






Python机器学习中的实用小操作(一):数据清理篇
0. 背景
很多朋友评论希望我共享答案和文章中提到的操作代码,比如生成相关性图谱等。为了方便大家,开始介绍一些虽然简单但很有用的小操作,并提供代码块。这些简单的代码块可以被重复利用,在替换数据后就可以直接运行。当然,文章只能介绍一些比较基本的方法,任何一个方向展开都能写厚厚一本书,望大家理解:)
有鉴于篇幅原因,这篇文章会介绍:
- 如何快速得到数据的基本信息(均值、最大值、最小值等)
- 如何快速分析数据的缺失值(missing value)及替换缺失值
- 如何将描述变量(categorical variables)转化为数值型变量(numerical variables)
在下一篇文章中,我会在这篇文章的基础上介绍:
- 如何快速得到变量相关性矩阵
- 如何快速可视化得到相关性图谱
- 如何将高维数据在2维或者3维上可视化
这篇文章中的完整代码可以从这里下载:ruax6 - Ghostbin 或者 demo_zhihu.py
1. 系统要求
运行本文中的代码需要:
- Python 3.4以上。Python 2.7应该也可以,但我没有实际测试
- Python工具包:pandas, numpy, sklearn。
关于工具包更多的介绍看这里: 如何系统地学习Python 中 matplotlib, numpy, scipy, pandas? 不确定怎么安装的朋友可以看这里:Sklearn 安装 - Sklearn
如果通过Anaconda安装Python的朋友可以在Anaconda中查看安装包:
开始 - Anaconda Navigator - Environments - Root -> 查看已经安装的工具包
如果是直接安装Python的朋友可以用pip来安装:
pip install pandas numpy sklearn

推荐使用Spyder作为IDE来运行文章中的代码,jupyter notebook也是不错的选项。废话不多说,让我们进入今天的文章。
这篇文章中的完整代码可以从这里下载:ruax6 - Ghostbin 或者 demo_zhihu.py
2. 数据的基本信息
我们使用Github上的历史NBA的数据(fivethirtyeight/data)作为分析数据,原始数据包含了各个NBA球队的比赛情况,比如主场/客场,胜负情况等。考虑到效率原因,我们仅使用前100行做演示。首先导入数据:
# 导入必备的工具库
import pandas as pd
import numpy as np
# 从github上面导入数据文件的前100行
url = "https://raw.githubusercontent.com/fivethirtyeight/data/master/nba-elo/nbaallelo.csv"
df = pd.read_csv(url, nrows = 100, error_bad_lines=False)
# 替换数据源后可对你得数据进行分析
# 比如替换为你自己的 data.csv文件
# df = pd.read_csv("data.csv")
任务目标:一般的数据分析都需要先了解数据的基本信息,比如缺失值情况、数值的平均、标准差等。基本信息可以直观的告诉我数据中是否有明显的问题,使用pandas可以一步得到这个总结。
# 对数据进行基本的检查
# 得到数据的形状
n_df = df.shape[0]
print ("共有{row}行{col}列数据".format(
row=df.shape[0],
col=df.shape[1]))
# 得到数据的总结信息
summary_df = df.describe()
# 得到变量列表,得到格式为list
cols = df.columns.tolist()
输出的summary_df如下图所示。使用pandas的describe()后,我们可以很轻松的得到关于所有变量的基本信息:
<img src="https://pic4.zhimg.com/v2-27d67216b00721a309dc6b1c89c724e4_b.jpg" data-caption="" data-rawwidth="660" data-rawheight="423" class="origin_image zh-lightbox-thumb" width="660" data-original="https://pic4.zhimg.com/v2-27d67216b00721a309dc6b1c89c724e4_r.jpg">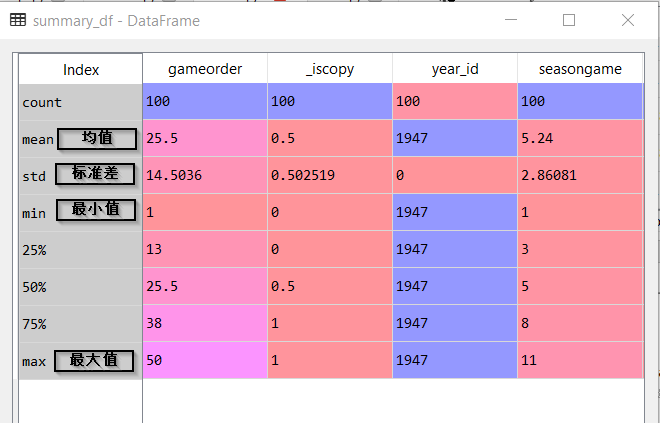
以上图为例,我们发现year_id这个变量的最大最小及均值都是1947,且标准差为0,这说明了这个变量完全没有任何变化,应该被删去。这就是通过直观的基本数据信息分析帮助我们进行数据准备。
3. 数据的缺失值检查(Missing Value Handling)
任务目标:很多真实数据中,因为各种各样的原因大量数据都缺失了。在进行任何严肃的数据分析前,我们一般都需要先检查数据缺失的情况。结合使用pandas和numpy工具包,我们可以很轻松的计算数据的缺失比例(一个变量中的缺失/总数):
# 1. 检查缺失值
# 计算每个变量的缺失值
for col in cols:
missing = n_df - np.count_nonzero(df[col].isnull().values)
mis_perc = 100 - float(missing) / n_df * 100
print ("{col}的缺失比例是{miss}%".format(col=col,miss=mis_perc))

通过上图我们发现notes这个变量的缺失比例是100%,按照道理应该被删掉。当然,pandas也可以用于简单处理缺失值,比如你想将整个数据中的缺失值用0来代替或者将某个变量中的缺失值用0替换:
# 将整个文件中的缺失值用0代替
df.fillna(value=0, inplace=True)
# 将note这个变量中的缺失值用0代替
df['notes'].fillna(value=0, inplace=True)
pandas还支持很多简单的缺失值填补,比如用均值或者最后一个有效的值替换缺失值,暂时不在此展开。
4. 将多个描述型变量一次性转为数值型
转化描述变量(convert categorical var to numeric)是机器学习重要的一步,使用pandas+sklearn我们可以自动将描述变量转化为数值变量。
任务目标:我们在不假设分类器的前提下,往往需要将描述变量转化为数字型变量,因为大部分算法无法直接处理描述变量。简单来说,大部分机器学习算法要求输入的数据必须是数字,不能是字符串啊。
首先我们需要找到那些描述型变量,可以检查是否变量的类型是"object":
# 2. 寻找描述变量
# 将描述变量储存到 cat_vars这个list中去
cat_vars = []
print ("\n描述变量有:")
for col in cols:
if df[col].dtype == "object":
print (col)
cat_vars.append(col)
运行以上代码我们会得到输出:
描述变量有:
game_id
lg_id
date_game
team_id
fran_id
opp_id
opp_fran
game_location
game_result
在找到描述型变量后,我们可以使用Sklearn的LabelEncoder工具进行批量转换。这个函数可以把描述特征快速转化为离散的数值变量,举个简单的例子:
# 使用LabelEncoder后将城市名转化为数字
北京 -> 0
上海 -> 1
上海 -> 1
天津 -> 3
北京 -> 0
当然,这个转换器在使用时有特定的限制,具体的说明下面给出。但一般情况下,用LabelEncoder进行类型转换问题不是很大。
print ("\n开始转换描述变量...")
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
# 将描述变量自动转化为 数值型变量
# 并将转化为的数据附加到原始数据上
for col in cat_vars:
tran = le.fit_transform(df[col].tolist())
tran_df = pd.DataFrame(tran, columns=['num_'+col])
print("{col}经过转化为{num_col}".format(col=col,num_col='num_'+col))
# print (le.classes_)
df = pd.concat([df, tran_df], axis=1)
以下图中的变量为例,我们查看df可以发现比赛结果(game_result)从 L(输)和W(赢)被转化为了 0和1。
<img src="https://pic2.zhimg.com/v2-a58b07acd603081f9b815be4ef0b69c9_b.jpg" data-caption="" data-rawwidth="723" data-rawheight="652" class="origin_image zh-lightbox-thumb" width="723" data-original="https://pic2.zhimg.com/v2-a58b07acd603081f9b815be4ef0b69c9_r.jpg">
使用这个转换方法有什么风险呢?主要问题在于描述变量是否有序(order):
- 有序变量(ordinal variables)。比如小学,初中,高中,大学。又比如非常满意,满意,不满意,极不满意。这类变量中的可取值之间都有一种顺序关系,因此不适合用独热编码(One-hot Encoding)来转化,因为在转化过程中会失去顺序信息。在这种情况下可以由
来转换, N代表该变量可取的值得总数。我们介绍的方法在理论上可以用于处理有序变量。
- 无序变量(non-ordinal/nominal variables)。比如一个公司有三个部门: 研发,测试,人事。在分类问题中我们可以使用独热编码进行转化。若在聚类问题中,我们一般希望度量其差异性,比较常见的是Value Difference Metrics (VDM)这一类。说白了就是直接看两个点的这个维度是否相同,若有N个无序变量,我们一般构建一个
的矩阵来描述差异度(Degree of Difference)。
然而,用我介绍的这个方法一次性转换所有的描述变量往往对性能不会有决定性的影响。当然,最准确的类型转换最好还是一个个的转、有针对的转。用我介绍的这个方法的好处:
- 批量解决所有描述型变量,省时省力
- 防止独热编码导致的维度上升和维度爆炸
- 事实上对后续模型的影响不是很大
5. 下期预告
作为这个系列第一篇文章,我们仅介绍了一些非常基本的数据清洗操作,下一节会介绍更多可视化相关的代码块。更详细的数据清洗可以参考:阿萨姆:如何有效处理特征范围差异大且类型不一的数据?
- 如何快速得到变量相关性矩阵
- 如何快速可视化得到相关性图谱
- 如何将高维数据在2维或者3维上可视化
敬请期待 ʕ•ᴥ•ʔ
* 完整代码下载:ruax6 - Ghostbin 或者 demo_zhihu.py
* 封面题图地址:Python Programming Training HRDF Courses in Malaysia















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









