后面的load指令重排。用通常的barrier说法就是,我们需要一个StoreLoad barrier。
虽然x86/64处理器没有专门的用作StoreLoad barrier的指令,但是有好几个指令包含了StoreLoad的功能,并且还可以做得更多。mfence指令是一个全内存barrier,它防止任何情况下的memory reordering,在GCC下,代码可以这样写:
for (;;) { // Loop indefinitely
sem_wait(&beginSema1); // Wait for signal from main thread
while (random.integer() % 8 != 0) {} // Add a short, random delay
// ----- THE TRANSACTION! -----
X = 1;
asm volatile("mfence" ::: "memory"); // Prevent memory reordering
r1 = Y;
sem_post(&endSema); // Notify transaction complete
}再次查看汇编代码验证:
...
mov DWORD PTR _X, 1
mfence
mov eax, DWORD PTR _Y
mov DWORD PTR _r1, eax
...Similar Instructions and Different Platforms
有趣的是,mfence不是x86/64上唯一可以用作full memory barrier的指令,在这些处理器上,任何锁指令,比如xchg,也可以用作full memory barrier——当你不使用SSE指令或者写组合内存时。实际上至少在VS2008之前,当你使用MemoryBarrier时,Microsoft C++生成的都是xchg指令~~~
而mfence指令是x86/64特有的,如果你希望跨平台,就需要自己自己wrap一个。Linux内核wrap了一个smp_mb的宏,类似的还有smb_rmb和smp_wmb。比如在PowerPC上,smp_mb就是sync。
所有不同的CPU家族,都有自己的强制memory ordering的指令,每一个跨平台的项目都需要实现自己的跨平台代码库,这显然不是一个轻松的事情。这也是为什么C++11引入了atomic库标准,这会简化编写可移植lock-free代码的工作量。
评论摘选
文章有些评论很不错,这条是来自于Bruce Dawson:
非常不错——写测试代码来验证是不错的注意。
我想对本文提出一点修正和解释。
修正之处就是:reads/writes的重排序和指令重排序是正交的(没有必然联系)。Xbox360 CPU不会做指令重排序,但是底层的reads/writes却会重排序。实际上相比Xbox360这种有序的CPU,Intel/AMD这些out-of-oder的CPUs上对read/write的重排序还少很多。
这种情况下,在光速有限的宇宙中,任何多核系统中reordering都是不可避免的。如果两个processor同时write 1,期望它们可以在下一个指令就可以看到彼此的write是不切实际的。实际上,这个write传播到其它core可能需要花费数十个CPU周期。任何防止这种重排序的系统,它的运行速度不可能超过100MHz,甚至更慢。因为一个它必须不断的等待其它core的signal(等待其它core对write的响应)。
—->spark注:多说一点,现代CPU为了提升执行速度,通常都会采用多级cache,每个core都会自己的一级cache。由于这些cache的存在,读写的reordering是难以避免的,相比指令乱序,它是导致memory reordering的更主要的原因。
正如Bruce Dawson所说的:
如果要保持各个core的cache之间严格一致,那么每次更新都要等待其它core的响应。这样的话,CPU的速度就不然被限制了。














 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









