






GFS的四个特点
首先,组件失效不再被认为是意外 ,而是被看做正常的现象。这个文件系统包括几百甚至几千台普通廉价部件构成的存储机器,又被相应数量的客户机访问。组件的数量和质量几乎保证,在任何给定时间,某些组件无法工作,而某些组件无法从他们的目前的失效状态恢复。我们发现过,应用程序bug造成的问题,操作系统bug造成的问题,人为原因造成的问题,甚至硬盘、内存、连接器、网络以及电源失效造成的问题。所以,常量监视器,错误侦测,容错以及自动恢复系统必须集成在系统中。
其次,按照传统的标准来看,我们的文件非常巨大 。数G的文件非常寻常。每个文件通常包含许多应用程序对象,比如web文档。传统情况下快速增长的数据集在容量达到数T,对象数达到数亿的时候,即使文件系统支持,处理数据集的方式也就是笨拙地管理数亿KB尺寸的小文件。所以,设计预期和参数,例如I/O操作和块尺寸都要重新考虑。
第三,在Google大部分文件的修改,不是覆盖原有数据,而是在文件尾追加新数据 。对文件的随机写是几乎不存在的。一般写入后,文件就只会被读,而且通常是按顺序读。很多种数据都有这些特性。有些数据构成数据仓库供数据分析程序扫描。有些数据是运行的程序连续生成的数据流。有些是存档的数据。有些数据是在一台机器生成,在另外一台机器处理的中间数据。对于这类巨大文件的访问模式,客户端对数据块缓存失去了意义,追加操作成为性能优化和原子性保证的焦点。
第四,应用程序和文件系统API的协同设计提高了整个系统的灵活性 。例如,我们放松了对GFS一致性模型的要求,这样不用加重应用程序的负担,就大大的简化了文件系统的设计。我们还引入了原子性的追加操作,这样多个客户端同时进行追加的时候,就不需要额外的同步操作了。论文后面还会对这些问题的细节进行讨论。
GFS的架构
一个GFS集群包含一个主服务器和多个块服务器,被多个客户端访问,如图1。这些机器通常都是普通的Linux机器,运行着一个基于用户层的服务进程。如果机器的资源允许,而且运行多个程序带来的低稳定性是可以接受的话,我们可以很简单的把块服务器和客户端运行在同一台机器。
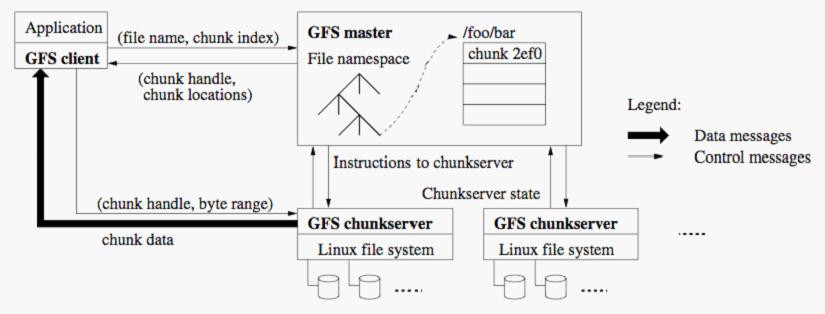
文件被分割成固定尺寸的块。在每个块创建的时候,服务器分配给它一个不变的、全球唯一的64位的块句柄对它进行标识。块服务器把块作为linux文件保存在本地硬盘上,并根据指定的块句柄和字节范围来读写块数据。为了保证可靠性,每个块都会复制到多个块服务器上。缺省情况下,我们保存三个备份,不过用户可以为不同的文件命名空间设定不同的复制级别。
主服务器管理文件系统所有的元数据。这包括名称空间,访问控制信息,文件到块的映射信息,以及块当前所在的位置。它还管理系统范围的活动,例如块租用管理,孤儿块的垃圾回收,以及块在块服务器间的移动。主服务器用心跳信息周期地跟每个块服务器通讯,给他们以指示并收集他们的状态。
GFS客户端代码被嵌入到每个程序里,它实现了Google文件系统API,帮助应用程序与主服务器和块服务器通讯,对数据进行读写。客户端跟主服务器交互进行元数据操作,但是所有的数据操作的通讯都是直接和块服务器进行的。
让我们解释下 一次简单读取的流程。首先,利用固定的块尺寸,客户端把文件名和程序指定的字节偏移转换成文件的块索引。然后,它把文件名和块索引发送给主服务器。主服务器回答相应的块句柄和副本们的位置。客户端用文件名和块索引作为键值缓存这些信息。
然后客户端发送请求到其中的有一个副本处,一般会选择最近的。这个请求指定了块的块句柄和字节范围。对同一块的更多读取不需要客户端和主服务器通讯,除非缓存的信息过期或者文件被重新打开。实际上,客户端通常在一次请求中查询多个块,而主服务器的回应也可以包含紧跟着这些请求块后面的块的信息。
主服务器保存三种主要类型的元数据:文件和块的命名空间,文件到块的映射,以及每个块副本的位置。所有的元数据都保存在主服务器的内存里。除此之外,前两种类型(命名空间和文件块映射)的元数据,还会用日志的方式保存在主服务器的硬盘上的操作日志内,并在远程的机器内复制一个副本。
GFS交互设计
1. 同步变更:在GFS中,所有的变更需要应用在所有的副本上以保证数据的一致性。我们使用租约来保持多个副本间变更顺序的一致性。主服务器为其中一个副本签署一个块租约,我们把这个副本叫做主块。主块选择对块所有操作的一系列顺序。进行操作的时候所有的副本遵从这个顺序。这样全局的操作顺序首先由主服务器选择的租约生成顺序决定,然后由租约中主块分配的序列号决定。
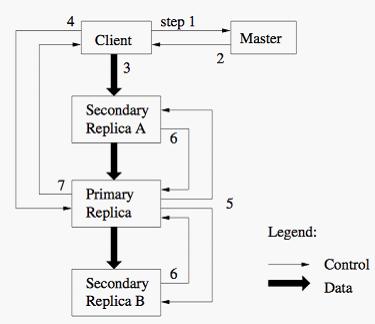
客户机向主服务器询问哪一个块服务器保存了当前的租约,以及其他副本的位置。如果没有一个块服务器有租约,主服务器就选择一个副本给它一个租约(没有被显示出来)。
主服务器回复主块的标识符以及其他副本的位置。客户机为了后续的操作缓存这个数据。只有主块不可用,或者主块回复说它已经不在拥有租约的时候,客户机才需要重新跟主服务器联络。
客户机把数据推送到所有的副本上。客户机可以用任意的顺序推送。每个块服务器会把这些数据保存在它的内部LRU缓冲内,直到数据被使用或者过期。通过把数据流和控制流分离,我们可以基于网络负载状况对昂贵的数据流进行规划,以提高性能,而不用去管哪个块服务器是主块。3.2章节会更详细地讨论这点。
所有的副本都被确认已经得到数据后,客户机发送写请求到主块。这个请求标识了早前推送到所有副本的数据。主块为收到的所有操作分配连续的序列号,这些可能来自不同的客户机。它依照序列号的顺序把这些操作应用到它自己的本地状态中。
主块把写请求传递到所有的二级副本。每个二级副本依照主块分配的序列号的顺序应用这些操作。
所有二级副本回复主块说明他们已经完成操作。
这里有一个优化的特点就是将数据流和控制流分离,控制流从客户机到主块然后再到所有二级副本的同时,数据顺序推送到一个精心选择的管道形式的块服务器链。我们的目标是完全利用每个机器的带宽,避免网络瓶颈和延迟过长的连接,最小化推送所有数据的耗时。
为了完全利用每个机器的带宽,数据顺序推送到一个块服务器链,而不是分布在其他的拓扑下(例如,树)。这样,每个机器的带宽就会完全用于尽快的传输数据,而不是分散在多个副本间。
GFS在其他方面还有很多的优化,以后有时间在一点一点总结














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









