







践踏堆栈-缓冲区溢出漏洞
打算写这篇文章是因为在网上看过一篇论文,讲了缓冲区溢出破坏堆栈来执行恶意程序的漏洞。该论文请见参考资料1。这篇文章会涉及一些汇编的基础知识,以及虚拟内存的一些基本概念等。当然用来调试程序的系统是linux,工具是gcc。很久没有看过汇编和C语言了,错漏之处,还请指正。
1.概要
文章标题有提到堆栈和缓冲区,那么就先来探讨下这几个名词的定义。这里的缓冲区,指的就是计算机内一块连续的内存区域,可以保存相同数据类型的多个实例。C程序员最常见的缓冲区就是字符数组了。与C语言中其他变量一样,数组也可以声明为静态或动态的,静态变量在程序加载时位于数据段,动态变量位于堆栈之中(这一点我们可以很容易的写个程序来验证,见exmple1.c,使用命令gcc -m32 -S example1.c将其编译成32位汇编代码,查看example1.s即可看到数组a的数据分布在数据段中,而数组b的数据则分布在堆栈中)。本文只探讨动态缓冲区的溢出问题,即基于堆栈的缓冲区溢出。
exapmle1.c
-------------------------------
int main()
{
static int a[4] = {1, 2, 3, 4};
int b[4] = {5, 6, 7, 8};
}
2.基础知识
2.1 进程内存组织形式
既然本文要讨论基于堆栈的缓冲区溢出,首先就来看看进程的内存组织结构。我们基本都知道,进程在内存中的结构可以简单的分为代码段,数据段和堆栈段。代码段位于内存低地址,而堆栈位于内存高地址。当然我们这里说的内存地址是指虚拟地址,具体物理地址是需要经过MMU(内存管理单元)进行转换得到。下面是一个进程的内存组织结构图:
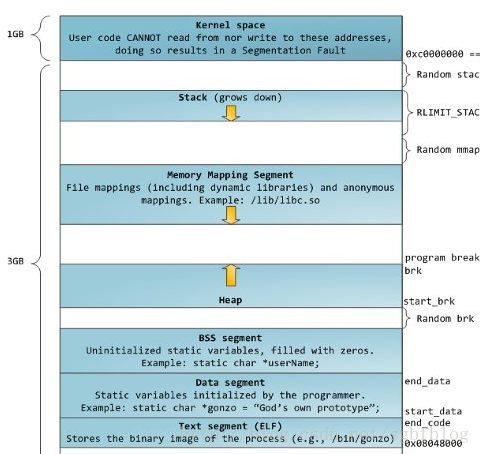
图2.1 进程的内存组织结构图
从图2.1中可以看到,除了基本的代码段,数据段,还有未初始化数据段bss,堆heap,内存映射区域等。当然我们这里的段的概念跟程序加载时的段是不一样的,具体区别可以参见《Linux C一站式编程》18.5 ELF文件格式那一节的说明。
2.2 堆栈
堆栈是一种计算机中常用的抽象数据模型,其特征就是先进先出,支持的操作主要就是PUSH和POP。PUSH操作是在堆栈顶部压入一个元素,而POP操作则是弹出堆栈的顶部元素。
为什么会使用堆栈则是跟现代计算机设计相关。在高级编程语言如C语言,JAVA语言,PYTHON语言等编写程序时,经常会用到函数(function)或者过程(procedure)。通常,一个函数调用可以像跳转命令那样改变程序的执行流程,而函数执行完毕后,又需要把控制权返回给函数之后的代码指令,这种实现需要依靠堆栈来实现。当然在函数的局部变量中,以及函数传递参数和返回值中都要用到堆栈。
堆栈是一块连续的内存区域,堆栈既可以向上也可以向下增长,这个依赖于具体实现。在大部分的处理器如Intel,Motorola,SPARC和MIPS中,堆栈都是向下增长的,即堆栈指针SP指向堆栈的顶部,堆栈底部是一个固定的地址,堆栈大小在运行时由内核动态调整。CPU实现指令PUSH和POP,向堆栈中添加和移除元素。
除了堆栈指针SP,为了方便还有一个指向帧内固定地址的指针BP。从理论上来说,局部变量可以通过SP加偏移量来引用,然而,当有字被压入栈和出栈后,这些偏移就变化了。尽管有些情况下编译器能够跟踪栈内的操作变化,修正偏移量,但是还有很多情况不能跟踪,而且为了跟踪偏移量的变化需要引入额外的管理开销。因此很多编译器会使用第二个寄存器BP,局部变量和函数参数都可以引用它,因为局部变量和函数参数到BP的距离不受PUSH和POP操作的影响。
2.3 函数调用中栈帧分析
为了利用缓冲区溢出,需要知道函数调用中栈帧变化和布局情况,这里就不分析了,已经有很好的文章详细说过这个问题,参见宋劲松老师的《linux C一站式编程》19.1节函数调用。
3.缓冲区溢出
好了,做了一些准备工作后,可以来看看这个缓冲区溢出的问题了。 首先看下面的代码example1.c,我们分析下函数栈帧的分布。
example1.c
--------------------------------------------------
void function(int a, int b, int c) {
char buffer1[5];
char buffer2[10];
}
void main() {
function(1,2,3);
}运行命令:gcc -S -fno-stack-protector example1.c,通过分析example1.s文件得出 函数栈帧分布如下所示(我的运行环境是32位的ubuntu11.04):
| 栈帧分布 |
| c (高地址) |
| b |
| a |
| ret(返回地址) |
| ebp |
| buffer1 |
| buffer2 (低地址) |
接下来看一个通过覆盖返回地址造成段错误的情况。见example2.c。
example2.c
---------------------------------------
void function(char *str) {
char buffer[16];
strcpy(buffer,str);
}
void main() {
char large_string[256];
int i;
for( i = 0; i < 255; i++)
large_string[i] = 'A';
function(large_string);
}example2.c是一个典型的缓冲区溢出的例子,strcpy拷贝的数据超过了16个字节,导致溢出代码覆盖了栈中保存的ebp值以及返回地址ret,而函数返回时会从栈中取返回地址ret接着执行下一条指令,该地址不合法,从而导致段错误。而如果用一个合法地址来覆盖返回地址ret,这样就可以修改程序执行流程了。
接下来,修改example1.c,通过缓冲区溢出修改返回地址ret来修改程序执行流程。如example3.c所示。
example3.c
--------------------------------
void function(int a, int b, int c)
{
int *ret;
char buffer1[5];
char buffer2[10];
ret = buffer1 + 13;
(*ret) += 8;
}
void main()
{
int x = 0;
function(1,2,3);
x = 1;
printf("%d\n", x);
}使用命令gcc -o example3 -fno-stack-protector example3.c编译,可以看到栈帧分布如下所示:
| 栈帧分布| | ------------ | | c (高地址)| | b | | a | | ret(返回地址) | | ebp | | ret (局部变量ret)| | buffer1 | | buffer2 (低地址)| 因此,通过ret=buffer1+13,可以获得返回地址ret的地址。这里之所以加13,是buffer1的5字节+局部变量ret的4字节+ebp的4字节。调用function函数后,返回地址本应该是x=1指令地址,(*ret) += 8将返回地址ret加8,这样就跳过了x=1这条指令,example3.c编译后执行的结果是0。注意必须加上-fno-stack-protector,因为gcc默认存在堆栈保护技术,那样会防止返回地址被改写,如果返回地址被恶意修改,会报段错误。GCC编译器堆栈保护技术详见该文链接。
接下来可以通过缓冲区溢出来执行shell代码,这个留待下一篇文章再说了,内容太长,现在还没有看完。














 251
251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









