







后缀树简介:后缀树,就是把一串字符的所有后缀保存并且压缩的字典树。相对于字典树来说,后缀树并不是针对大量字符串的,而是针对一个或几个字符串来解决问题,
比如字符串的回文子串,两个字符串的最长公共子串等等,后面应用会说。
性质:一个字符串构造了一棵树,树中保存了该字符串所有的后缀。
操作:就是建立和应用。
1.建立后缀树
比如单词banana,它的所有后缀显示到下面的。1代表从第一个字符为起点,终点不用说都是字符串的末尾。

以上面的后缀,我们建立一颗后缀树。如下图,为了方便看到后缀,我没有合并相同的前缀
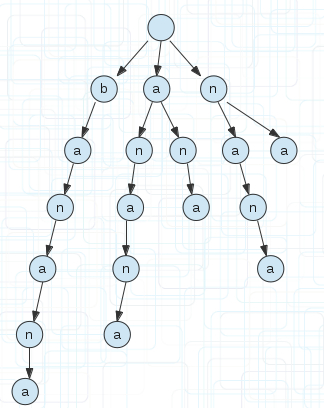
(3)
基于之前前缀树的学习,可写出插入后缀树代码的编写
void SInsert(TrieNode *root , char *word){//后缀树插入
int length =strlen(word);
for(int i=0;i<length;i++){
char *a=word+i;
Insert(root, a);
}
}
void Insert(TrieNode *root , char *word)
{
TrieNode *location=root;
while(*word){
if(location->next[*word-'a']==NULL){
TrieNode *newNode=new TrieNode();
newNode->isStr=false;
memset(newNode->next,NULL,sizeof(newNode->next));//初始化
location->next[*word-'a']=newNode;
}
location=location->next[*word-'a'];//location指向字符串在前缀树中下一个位置
word++; //当前字符在字符串中位置
}
//字符串已经全部添加到前缀树
//标识前缀树到该节点位置为完整字符串
location->isStr=true;
} 前面简介的时候我们说了,后缀树是把一个字符串所有后缀压缩并保存的字典树。
压缩一会再说,简介里面说了是字典树,所以我们把字符串的所有后缀还是按照字典树的规则建立,就成了上图(3)的样子。
注意还是和字典树一样,根节点必须为空。
下面说下更加节省空间的方案,也就是上面提到的压缩。
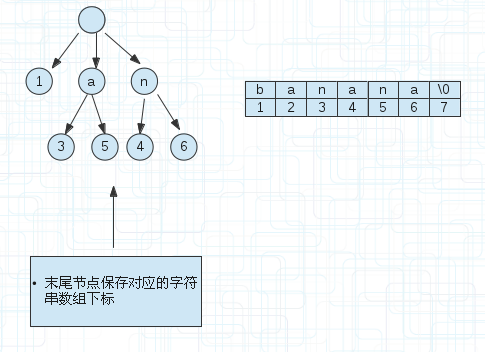
(4)
因为有些后缀串可能是单串,并不和其他的共用同一个前缀。
比如图(4)的banana这个后缀串,直接可以用1来表示起点,终点是默认的。
图(4)的a节点后面有两个节点标记3和5是右边字符数组的下标,对应着a->3-7,a->5-7。因为a是共有的前缀。
2.重点说下后缀树的应用,它能解决大多数字符串的问题
<1.查找某个字符串s1是否在另外一个字符串s2中
这个很简单,如果s1在字符串s2中,那么s1必定是s2中某个后缀串的前缀。
理解以下后缀串的前缀这个词,其实每个后缀串也就是起始地点不同而已,前缀也就是从开头开始结尾不定。
后缀串的前缀就可以组合成该原先字符串的任意子串了。
比如banana,anan是anana这个后缀串的前缀。
代码
bool qianzhuiSearch(TrieNode *root , char *word)
{
int length =strlen(word);
TrieNode *location=root;
for(int i=0;i<length;i++){
if(location->next[*word-'a']==NULL){
return 0;
}
else {
location=location->next[*word-'a'];
word++;
}
}
return 1;
}
<2.指定字符串s1在字符串s2中重复的次数
看图(3),比如说banana是s1,an是s2,那么计算an出现的次数实际上就是看an是几个后缀串的前缀。
上图的a节点是保存所有起始为a字母的后缀串,我们看a字母后的n字母的引用计数即可。
核心代码
int ncount(TrieNode *location, int &count){
if(location->isStr==true){ //如果这个点是一个后缀字符串,count++
count++;}
for(int i=0;i<26;i++){
if(location->next[i]!=NULL){
TrieNode *now=location; //定义一个now是此代码核心,不能直接用location,因为是它是指针,会影响后续循环递归的过程
now=now->next[i];
count=ncount(now, count); //递归
}
}
return count;
}
int countqianzhuiSearch(TrieNode *root , char *word)
{
int length =strlen(word);
TrieNode *location=root;
for(int i=0;i<length;i++){ //找到以“需要计数的字符串”为头后缀树,然后以此向后查找后缀树数,就是重复数
if(location->next[*word-'a']==NULL){
return 0;
}
else {
location=location->next[*word-'a'];
word++;
}
}
int count=0;
TrieNode *now=location;
count=ncount(now, count);
return count;
}
#include<iostream>
#include<string>
using namespace std;
#define MAX 26 //字符集大小
class TrieNode{
public:
bool isStr; //标识是否是一个完整的字符串
TrieNode *next[MAX];
};
/*插入*/
void Insert(TrieNode *root , char *word)
{
TrieNode *location=root;
while(*word){
if(location->next[*word-'a']==NULL){
TrieNode *newNode=new TrieNode();
newNode->isStr=false;
memset(newNode->next,NULL,sizeof(newNode->next));//初始化
location->next[*word-'a']=newNode;
}
location=location->next[*word-'a'];//location指向字符串在前缀树中下一个位置
word++; //当前字符在字符串中位置
}
//字符串已经全部添加到前缀树
//标识前缀树到该节点位置为完整字符串
location->isStr=true;
}
//查找
bool Search(TrieNode *root , char *word)
{
TrieNode *location=root;
while(*word&&location!=NULL){
location=location->next[*word-'a'];
word++;
}
return(location!=NULL&&location->isStr );
}
//前缀查找
bool qianzhuiSearch(TrieNode *root , char *word)
{
int length =strlen(word);
TrieNode *location=root;
for(int i=0;i<length;i++){
if(location->next[*word-'a']==NULL){
return 0;
}
else {
location=location->next[*word-'a'];
word++;
}
}
return 1;
}
int ncount(TrieNode *location, int &count){
if(location->isStr==true){ //如果这个点是一个后缀字符串,count++
count++;}
for(int i=0;i<26;i++){
if(location->next[i]!=NULL){
TrieNode *now=location; //定义一个now是此代码核心,不能直接用location,因为是它是指针,会影响后续循环递归的过程
now=now->next[i];
count=ncount(now, count); //递归
}
}
return count;
}
int countqianzhuiSearch(TrieNode *root , char *word)
{
int length =strlen(word);
TrieNode *location=root;
for(int i=0;i<length;i++){ //找到以“需要计数的字符串”为头后缀树,然后以此向后查找后缀树数,就是重复数
if(location->next[*word-'a']==NULL){
return 0;
}
else {
location=location->next[*word-'a'];
word++;
}
}
int count=0;
TrieNode *now=location;
count=ncount(now, count);
return count;
}
void Delete(TrieNode *location){
for(int i=0;i<MAX;i++){
if(location->next[i]!=NULL){
Delete(location->next[i]);
}
}
delete location;
}
void SInsert(TrieNode *root , char *word){//后缀树插入
int length =strlen(word);
for(int i=0;i<length;i++){
char *a=word+i;
Insert(root, a);
}
}
int main(){
//初始化前缀树的根节点,注意这里结构体指针的初始化
TrieNode *root=new TrieNode();
root->isStr =false;
//前缀树中每一个节点的下一个节点,分配空间,注意memset的使用
memset(root->next,NULL,sizeof(root->next));
SInsert(root,"banananana");//后缀树插入
//Insert(root,"bcd");
//Insert(root,"xyz");
//Insert(root,"abcdef");
//if(qianzhuiSearch(root,"bcf"))//用来查找某个字符串s1是否在另外一个字符串s2
// cout<<"exist"<<endl;
//else
// cout<<"no exist"<<endl;
int z=countqianzhuiSearch(root,"ban");
cout<<z;
Delete(root);
}
先说下广义后缀树,前面说了后缀树可以存储一个或多个字符串,当存储的字符串数量大于等于2时就叫做广义后缀树。
<3.两个字符串S1,S2的最长公共部分(广义后缀树)建立一棵广义后缀树,如下图(5)
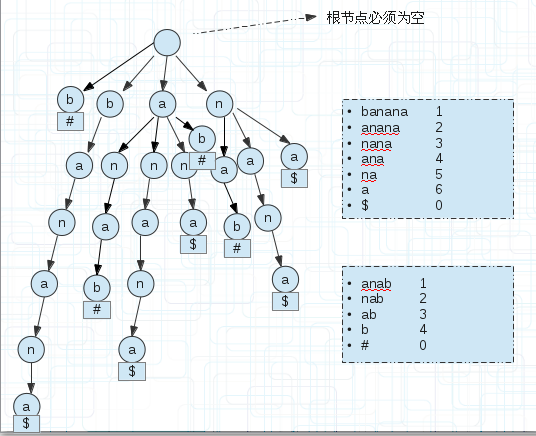
(5)
$和#是为了区分字符串的。
(上面的程序不能实现这个代码,因为isStr是bool型,若想实现,改成int型即可,第一个字符串标识为1,第二个字符串标识为2等)
我们为每个后缀串末尾单独添加一个空间存储区分字符串的符号。
那么怎么找s1和s2串最长的公共部分?
遍历每个后缀串,如果其引用计数为1则直接跳过,因为不可能有两个子串存放在这里,当引用计数>1时,往下遍历,直到分叉分别记录子串的符号,
如果不同,说明他们是不同字符串的,记录已经匹配的值即可,若相同继续下一次遍历。
上图的ana部分,到ana时,子串$结束,然后继续向下,子串anab以#结束,那么匹配了ana。
<4.最长回文串(广义后缀树)
把要求的最长回文串的字符串s1和它的反向(逆)字符串s2建立一棵广义后缀树。
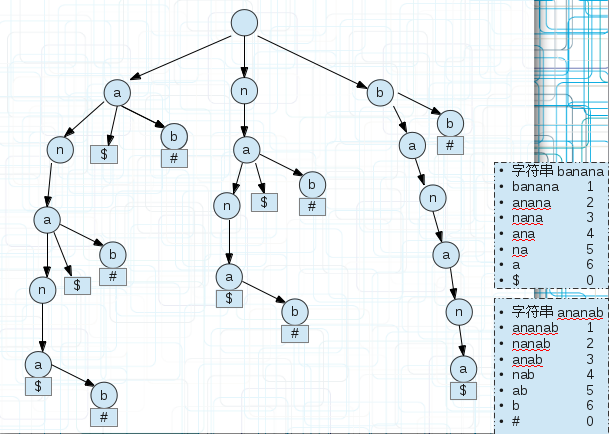
回文串有一个定义就是正反相同,也就是正着和反着可以重和在一起,那么我们直接看这棵广义后缀树的共同前缀即可,每个banana的子串和ananab的子串重合的部分
都是回文串,我们只需要找到最长的即可。比如上面的anana,从后面不同的标记可以看出两个字符串的某个后缀都有这个前缀,能完美重合到一起。即它是回文串。
记录Max,每次找到一个回文串比较即可。















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









