







渲染引擎的第一步是使用网络栈来下载和网页中资源,该过程比较耗时
资源
网页本身是一种资源,其依赖很多其他类型的资源,包括图片和视频等,因此网络和资源加载是网页加载和渲染的第一步。
HTML支持的资源主要包括以下类型:
- HTML: HTML页面,包括各种HTML元素;
- JavaScript: js代码,可以内嵌在html文件中,也可以以单独的文件存在;
- CSS样式表:CSS样式资源,与JavaScript类似,除了可以内嵌在HTML之外还可以以单独的文件存在;
- 图片: 各种类型的图片,包括png、jpeg等,也包含一些特殊的图片资源,如SVG中所需的图片资源;
- SVG: 用于绘制SVG的2D矢量图形表示;
- CSS Shader: 支持CSS Shader文件,目前webkit支持该功能;
- 视频,音频和字幕: 多媒体资源及支持音视频的字幕文件(TextTrack);
- 字体文件: CSS支持自定义字体,CSS3引入了自定义字体文件;
- XSL样式表:使用XSLT语言编写的XSLT代码文件;
上述的资源在webkit中均有不同的类来表示,它们公共的基类为CachedResource,HTML文本对应的类型为MainResource类,对应的资源类型为CachedRawResource类,之所以各资源类的前面有Cached字样,是由于引入的缓存机制,在对资源请求之前会先获取缓存中的信息,以决定是否向服务器提出资源请求,对应的类图如下:
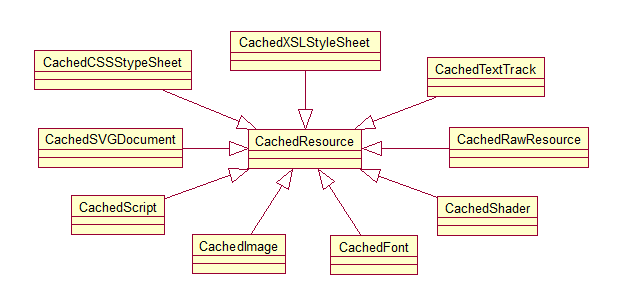
资源缓存
资源缓存的目的是为了提高资源使用的效率,其基本思想是建立一个资源的缓存池,当需要请求资源的时候先去资源池查找是否有相应的资源,如果没有则向服务器发送请求,webkit收到资源后将其设置到该资源类的对象中去,以便于缓存后下次使用,webkit从资源池中查找资源的关键字是URL,URL标记了资源的唯一性。
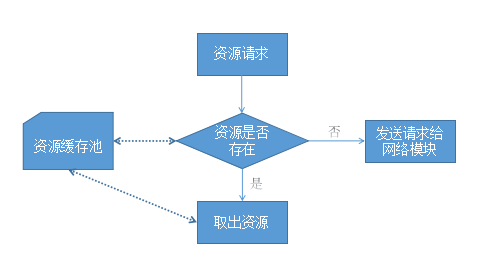
资源加载器
Webkit中加载器总共分为三种。
- 针对每种资源类型的特定加载器,其特点是仅加载某一种资源,如image元素需要加载图片资源时其特定的资源加载器为ImageLoader类,这些资源加载器没有公共基类,其作用是当需要请求资源时有资源加载器负责加载并隐藏背后复杂的逻辑,加载器属于它的调用者;
- 资源缓存机制的资源加载器,其特点是所有特定加载器都共享它来查找并插入缓存资源(CachedResourceLoader类),特定加载器先通过缓存机制的资源加载器查找资源是否存在,它属于HTML的文档对象;
- 通用资源加载器(ResourceLoader类),当webkit需要从网络或者文件系统获取资源的时候使用该类来获取资源数据,其被所有特定资源加载器共享,它属于CachedResource类,但同CachedResourceLoader类没有继承关系;
过程
以img元素为例,其属性src是一个有效的URL地址,当HTML解析器解析到该元素时webkit会创建一个ImageLoader对象来加载该资源,其过程如下所示:
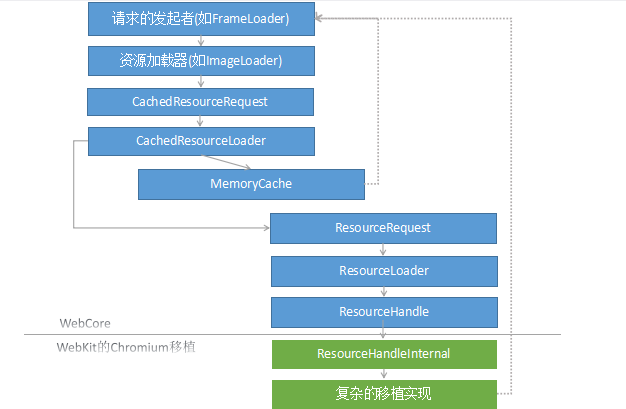
从网络获取资源是一个相对耗时的过程,通常一些资源的加载是异步的,因此资源的加载和获取不会阻塞当前webkit的渲染过程,例如图片和CSS等,但有些场景下某些资源的加载会阻塞主线程的渲染过程,如JavaScript代码文件,因为其后面可能还有许多需要下载的资源,对于这种因主线程被阻塞导致后面解析工作没法继续往下执行的情况,并且对于HTML网页中后面使用的资源也没法知道并下载的情况,webkit会启动一个线程去遍历后面的HTML网页,收集需要的资源URL,然后发送请求,与此同时,webkit能够并发下载这些资源,甚至并发下载JavaScript代码资源,这对网页的加载提速效果明显。
资源的生命周期
同CachedResourceLoader对象一样,资源池也属于HTML文档对象,由于资源池不能无限大,因此要用相应的机制来替换其中的资源,从而加入新的资源,这种机制采用的算法为LRU(最近最少使用)算法。对于打开网页刷新当前页面的场景,对于某些资源,webkit需要直接重新发送请求,要求服务器端将内容重新发送过来,但对于大多数资源,Webkit则可以利用HTTP协议减少网络负载,在HTTP协议中对此有规定,游览器可以发送消息确认是否需要更新,如果有则游览器重新获取该资源,否则就需要利用该资源。
webkit的做法如下,首先判断资源是否在资源池中,如果在则发送一个HTTP请求给服务器,说明该资源在本地的一些信息,例如修改时间等,服务器根据该信息进行判断,如果没有更新则返回状态码304表示不需要更新,直接利用资源池中的资源,否则webkit申请下载最新的资源内容。
chromium多进程资源加载
多进程
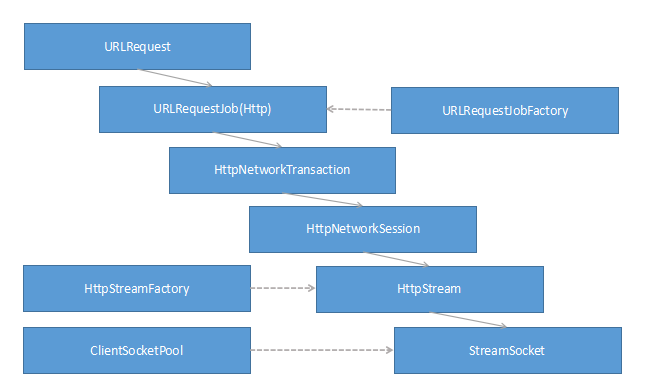
资源的实际加载在各个Webkit移植中有不同的实现,chromium采用的是多进程的资源加载机制,下图描述与chromium如何利用多进程架构来完成资源的加载,主要是多个Render进程和Browser进程之间的调用栈涉及的主要类:
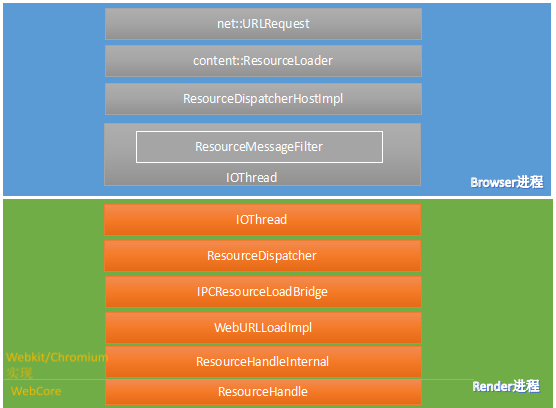
Render进程在网页加载过程中需要获取资源,由于安全性和效率上的因素,Render进程的资源获取是通过进程间通信将任务交给Browser进程来完成,Browser进程有权限从网络或本地获取资源。
在chromium架构的Render进程中,ResourceHandleInternal通过IPCResourceLoaderBridge类同Browser进程通信,IPCResourceLoaderBridge类继承自ResourceLoaderBridge类,其作用是负责发起请求的对象和回复结果的解释工作,实际消息的接收和派发交给ResourceDispatcher类来处理。在Browser进程中,首先有ResourceMessageFilter类来过滤Render进程的消息,如果与资源请求有关则该过滤类转发请求给ResourceDispatcherHostImpl类,随即ResourceDispatcherHostImpl类创建Browser进程中的ResourceLoader对象来处理,ResourceLoader类是Chromium游览器实际的资源加载类,其负责管理向网络发起请求、从网络接收过来的认证请求、请求的回复管理等工作,因为这其中每项都有专门的类来处理,但都是由ResourceLoader类统一管理,从网络或者本地文件读取信息的是URLRequest类,实际上他承担了建立网络连接、发送请求数据和接收回复数据的任务。
工作方式和资源共享
资源请求有同步和异步两种方式,ResourceLoader类承担Browser进程中有关资源的管理任务,对于同步和异步两种资源请求方式,ResourceLoader类使用SyncResourceHandle类和AsyncResourceHandle类来向Render进程发送状态消息,并接收Render进程对这些消息的反馈。
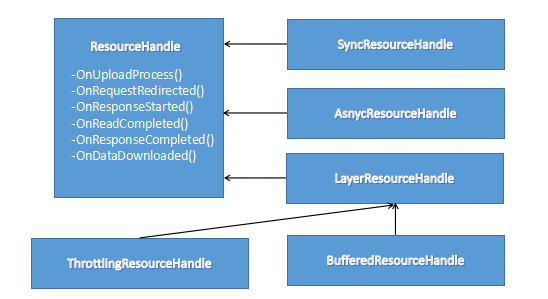
图中,ResourceHandle还有两个子类,第一个是LayerResourceHandle类,它自己不直接参与资源的处理,而是将处理转给另一个ResourceHandle对象,LayerResourceHandle没有实际意义,仅是BufferedResourceHandle的父类,该缓冲类用来缓冲网络或者文件传过来的数据,直到数据足够满足需求然后转给另一个ResourceHandle对象,ThrottlingResourceHandle类是在面对很多个资源请求时仅使用一个URLRequest对象来获取资源,这可以有效减少网络的开销,因为不需要重新建立多个网络连接。此外,在chromium中还有很多ResouceHandle的子类,它们的作用各异。
- RedirectToFileResourceHandler:继承自LayerResourceHandle类,在接收到的数据转给另一个ResourceHandle类的同时,转存到文件
- StreamResourceHandle:继承自LayerResourceHandle类,在接收到的数据转给另一个ResourceHandle的同时,转存到数据流
- CertificateResourceHandle:主要处理证书类的资源请求
资源统一交给Browser进程来处理,这带来的好处是使得资源在不同网页间的共享变得很容易,但因此也带来一个问题,每个Render进程某段时间内可能有多个请求,同时还有多个Render进程,Browser进程需要处理大量的资源请求,这需要一个处理这些请求的调度器,chromium中为ResourceScheduler。ResourceScheduler类管理的对象是最顶层的net::URLRequest对象,ResourceScheduler类根据URLRequest的标记和优先级来调度URLRequest对象,每个URLRequest对象都有一个ChildID和RouteID来标记属于哪个Render进程,ResourceScheduler类中有一个哈希表,该表按照进程来组织URLRequest对象,对于一下类型的网络请求,立即被Chromium发出:① 高优先级的请求 ② 同步请求 ③ 具有SPDY能力的服务器。
网络栈
WebKit的网络设施
WebKit的资源加载由各个移植来实现,因此WebCore并没有什么特别的基础设施,每个移植的网络实现是不一样的,Webkit中网络部分的代码在WebKit/Source/WebCore/platform/network中,主要是一些HTTP消息头,MIME消息、状态码等信息的描述和处理,没有实质的网络连接和各种针对网络的优化。
chromium的网络栈
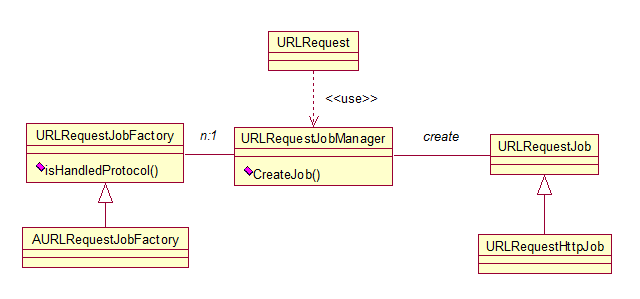
URLRequest类被上层调用并启动的时候会根据URL的”scheme”来决定需要创建什么类型的请求,”scheme”是URL的协议类型,如”http://”、”file://”,也可以是自定义的scheme,例如Android系统的”file://android_assert”。URLRequest对象创建的是一个URLRequestJob子类的一个对象,如图中的URLRequestHttpJob类,为了支持自定义的scheme处理方式,chromium使用工厂模式,URLRequestJob类和它的工厂类URLRequestJobFactory的管理工作都由URLRequestJobManager类负责,基本的思路是,用户可以在该类中注册多个工厂,当有URLRequest请求时,先由工厂检查是否需要处理该“scheme”,如果没有,工厂管理类继续交给下一个工厂类来处理,最后,如果没有工程能够处理,chromium交给内置的工厂来检查和处理是否为“http://“、“ftp://”或者“file://”等,下图描述了相互间的关系。
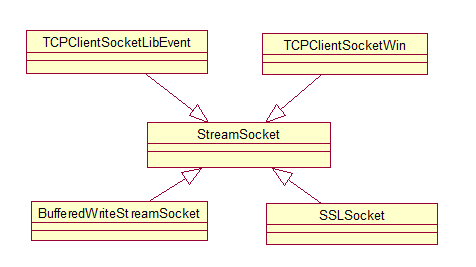
当URLRequestHttpJob被创建后,该对象首先从Cookie管理器中获取与该URL相关联的信息,之后借助于HttpTransactionFactory对象创建一个HttpTransaction对象来表示开启一个HTTP连接的事务,通常情况下,HttpTransactionFactory对象对应的是一个他的子类HttpCache对象,HttpCache类使用本地磁盘缓存机制,如果该请求对应的回复已经在磁盘缓存中,那么chromium无需再建立HttpTransaction来发起连接,而是直接从磁盘中获取即可,如果磁盘中没有该URL的缓存,同时如果目前该URL请求对应的HttpTransaction已经建立,那么只要等待它的回复即可,当这些条件都不满足的时候,chromium才会真正创建HttpTransaction对象,再次,HttpNetworkTransaction类使用HttpNetworkSession类来管理连接会话,HttpNetworkSession类通过它的成员HttpStreamFactory对象来建立TCPSocket连接,之后chromium创建HttpStream对象,HttpStreamFactory对象将和网络之间的数据读写交给自己新创建的一个HttpStream子类的对象来处理。最后是套接字的建立,chromium中与服务器建立连接的套接字是StreamSocket类,它是一个抽象类,在POSIX和Windows上有不同的实现,同时,为了支持SSL机制,StreamSocket类还有一个子类SSLSocket,关系如下。
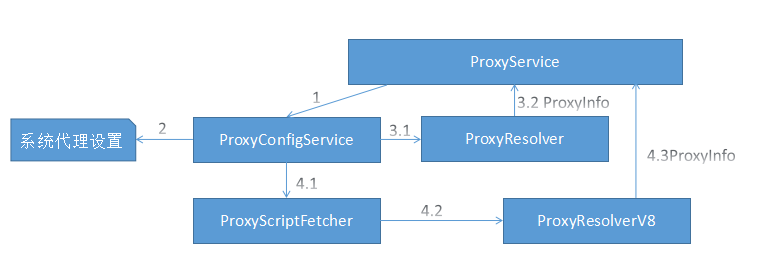
代理
- ProxyService: 对于一个URL,HttpStreamFactory类使用ProxyService类获取代理的信息,ProxyService类首先会检查当前的设置是不是最新的,如果不是则会依赖ProxyConfigService来重新获取代理信息,该类不处理实际任务,而是使用ProxyResolver类做实际的代理工作
- ProxyConfigService: 获取代理信息的类,可获取平台上的代理设置,不同平台上有不同的实现
- ProxyScriptFetcher:CHromium支持代理的JavaScript脚本,该类负责从代理的URL中获取脚本
- ProxyResolver:实际负责代理的解释和执行,通常启用新的线程来处理,因为当前可能会被域名的解析所阻碍
- ProxyResolverV8:ProxyResolver的子类,使用V8引擎来解释和执行脚本
下图描述了上面这些类,同时也描述了Chromium中获取网络代理的过程,数字表示网络代理的次序,分支3.1、4.1分别表示简单的代理设置和代理脚本设置的处理过程。
磁盘缓存
特性
- 需要缓存的资源可能很多,但磁盘空间不是无限大的,因此需要有相应的机制来移除合适的缓存资源
- 能够确保在游览器奔溃时不破坏磁盘文件,至少能保护原先在磁盘中的数据
- 能够高效和快速的访问磁盘中现有的数据结构,支持同步和异步两种访问方式
- 能够避免同时存储两个相同的数据
- 能够很方便地从磁盘中删除一个项,同时可以在操作一个项的时候不受其他请求的影响
- 磁盘不支持多线程访问,因此需要把所有磁盘缓存的操作放入单独的一个线程中
- 升级版本时,如果磁盘缓存的内部存储结构发生改变,chromium仍然能够支持老版本的结构
结构
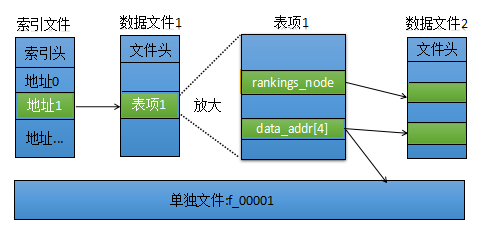
主要有两大类:Backend和Entry,Backend类表示整个磁盘的缓存,是所有针对磁盘缓存操作的主入口,表示的是一个缓存表,Entry类指的是表中的表项,缓存通常是一个表,对于整个表的操作作用在Backend类上,包括创建一个个的表项,每个项有关键字来唯一确定,这个关键字是资源的URL,对项内的操作,包括读写等都是由Entry类来处理。在磁盘上,chromium至少需要一个索引文件和四个数据文件,索引文件用来检索存放在数据文件中的众多索引项,用来存放索引表项,数据文件又称块文件,里面包含很多特定大小的块,用于快速检索,这些数据块的内容是表项,包括HTTP文件头,请求数据和资源数据等,数据文件名如“data_1”,“data_2”等。当资源文件大小超过一定值的时候,chromium会建立单独的文件来保存它们,而不是将它们放入上面的4个数据文件中,这些单独存储的文件中并没有元数据信息,只是资源文件内容,文件名如“f_xxxxx”,其中xxxxx是5个数字或者ABCDEF(十六进制),用于表示编号。索引文件包括一个索引的头部和索引地址表,头部用来表示该索引文件的信息,例如索引文件版本号,索引项数量,文件大小等信息,而索引地址表就是保存各个表项对应的索引地址,该索引文件直接将文件映射到内存地址,这样可以快速的找到表项的索引地址。表项的结构分为两部分,第一部分标记自己,包括各种元数据信息和自身的内容,通常它是较少变动的,在chromium中用disk_cache::EntryStore类表示;另一部分经常发生变动,在chromium中用disk_cache::RankingsNode类表示,它的大小固定,主要为表项的回收算法服务,里面保存了回收算法所需要的信息,大体结构如下:
安全机制
DNS预取和TCP预连接
DNS预取是指利用现有的DNS机制,提前解析网页中可能的网络连接,具体的讲是指用户正在游览当前页面的时候,chromium提前提取网页中的超链接,将域名抽取出来,利用比较少的CPU和网络带宽来解析这些域名或者IP地址,当用户单机这些链接的时候可以节省不少的时间,特别是在域名解析比较慢的时候,效果特别明显。DNS预取技术直接利用系统的域名解析机制,因此不会阻碍当前网络栈的工作,此外针对多个域采取并行处理的方式,每个域名的解析必须由新开启的一个线程处理,结束后此线程退出。
HTTP管线化
HTTP管线化是一项同时将多个HTTP请求一次性提交给服务器的技术,因此无需等待服务器的回复,因为它可能将多个HTTP请求填充在一个TCP数据包内,HTTP管线化需要在网络上传输较少的TCP数据包,因此较少了网络负载,请求结果的管线化是的HTML网页加载时间动态提升,特别是在有高延迟的连接环境下。管线化机制需要通过永久连接完成,并且只有GET和HEAD等请求可以进行管线化,使用场景上有较大限制。
SPDY
SPDY是一种新的会话层协议,由于网络协议是一种栈式结构,它被定义在HTTP协议和TCP协议之间,SPDY协议的核心思想是多路复用,仅使用一个连接来传输一个网页中的众多资源,其本质并没有改变HTTP协议,只是将HTTP协议头通过SPDY来封装和传输,数据传输方式也没有变化,使用TCP/IP协议,因此SPDY协议相对比较容易部署,服务器只要插入SPDY协议的解释层,从SPDY的消息头中获取各个资源的HTTP头即可,其次SPDY必须建立在SSL层之上,只是一个比较大的限制,因为有很多网站不支持HTTPS,SPDY的工作方式有以下四个特征:
- 利用一个TCP连接来传输无线个数的资源请求的读写数据流,提高了TCP连接的利用率,减少了TCP连接的维护成本
- 根据资源请求的优先级和特性,SPDY可以调整这些资源请求的优先级
- 只对这些请求使用压缩技术,可大大减少需要传送的字节数
- 当用户需要游览某个页面,支持SPDY协议的服务器在发送网页内容时,可以尝试发送一些信息给游览器,告诉后面可能需要哪些资源,游览器可以提前知道并决定是否需要下载,更极端的是服务器可以主动发送资源,引入SPDY协议后,chromium的网络栈如下所示:
-
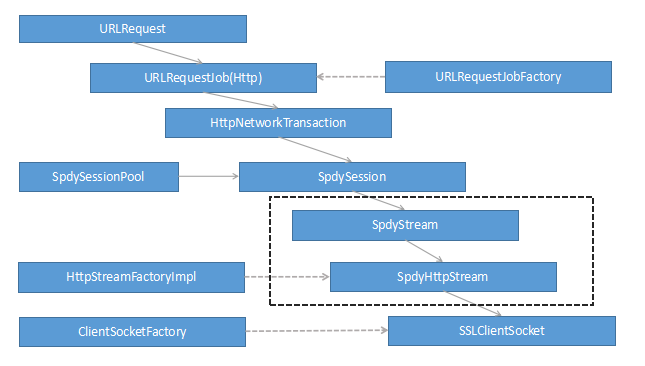
与之前的网络栈存在以下三点的不同
- 虚线框表示可能有多个SpdyStream和SpdyHttpStream对象,也就是多个流使用一个SpdySession会话,同时使用一个socket连接,对多个Stream对象的管理、删除、创建、数量限制等都是由SpdySession来处理
- 对于之前的一些类,Spdy有专门的实现,因为需要支持新协议的关系
- SpdyHttpStream类继承自之前的HTTPStream类,所充当的角色相同—就是一个HTTPStream类,但是SpdyHttpStream类会对应一个SpdyStream并将Spdy协议部分等实际工作交给SpdyStream类来做














 1887
1887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









