









 本文详细介绍了斐波那契堆的结构和特性,对比了与二叉堆、二项堆的区别。斐波那契堆在insert、minimum、union、decrease-key等操作上的时间复杂度有所优化,但在实际应用中,由于常熟因子和操作复杂性,可能并非总是首选。文章还阐述了如何创建、插入、查找最小节点、合并、取出最小元素、减少元素值和删除节点等操作,强调了斐波那契堆在平摊复杂度上的优势。
本文详细介绍了斐波那契堆的结构和特性,对比了与二叉堆、二项堆的区别。斐波那契堆在insert、minimum、union、decrease-key等操作上的时间复杂度有所优化,但在实际应用中,由于常熟因子和操作复杂性,可能并非总是首选。文章还阐述了如何创建、插入、查找最小节点、合并、取出最小元素、减少元素值和删除节点等操作,强调了斐波那契堆在平摊复杂度上的优势。
堆的变体:
- 斐波那契堆
前面的博客中我们讲到的堆的两种变体,二叉堆和二项堆,今天我们要讲的就是著名的斐波那契堆。
依然首先列出了三种堆的时间复杂的比较。
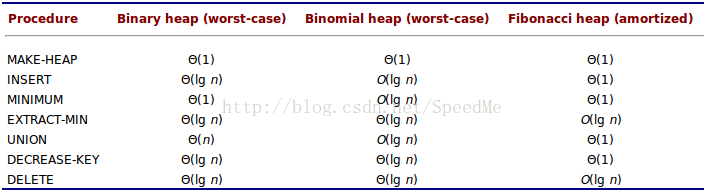
从上面能发现斐波那契堆的时间复杂度在很多操作上有优化,如insert, minimum, union , decrease-key,而extreact-min,delete没有变化。
可能看到这很多人会说为什么有这么好的斐波那契堆,我们还要去研究其他堆呢,确实,理论上来讲,对于extreact-min和delete操作想对于其他操作少的情况下,斐波那契堆确实提高了很大的效率。
但是实际中,除了某些需要管理大量数据的应用外,对于大多数应用,斐波那契堆的常熟因子和变成复杂性使得它比起普通二项堆并不是那么使用。
二项堆和斐波那契堆对于search操作的支持均比较低效;可能花费一段时间才能找到关键字。为此,涉及给定元素的操作(如DECREASE-KEY和DELETE)均需要一个指针指向这个元素,并且指针作为输入的一部分。
Fibonacci Heap(简称F-Heap)是一种基于二项堆的非常灵活的数据结构。它与二项堆不同的地方在于:
1)root list和任何结点的child list使用双向循环链表,而且这些lists中的结点不再有先后次序(Binomial Heap中root list的根结点按degree从小到大顺序,child list的结点按degree从大到小顺序);
2)二项堆中任何一颗Binomial Tree中根结点的degree是最大的,而F-Heap中由于decrease-key操作(cut和cascading cut)的缘故,并不能保证根结点的degree最大;
3) 二项堆中任何结点(degree等于k的)为根的子树中,结点总数为2^k;F-Heap中相应的结点总数下界为F{k+2},上界为2^k(如果没有 Extract-Min和Delete两类操作的话)。其中F{k+2}表示Fibonacci数列(即0,1,1,2,3,5,8,11...)中第 k+2个Fibonacci数,第0个Fibonacci数为0,第1个Fibonacci数为1。注意不像二项堆由二项树组成那样,F-Heap的 root list中的每棵树并不是Fibonacci树(Fibonacci树属于AVL树),而F-Heap名称的由来只是因为Fibonacci数是结点个数 的一个下界值。
4)基于上面的区别,若F-Heap中结点总数为n,那么其中任何结点(包括非根结点)的degree最大值不超过 D(n) = floor(lgn/lg1.618),这里1.618表示黄金分割率(goldren ratio),即方程x^2=x+1的一个解。所以在Extract-Min的consolidate操作之后,root list中的结点最多有D(n)+1。而二项堆中degree最大值不超过floor(lgn),从而root list中最多有floor(lgn)+1颗二项树。
5)另外一个与二项堆的最大不同之处在于:F-Heap是一种具有平摊意义上的高性能 数据结构。除了Extract-Min和Delete两类操作具有平摊复杂度O(lgn),其他的操作(insert,union,find- min,decrease-key)的平摊复杂度都是常数级。因此如果有一系列的操作,其中Extract-min和delete操作个数为p,其他操作 个数为q,p<q,那么总的平摊复杂度为O(p + q.lgn)。达到这个复杂度的原因有以下几点,第一,root list和任何结点的child list中使用了双向循环链表;第二,union和insert操作的延迟合并,从而在所有的可合并堆中,F-heap的合并开销O(1)最小的;第 三,decrease-key中cut和cascading cut的巧妙处理(即任何非根结点最多失去一个孩子)。
1. 斐波那契堆的结构
typedef int Type;
typedef struct _FibonacciNode
{
Type key; // 关键字(键值)
int degree; // 度数
struct _FibonacciNode *left; // 左兄弟
struct _FibonacciNode *right; // 右兄弟
struct _FibonacciNode *child; // 第一个孩子节点
struct _FibonacciNode *parent; // 父节点
int marked; //是否被删除第1个孩子(1表示删除,0表示未删除)
}FibonacciNode, FibNode;FibNode是斐波那契堆的节点类,它包含的信息较多。key是用于比较节点大小的,degree是记录节点的度,left和right分别是指向节点的左右兄弟,child是节点的第一个孩子,parent是节点的父节点,marked是记录该节点是否自从上一次成为另一个结点的孩子后,是否失去过孩子。true表示是去过,被标记(marked在删除节点时有用)。
typedef struct _FibonacciHeap{ int keyNum; // 堆中节点的总数 int maxDegree; // 最大度 struct _FibonacciNode *min; // 最小节点(某个最小堆的根节点) struct _FibonacciNode **cons; // 最大度的内存区域 }FibonacciHeap, FibHeap;
FibHeap是斐波那契堆对应的类。min是保存当前堆的最小节点,keyNum用于记录堆中节点的总数,maxDegree用于记录堆中最大度,而cons在删除节点时来暂时保存堆数据的临时空间。
一个斐波那契堆是一系列具有最小堆序(min-heap ordered)的有根树的集合。也就是说,每棵树遵循最小堆性质:每个结点的关键字大于或等于它的父节点的关键字,如下图:


2. 可合并堆操作
2.1 创建一个斐波那契堆
类似于二项堆的操作,分配并返回一个Fib对象H,取H.n = 0 , H.min = NIL ,H中没有树。花费为O(1).
2.2 插入一个结点
下面的代码是插入结点x到斐波那契堆H中,假设该结点已经被分配,并且x被赋值。时间复杂度:O(1)

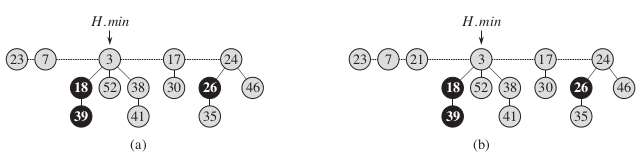
如上图中,插入结点x.key=21。
1-4:初始化结点x
5-7:如果斐波那契堆为空,那么就直接将x结点插入H堆中的根链表,并且H.min指向x结点
8-10:H不为空时,首先将结点x插入到H堆中的根链表中,将x与堆中最小元素做比较,如果更小,则H.min指向x,否则不做任何改变。最后n加一。
2.3 找到最小节点
不同于二项堆,斐波那契堆有一个指向最小结点的指针,所以操作复杂度为O(1).
2.4 合并两个斐波那契堆
下面的代码中表示合并两个斐波那契堆H1和H2,并且摧毁H1和H2。要做的仅仅是将他们的根链表结合起来,并且确定新的最小的元素。复杂度:O(1)

2.5 取出最小元素
这个操作是本节内最复杂的一个了。 操作复杂度为O(lgn).先看

3-6:将最小结点的孩子存入到根链表中,并且从链表中删除z
7-8:如果z的右兄弟等于z的话,说明z没有孩子,且原堆中只有z一个结点,则删除z后为空。
9-11:如果不止z一个的话,那么将H.min随意指向链表中的一个元素,不一定要是链表中最小的,然后执行CONSOLIDATE(H)
对于取出最小结点的整体操作我们知道了,但对于CONSOLIDATE(H)的具体操作还完全不知,下面我们就来介绍他。
CONSOLIDATE过程要做的工作是:使每个度数的二项树唯一,也就是使每个根都有一个不同的degree值为止。对根表的合并过程是反复执行下面的步骤:
1)在根表中找出两个具有相同度数的根x和y,且key[x] <= key[y].
2) 将y链接到x:将y从根表中移出,成为x的一个孩子。这个过程由FIB-HEAP-LINK完成。
首先看伪代码:

解释下上面的伪代码:
1-3:初始化一个数组A,其中D(H.n)=lgn,因为我们要使得每个根的度数唯一,而根最多有度数最大为lgn
4-14:使得链表中的树根度数唯一
15-23:重新建立一个树根表,保存数组A[i]中的根结点,并且找出最小的元素用H.min指向该元素。
可能单纯根据伪代码还很难理解,下面我们根据具体流程图来分析。
他的操作流程可以参照下图。
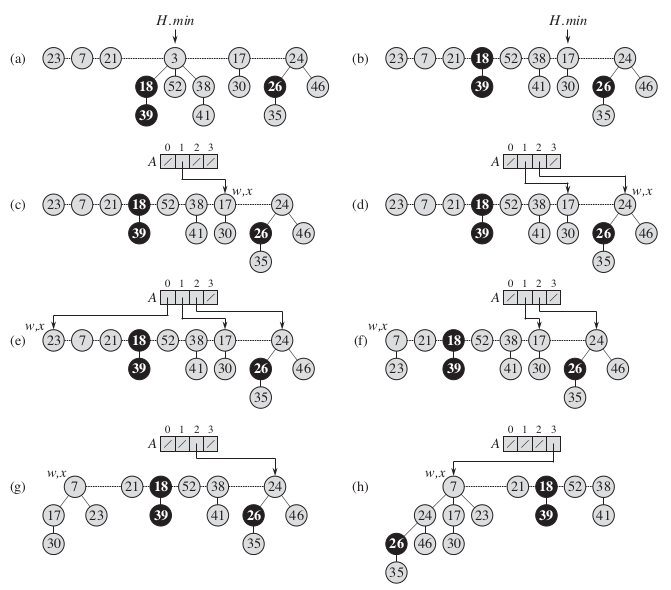
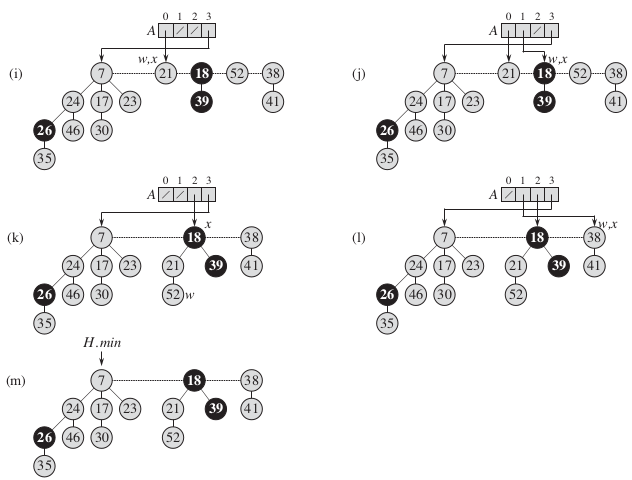
a-b:就是删除最小元素3,并且将他的孩子存入根链表中
c-k:从H.min指向的根结点开始向右遍历,并按照其度数存入对应的数组A中的位置,当所存入的位置不为空,则说明存在相同度数的根结点,于是就执行FIB-HEAP-LINK操作,将他们结合起来,然后继续遍历。
l-k:找出链表中最小的元素,H.min指向该元素。
2.6 减少元素的值
下面的伪代码是将x节点的值减少到k

5-7:当节点减少后的值小于他的父节点,那么就要进行调整,首先是执行CUT(H,x,y)操作,即将x节点放到根链表中。然后执行CASCADING-CUT(H,y)操作,即使得斐波那契堆中的树不是那么不像二项树。下面是对该操作的详细解释:
- 由于增加了删除和关键字减值操作,所以,F堆中的最小树就不一定必须是二项树了。事实上,可能存在度为k却只有k + 1(一棵所有叶子节点的)个结点的最小树。为了保证每个度为k的最小树至少包含ck个结点(c > 1), 每次执行删除操作和关键字减值操作后,还必须进行级联剪枝操作。为此,为每个结点增加一个布尔类型的child_cut域(即本文里的marked)。child_cut域的值仅对那些不是最小树树根的结点有意义。对于不是最小树树根的结点x, x的child_cut域为TRUE,当且仅当在最近一次x成为其当前父结点的儿子之后,x的一个儿子被删除。这就意味着,在执行删除最小元素中,每次连接两棵最小树时,关键字值较大的根结点的child_cut域应该赋值为FALSE。更进一步地说,一旦删除操作或关键字减值操作将最小树的非根结点q从其所在双向链表中删除时,则调用级联剪枝操作。在执行级联剪枝操作过程中,检查从被删除结点q的父节点p开始,到被删节点的最近的child_cut域为FALSE的祖先结点的路径。对在该路径上所有child_cut域为TRUE的非根结点,将其从所在的双向链表中删除,并将其加入到F堆的最小树的根节点组成的双向链表中。如果该路径上存在child_cut域为FALSE的结点 ,则将其该域的值修改为TRUE。
下图中是上面代码中的操作流程。
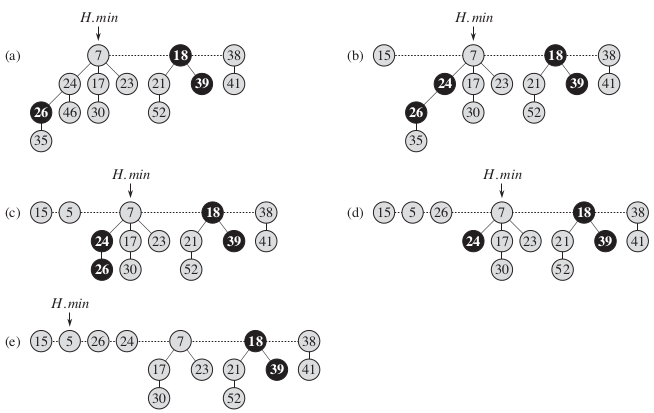
2.7 删除节点
跟二项堆一样,也是利用到前面的两个操作。直接上代码了。
reference:
http://www.cs.princeton.edu/~wayne/teaching/fibonacci-heap.pdf


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









