





本文主要对JasonEvans于2006年提出的jemalloc内存分配器的翻译,原paper所在网站:
http://people.freebsd.org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf
本人在个人的github项目rpc-pratical中也有实现jemalloc内存分配器,用于为bytebuffer的内存分配提供支持,欢迎您提出建议:
https://github.com/stillingpb/rpc-pratical
A Scalable Concurrent malloc(3) Implementation for FreeBSD
JasonEvans jasone@FreeBSD.org
April16, 2006
摘要
FreeBSD项目从第五版开始就一直尝试提供对多处理器计算机系统的支持。在取得足够的进展之后,C库中原有的malloc(3)已经逐渐成为了多线程应用的潜在瓶颈。结合目前的发展情况,在本文中我提出了一种新的内存分配器,可为应用提供可扩展的并发内存分配。基准测试表明,随着处理器数量的增加,分配器为多线程应用提供的内存分配也能够很好的进行扩展。同时对于单线程应用,该分配器和之前的分配器拥有相当的性能。
引言
FreeBSD之前的malloc(3)采用了Kamp(1998)提出的phkmalloc,该分配器在长期以来的公开比较中(Fengand Berger, 2005; Berger et al.,2000; Bohra and Gabber, 2001),被认为其稳定性和性能都是最好的分配器之一。然而phkmalloc出现在多处理器系统少有的年代,对多线程支持并不好。FreeBSD项目一直致力于为SMP系统提供可扩展的性能,目前已取得很多有效的进展,而malloc(3)也越发成为了一些多线程应用的扩展瓶颈。本文提出了一种新的malloc(3)实现,在此非正式的称为jemalloc。
从表面上看内存分配和释放是一个简单问题,仅仅需要少量信息用于记录正在使用的内存和空闲的内存。然而数十年的研究,以及大量的分配器实现都没能创造出一款卓越的分配器。现实中对分配器进行测量的最佳方法都很简单,主要都是通过对性能指标的统计分析来进行测量。在十几年前Wilson等人(1995)对当时的分配器发展状况进行过非常精彩的概述。在当时面向多处理器还不是一个重要问题,但这篇概述对分配器在现代化场景中所面临的问题进行了深入总结。下文会简要提及影响jemalloc的几个典型问题,但不准备对在具体实现分配器时才会遇到的问题进行讨论。
对分配器的性能测量,主要是通过对应用的执行时间、内存平均使用量、或者内存峰值使用量等指标结合起来进行测量。而采取与应用隔离,并单独测量分配器代码耗时的方式,测量结果将不够充分。内存布局往往会对应用的后期运行速度产生较大影响,因为内存布局会影响到CPU缓存、主存、虚拟内存分页的效果。另外,现在大家都普遍认为合成跟踪并不能充分测量出分配策略对内存碎片的影响(Wilson et al., 1995)。测量分配器性能唯一的准确方式,就是通过测量真实应用的执行时间和内存使用情况。这为分配器之间的性能比较构成了挑战。考虑到某个分配器可能对某种特定的分配模式表现糟糕,但如果没有任何一个基准测试应用显示出存在这种特定的分配模式,那么这个分配器在基准测试中可能表现得就很好,尽管该分配器仍存在一些不适合的应用场景。这让在测试时采用更广泛的不同类型应用变得更加重要。同时这也促使了在设计分配器时,需要尽量减少较差分配模式的数量和程度。
内存碎片可以分为内部碎片和外部碎片。其中内部碎片指的是一块分配出来的内存,其首部空间或尾部空间无法被利用的部分。而外部碎片是指一块受虚拟内存系统管理,但无法被应用直接使用的空间。根据应用行为的不同,这两种碎片会明显影响到应用的性能特征。理想情况下这两种碎片都应该尽可能少,但实际上分配器不得不权衡这两种不同类型碎片出现的多少。
在过去十年里,内存变得越来越便宜,且容量越来越大,phkmalloc因此采用特殊的优化方式来最小化内存页工作集的大小,所以jemalloc需要更加注意缓存局部性,并进一步注意CPU高速缓存行的工作集。尽管分页机制可能会明显导致性能退化(jemalloc不关注这个问题),但更常见的问题是CPU从内存中获取数据和CPU本身的性能相比存在巨大的延迟。
如果一个应用的工作集并不适合缓存,那么一个使用更少内存的分配器并不一定有更好的缓存局部性,只有工作集尽可能多的被装载到内存才会提高其性能。在较短时间内被分配出来的多个对象,它们往往会被一起使用,所以如果分配器可以实现对象的连续分配,将可以很好的提高工作集的局部性。实际中,往往内存的使用情况是等价于缓存局部性的;所以jemalloc首先会尝试最小化内存使用率,并且只有在不违背这个条件的前提下,才会尝试进行连续分配。
现代多处理系统在每个缓存行上都保存了一份内存视图。如果有两个线程正运行在独立的处理器之上,并且都在操作相同缓存行上的不同对象,那么这两个处理器必须仲裁属于自己的缓存行(图1)。这种高速缓存行的假共享会导致严重的性能下降。解决这个问题的一种思路是填充对齐分配,但这种方式会直接违背尽可能紧密分配对象这一目标;同时也会导致严重的内部碎片。而jemalloc使用多个负责分配的arena来减轻这个问题,同时为了避免在核心性能代码处出现缓存行假共享,jemalloc将填充对齐分配方式交由给应用开发人员来决定是否使用,或者当一个线程在某个arena上分配对象时,其它线程禁止在这个arena上同时进行分配。
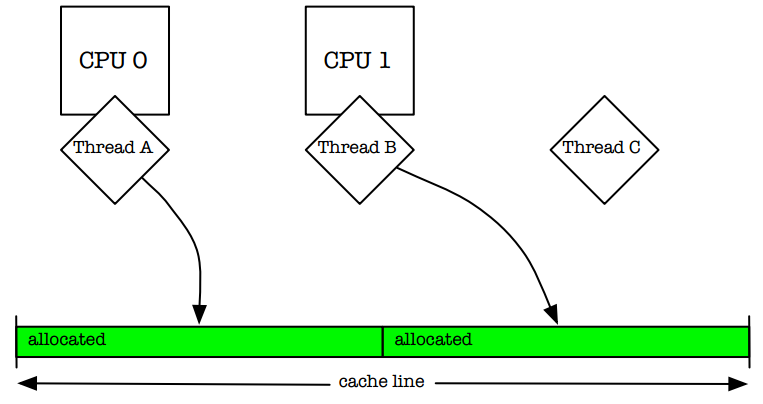
图1:两个独立线程在同一个缓存行上的不同位置进行物理内存分配(缓存假共享)。如果两个线程并发修改各自的分配,那么处理器之间必然会为缓存行的所有权发生竞争。
这一分配的主要目标是减少多线程应用程序在多处理器系统上运行的锁竞争。Larson和Krishnan(1998)在展示和测试相关策略方面做出了杰出工作。他们尝试在自己的分配器中细化锁粒度,这样与其使用一把单独的分配锁,每个空闲列表都有自己的锁。尽管这最小化了锁竞争,但也只起了一部分作用,并没能完全避免锁竞争。他们定义了“cachesloshing”——在操作分配器的数据结构期间所发生的在多个处理器之间的缓存数据快速移动。在他们的解决方案中使用了多个arena来进行分配,并采用线程标识符哈希的方式来为线程安排arena(图2)。这种方式工作得非常好,并后续被其他人所借鉴(Berger et al., 2000; Bonwick and Adams,2001)。jemalloc使用了多个arena,但使用了比哈希更稳定的方式来为线程分配arena。
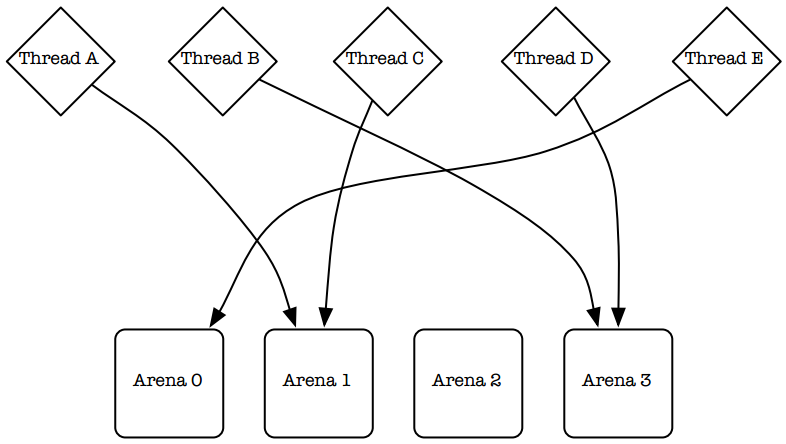
图2:Larson和Krishnan (1998)采用线程标识符哈希的方式来为线程永久分配arena。这是一种伪随机过程,无法保证所有的arena被平均使用。
下文将会主要描述jemalloc的关键算法和数据结构,并采用基准测试方式测量了性能,以及在多处理器系统中jemalloc对多线程应用的可扩展性,同时测量了在单线程应用中的性能和内存使用情况,并讨论了内存碎片的测量方法。
算法和数据结构
FreeBSD支持通过/etc/malloc.conf符号链接,MALLOCOPTIONS环境变量,_malloc_options全局变量来运行时配置分配器。这提供了一种低开销、非侵入式的配置机制,这对调试和性能调整都很适用。jemalloc采用了phkmalloc支持的各种调试选项机制,同时暴露了各种性能相关的参数。
每个应用在运行时都被配置了固定数量的arena。默认情况下arena的数量取决于处理器的数量:
单处理器:使用一个arena进行分配。在这里使用多个arena是没有意义的,因为只有当线程在分配过程中被其它线程抢占才会造成分配竞争。
多处理器:使用处理器数量的四倍多的arena。通过为多个线程分配一组arena,这样单个arena被并发使用的可能性就会降低。
当线程第一次分配或释放内存时,该线程会被分配一个arena。与其采用线程标识符哈希的方式,jemalloc采用循环方式来为线程分配arena,这样就可以保证每个arena被分配给了大致相同数量的线程。使用线程标识符进行可靠的伪随机哈希分配(实际应用中,线程标识符是指针)是相当困难的,这也是最终促使采用循环分配这种方式的原因。尽管还会存在多个线程同时竞争某个arena,但平均来看,已经不存在比循环分配方式更好的初始化分配方式了。动态再平衡可能会降低竞争,但必要的信息记录会带来很大的开销,并且几乎不能保证这样的动态管理会带来足够的好处。
线程本地存储(TLS)对有效实现循环方式分配arena很重要,因为为每个线程分配的arena都需要存储起来。在Non-PIC代码、不支持TLS的架构等情况中,分配器需要使用线程标识符哈希的方式。由pthreads库提供的线程特定数据(TSD)机制可以有效替代TLS,除了用FreeBSD的pthreads去分配内部内存这种情况除外,因为在这种情况下当TSD被分配器使用会导致无限递归。
通过sbrk(2)和mmap(2)从内核分配的所有内存都被分成了多个”chunk”尺寸来进行管理,这样每个chunk的基地址总是chunk尺寸的整数倍(图3)。在一次分配时,这些对齐的chunk只需要常量时间的计算就可以被找到。一组chunk通常会被一个特定的arena管理,对这些对应关系的观察是分配器进行正确分配的关键。默认情况下chunk的尺寸大小是2MB。
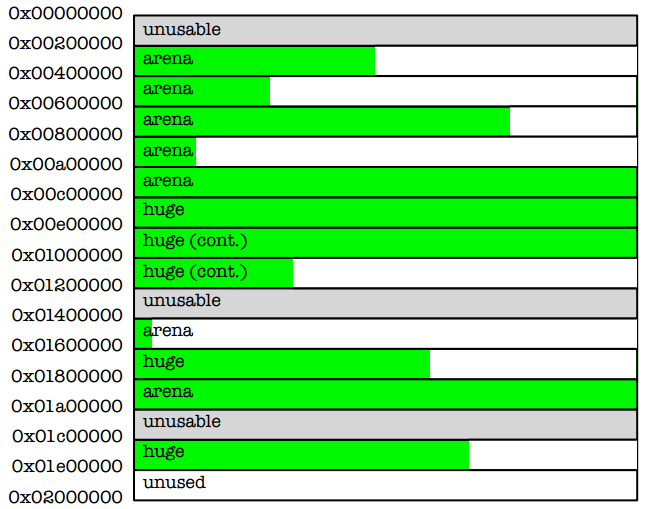
图3:chunk的尺寸大小总是相同,起始于chunk对齐的地址。Arena会将chunk切分来满足一次较小的内存分配,而一次huge的内存分配会直接由一个或多个连续的chunk提供。
按分配的尺寸大小主要分为三类:small,large,和huge。所有尺寸的分配请求都会被向上取整为最接近的分类。huge的分配大于chunk尺寸的一半,并直接由专门的chunk提供支持。huge分配的元数据存储在唯一的一棵红黑树中。由于绝大多数应用很少需要huge尺寸大小的内存分配,所以不需要考虑单棵树的可扩展性问题。
对于small和large的内存分配,chunk会使用binarybuddy算法切分出很多个run,每个run包含多个page。每个run可以进行一分为二的重复切分,直到切分为一个page尺寸大小为止,但只能按照切分过程的反向步骤合并回去。run的状态信息使用一个page map进行存储,并存储在每个chunk的开始位置。通过对run及其状态信息的分开存储,这样只有run被使用的时候,run所对应的page才会被访问。这也适用于使用run进行large的分配,其中large的分配超过半个page,但不超过半个chunk。
small的内存分配分为三个子类:tiny,quantum-spaced, and sub-page。现代架构会根据数据类型来进行指针对齐。Malloc(3)就需要保证返回的内存适当的对齐。这种最坏情况下的对齐要求在这里被称为quantum尺寸大小(通常为16个字节)对齐。在实际应用中,tiny的内存分配采用2的指数倍来进行对齐,因为采用足够大的quantum尺寸对齐后就没有空间来存储对象了。图4展示了所有分配尺寸的尺寸级别。
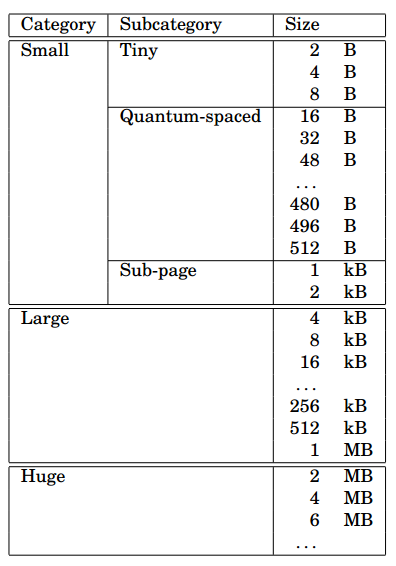
图4:默认的尺寸分类,以及默认的运行时取值,每个page尺寸大小4kb,每个quantum尺寸大小16byte。
当没有quantum-spaced这种子分类时,small尺寸的分配将会变得简单一些。然而大多数应用主要分配的对象大小都小于512byte,quantum尺寸的分类本质上减少了平均内部碎片。在quantum分类中较大的size可能会导致外部碎片的增加,但实际上,减少的内部碎片通常超过偏移量所增加的外部碎片。
small分配会按照分配的尺寸大小进行隔离,这样每个run只管理单一尺寸大小的内存分配。在每个run的前面会存储一个region位图,相较于其它方式会带来几个好处:
•通过位图可以快速扫描到第一个空闲的region,这可以将正在使用的region集中起来。
•分配器数据和应用数据能够实现分离。这可以减少应用破坏分配器数据的可能性。这也潜在的增加了应用数据的局部性,因为分配器的数据没有和应用数据混合。
•Tiny尺寸的region可以很容易得到支持。这比使用其它方式会更加简单,比如说在空闲region插入一个空闲列表。
使用为run存储头部的方式存在一个潜在的问题:头部使用的空间可能会被应用直接使用。因为run所维护的尺寸大小要比run的头部大,这会带来严重的外部碎片。(这句话在翻译时个人不是太理解:为什么会造成外部碎片?)为了限制外部碎片,所有的尺寸分类都采用多页的run,但除了最小的尺寸分类。最终在采用small尺寸分类下最大的尺寸(通常是2kb的region)时,外部碎片大概限制在3%。
由于每个run被限制了可管理的region的数量,必须为每种不同尺寸的类别提供多个run。在任何给定的时间,对于不同尺寸的类别都至多有一个“当前”run。当前run一直保持当前状态,直到它完全满了,或者完全空了。考虑到如果没有滞后机制,一次分配/释放都可能会导致一个run的创建/销毁。为了避免这个问题,run都会被按照使用量满的状态来分类,且run在QINIT类别时永远不会被销毁。如果一个run需要被销毁,它必须被提升到一个更高的满的类别(图5)。
按照满的程度的分类同样提供了一种机制,可以从大量未满的run中选择出一个新的当前run。顺序最好是:Q50,Q25,Q0,Q75。其中Q75是最后一个被选择的,因为Q75类别的run差不多已经满了;经常的选择Q75这类run会导致当前run出现快速的翻转。
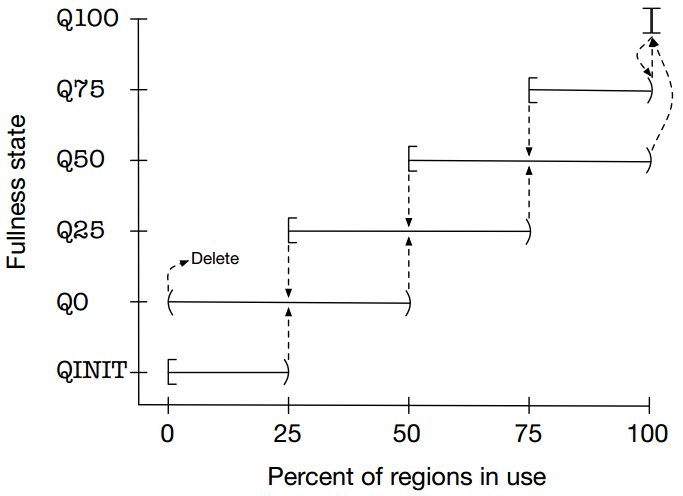
图5:按照run满的程度来进行分类,在创建/释放时按照各个变更阈值来完成状态之间的过度。run都起始于QINIT状态,当在Q0状态时变为空后将run删除。
实验
为了对jemalloc与phkmalloc的扩展性进行量化比较,我运行了两个多线程基准测试,和五个单线程基准测试,测试采用了一个四核处理器系统(dual-dual Opteron 275),使用FreeBSD-CURRENT/amd64 (2006年4月)。在进行基准性能测试之前,我调研了几个其它的线程安全分配器,但因为各种各样的可移植性问题,最终只包含了Doug Lea的dlmalloc。我对dlmalloc的2.8.3版本进行了修改,保证其能够集成到通用的libc之下,这样就能像phkmalloc和jemalloc一样使用libc提供的自旋锁同步机制。为了选择所使用的分配器,所有的基准测试都使用LD PRELOAD加载机制进行调用。在基准测试中使用了libthr,而没有使用libpthread,因为在这篇论文编写时libpthread存在的一个线程切换性能问题还没有被解决。
应该注意的是dlmalloc并不是一个为多线程程序提供可扩展性的分配器。出于完整性考虑,才把它放入到了所有的基准测试中,但主要目的是想把它放入到单线程基准测试之中。
多线程基准测试
malloc-test
malloc-test是Lever和Boreham(2000)发明的微基准测试,用来测量在多线程应用中分配器的可扩展性上限。这个基准测试会使用一个或者多个线程来循环执行密集的内存分配/释放操作。在一个多处理器系统中,当线程数到达处理器数量之前,理想状态分配器的吞吐量会随着线程数的增加而线性增加,然后当线程数超过处理器数量之后,分配器吞吐量会随着线程数的增加而保持在一个常数。图6显示了测试结果。
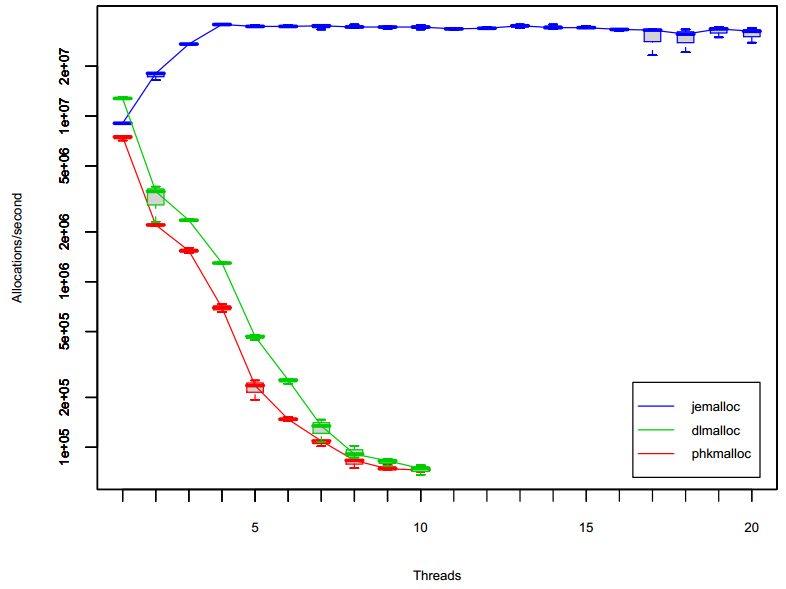
图6:分配器的吞吐量,横轴表示线程数,纵轴表示分配次数/秒。每次运行都会执行总计40,000,000次的分配/释放周期,且分配/释放次数平分到每个线程中,每个周期都会创建512byte的对象。相同配置下会重复进行3次测试,测试结果通过盒形图进行统计,其中中心线表示平均结果,而边沿线表示测量到的极限值。
当线程数量超过一个时,phkmalloc和dlmalloc都出现了严重的性能下降,并随着线程数量的增加性能显著持续下降。在这里没有显示它们超过10个线程后的结果数据,因为它们需要特别长的时间去运行。
jemalloc在增长到4个线程之前都扩展得很完美,在超过4个线程后保持着相对稳定,当超过16个线程后开始出现一些异常情况。在4核系统中jemalloc默认采用16个arena,所以在线程数量少于17个时竞争是很小的。当超过16个线程后,就会存在多个线程同时竞争某个arena,在其它线程完成之前,这些竞争arena的等待线程就会表现出相当糟糕的性能。
super-smack
第二个多线程基准测试采用了一个称为SuperSmack (http://vegan.net/tony/supersmack/)的数据库加载测试工具,版本1.3,它可以运行一个或者多个客户端线程来访问服务器——同时采用了MySQL 5.0.18。Super Smack本身包含两个预配置的加载测试,我使用了其中一个(select-key.smack)。每次运行super-smack测试都会进行大约200,000次查询了,这些查询会平均分配到客户端线程中。
测量结果的汇总如图7所示。使用jemalloc时,随着客户端线程的增加,性能出现了缓慢降低,且变化较慢,尤其是最坏的一次性能测试案例也变化较慢。当使用phkmalloc时,平均性能和jemalloc相当的,但最坏的一次性能测试案例的其性能变化非常巨大。除此之外,在使用75到80个客户端线程时,phkmalloc出现了急剧的性能掉落。dlmalloc的平均性能很好,但和phkmalloc相比,最坏的一次性能测试案例的性能变化要更大一些。
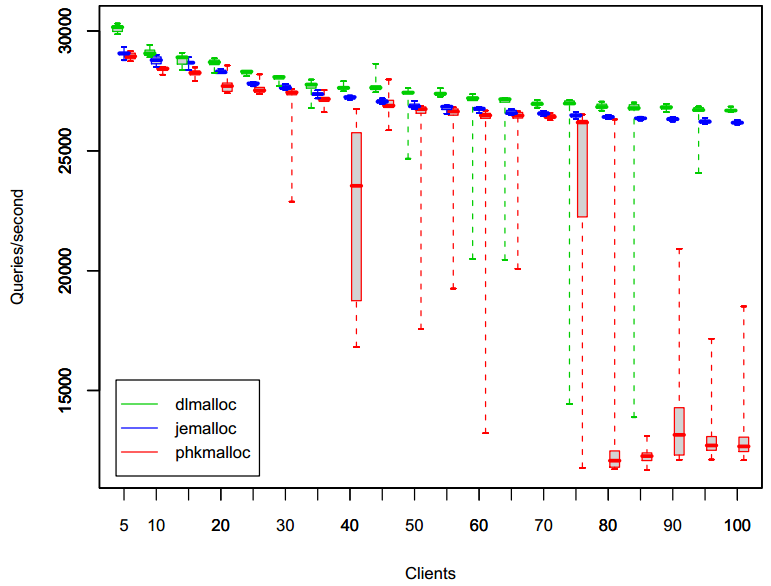
图7:MySQL的查询吞吐量,横坐标表示线程数量,纵坐标表示查询次数/每秒。每次运行大概总共进行100,000次查询,平均分配到每个客户端线程中。相同配置下会重复进行10次测试,并采用盒形图进行结果汇总。
单线程基准测试
我完成了五个单线程程序的基准测试。这些基准测试应该像一粒盐一样普通,因此我不得不进行既广又深地查找,以找到可显著显示出运行时差别的可重复测试。大多数实际应用在运行时都不会简单的严重依赖于malloc的性能。除此之外,需要大量使用网络和文件系统的程序,其多次运行变化较大,这需要进行多次重复试验才能评估出结果的意义。因此,基准测试本身可能会存在一些选择偏差,而这些基准测试本不应当仅代表部分程序类型的运行效果。
图8汇总了在单线程基准测试中的结果。更多基准测试的细节如下所示。
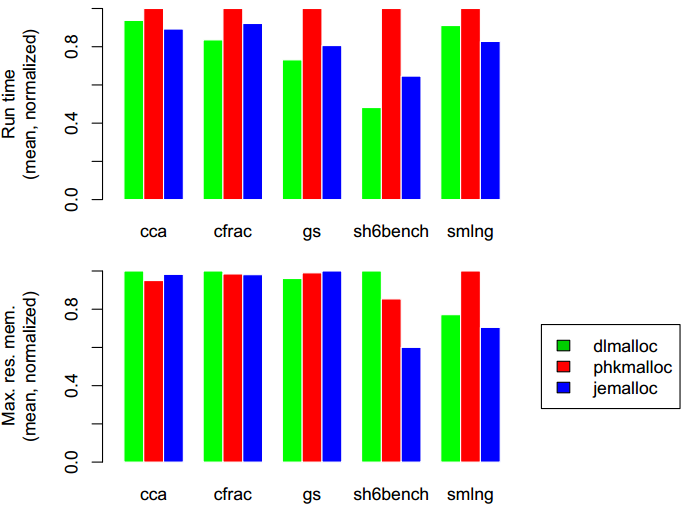
图8:按比例缩放了五个单线程程序的运行时间,和最大内存使用量。每个图都是按照线性比例进行缩放,且最大值是1.0。
cca
cca是一个需要大量使用正则表达式的perl脚本,可以从c代码中导出cpp逻辑,并生成cpp逻辑的各种各样的统计和附录图。在本文的实验中,我将FreeBSD的libc库中所有.c和.h文件连接起来,并将结果文件作为cca的输入。我从ports tree中检出了perl的5.8.8版本,并使用系统malloc对它进行了编译。下面是三次重复实验的汇总(也可以见图8):

cfrac
cfrac是一个分解大数因子的c程序。它本身包含了一个Hoard内存分配器(http://www.cs.umass.edu/˜emery/hoard/)。我使用大数47582602774358115722167492755475367767作为输入。下面是10次重复实验的汇总(也可以见图8):

cfrac需要大量分配16byte和32byte的对象,但是整个内存使用量并不大。好像dlmalloc要比其它两个分配器要多使用一点内存,是因为在分配小对象时它具有更多的内部碎片。
gs
gs(GhostScript)是一个附录解释器,我从poststree中检出了AFPL GhostScript 8.53。我使用了37MB的输入文件来运行gs:
gs -dBATCH -dNODISPLAY PS3.ps
下面是3次重复实验的汇总(也可以见图8):

gs会大量分配240byte或者大的对象,因为它使用了一个内部自定义的分配器。因此这个基准测试主要是针对大对象分配的性能测试。
因为大内存的使用,phkmalloc似乎受到了大量系统调用开销的波动,然而其它分配器内建了更多的滞后机制,可以减少整个系统调用的次数。jemalloc因为管理run的开销,并没有dlmalloc一样好的性能,这与dlmalloc直接调用mmap()形成了对比。
sh6bench
sh6bench是由microquill提供的微基准测试,可以从他们的网站上下载(http://www.microquill .com /)。这个程序会重复分配多组相同尺寸的对象,并在每个周期中以不同的顺序来保留一些对象,同时释放一些对象。在每一组中分配的小对象的数量要比分配的大对象的数量要多,所以sh6bench偏向于对小对象分配进行测试。
我修改了sh6bench,保证在每次调用完malloc()后会马上调用memset(),以确保所分配内存被真实引用到了。每次运行sh6bench都需要进行2500次迭代,对象的大小在1到1000范围内。下面是10次重复实验的汇总(也可以见图8):

在这次微基准测试中,和dlmalloc相比,jemalloc并没有表现出多大的劣势。在每次分配/释放时jemalloc都需要去操作每个run中region的位图,所以如果应用没有大量进行分配的话,jemalloc会遭受缓存局部性降低。在实际中只访问一次分配的内存是不现实的。jemalloc实际上可以提高应用的缓存局部性,因为它不会像dlmalloc的region头那样将位图延伸到region中。
正如在引言中提到的那样,合成跟踪在测量分配器性能时并不十分有用,sh6bench也不例外。在这三个分配器的内存使用中很难了解到究竟是什么造成了如此大的差异。
Smlng
smlng是一个Onyx(http://www.canonware.com/onyx/)程序。在2001年的ICFP编程大赛(http://cristal.inria.fr/ICFP2001/prog-contest/)中它实现了SML/NG的解析器和调优器。本次基准测试我使用了单线程的Onyx-5.1.2来搭建。我反复的将各种各样的SML/NG实例和测试用例连接起来,创建了一个513kb的文件作为输入。如下是10次重复实验的汇总(也可以见图8):

jemalloc似乎比phkmalloc使用更少的内存,主要是因为使用的内存尺寸类别不是2的指数倍:16,48,96,288。jemalloc在内存使用波动时对region的回收似乎也做得很好,然后由于dlmalloc的分配模型的原因,dlmalloc出现了不少外部碎片。
分析
详尽的基准测试是不可行的,因为基准测试并不能代表任意的场景。分配器的性能对应用的分配模型非常敏感,构造一个微基准测试来对这三个分配器中的任意一个进行测试是可行的,可以以此测量出分配器适合的和不适合的情景。我尽量避免了结果的扭曲,但不应该由读者来假定我的客观性。也就是说,要想让读者觉得我的基准测试是有效的,需要满足以下两个方面:
•在多处理器系统上运行多线程程序时,jemalloc的运行时性能应该具有很好的扩展性。
•jemalloc在单线程程序中的运行时间和内存使用方面,应该和phkmalloc、dlmalloc性能相当。
实时上jemalloc在基准测试中展现出了很好的性能,并且我觉得没有理由怀疑jemalloc在任何情况下与phkmalloc和dlmalloc存在本质上的差距,除非是一些专门设计的微基准测试。
没有设计用来进行内存压力测试的基准测试。这样的基准测试将会很有趣,但我没有包含他们的主要原因是phkmalloc在压力测试下已经显示出了很好的效果(Kamp, 1998; Feng and Berger, 2005),而jemalloc采用了非常相似的算法,它应该会展示出相似的性能。
对内存碎片很难进行分析,因为它本身是一个定性的问题,而标准工具只提供了定量的指标。在分析内存碎片时,对最大驻留内存使用量结果进行分析会有一定作用,因为在最大内存使用量时不同的分配器会表现出不同的碎片量。很显然如果分配器在最大驻留内存时,对应用来说没有一个实质性的影响,会导致数据局部性非常差。
为了更好的了解碎片,我使用“U” malloc(3)选项和ktrace(1),写了一个处理kdump(1)输出的程序。其中一个示例图如图9所示。利用这个程序我可以观察各种内存布局策略的效果,可以观察到现在的jemalloc,相对于前期开发的版本使用内存更加高效。
了解分配器在不同分配模式下的性能是一个永恒的挑战。在分配器和应用的开发过程中,更好的洞察分配器的运行机制是非常重要的。因此如果在libc编译时打开了可选代码,且指定了”P” malloc(3)选项,jemalloc就可以在运行结束时输出详细的统计信息。下面是运行cca基准测试时的详细输出。更详细的解释留给那些对阅读分配器源代码感兴趣的读者。然而在读完本论文后,大多数的统计信息还是很有含义的。
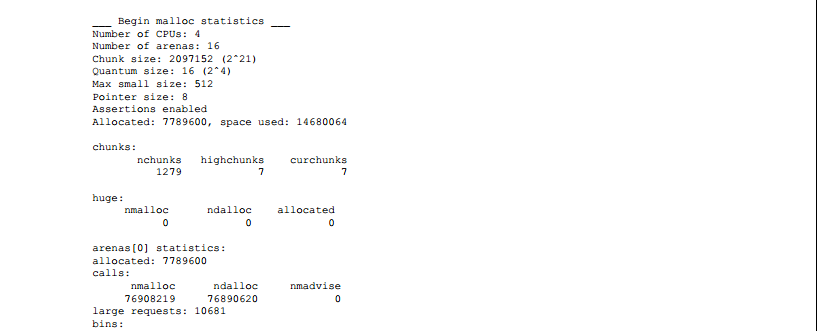
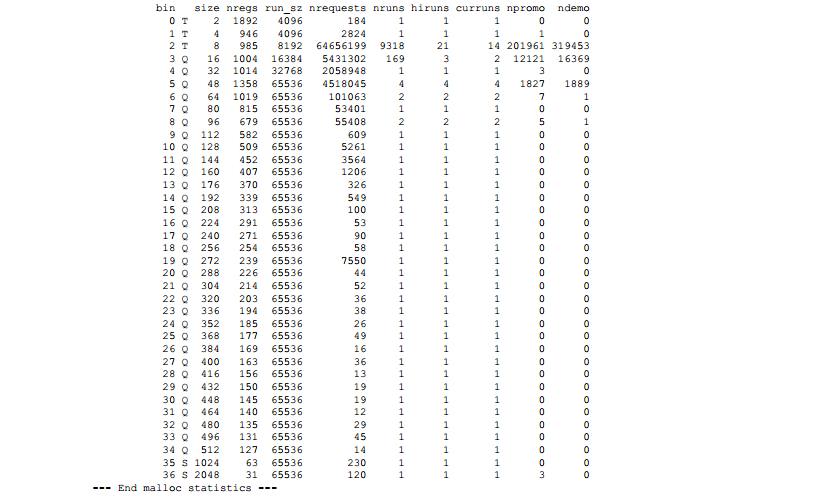
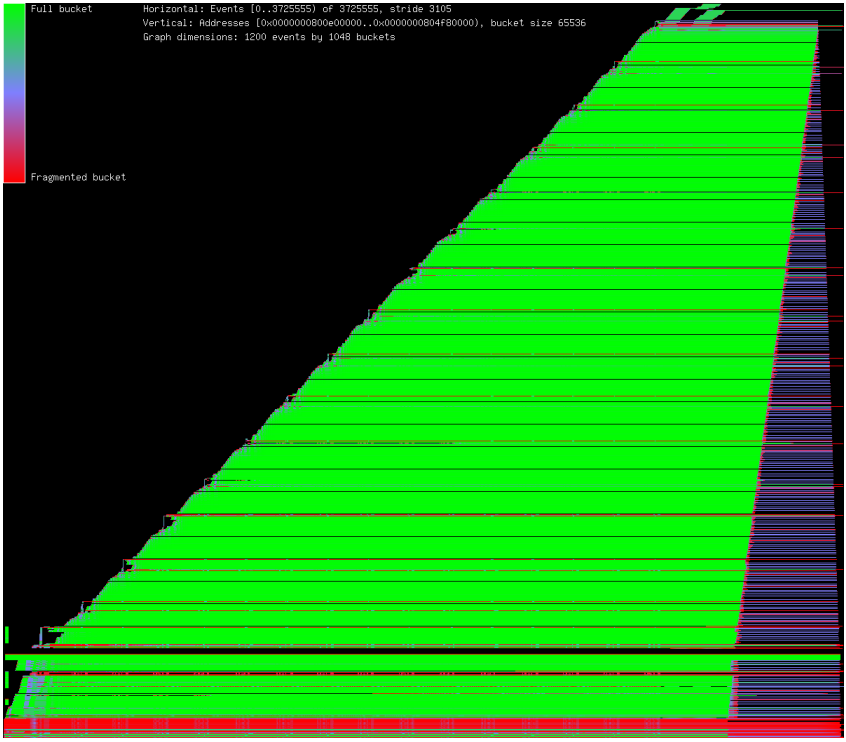
图9:在amd64上运行smlng基准测试时的内存使用图。在水平轴上的每个位置代表了在一个时间的瞬时快照,而时间通过分配事件进行离散测量。在垂直轴上的每个位置代表了内存的使用范围,而颜色表明了内存使用率。
讨论
在开发jemalloc的过程中遇到了一个不断困扰我的问题,就是观察那些甚至看上去无害的额外特性,例如维持每个arena中被完全分配的内存的计数器,或者是一些除法,都会导致可测量的性能损耗。相比于开发结束时,这个分配器在开始开发时具有更多的特性,主要包含以下被舍弃的特性:
• malloc_stats_np()。仅仅增加了对每个arena统计所有已分配内存的计数器,造成了可测量的性能损耗。因此在开发过程中所有与统计相关的功能都是默认关闭的。因为统计指标的可利用性没有给出,而一个c的api并不是太有用。
•各种正确性检测。即时是简单的检测都需要花费较大的代价,所以对于API来说只有绝对最小的检测才是必要的,才会被默认实现。
在一个更积极的层面来讲,对运行时分配器的配置机制已经被证明具有很好的灵活性,且不会造成严重的性能影响。
分配器的设计与实现对于个人来说有着强烈的吸引力,并且确实有人一直专注于这个领域。其中部分魅力在于没有任何一个分配器可以适用于所有的分配模型,所以对于新的软件所引入的新的分配模型,总需要对分配器进行一些微调。我希望jemalloc被证明在未来几年内是足够适应于FreeBSD的服务的。phkmalloc已经为FreeBSD服务十几年了;jemalloc还有很长的路要走。
可用性
jemalloc的源代码部分使用了FreeBSD的libc库,适用于BSD-like的许可。用于画内存使用率图的程序源代码,可以画出如图9基准测试中所生成的图。
致谢
在整个项目开发过程中,许多FreeBSD社区的人都提供了很有价值的帮助,在这里我就不全部列出了。Kris Kennaway为几个不同版本的jemalloc进行了广泛的稳定性和性能测试,揭露了很多问题。Peter Wemm提供了优化相关的专业性建议。Robert Watson提供了一个适合于远程访问的四核Operon系统,对早期的基准测试非常有用。当我的机器因为静电冲击故障后,Mike Tancsa提供了电脑硬件的支持。FreeBSD基金会为我慷慨的提供了差旅费用,这让我能在2006届BSDcan大会上展示我的工作成果。Aniruddha Bohra为我提供了分析碎片时的数据。Poul-Henning Kamp为我提供了本文的反馈信息,本质上提高了本文的质量。最后Rob Braun鼓励我承担本项目,并自始至终为我提供支持。
参考文献
Berger ED, McKinley KS, Blumofe RD, Wilson PR (2000) Hoard: AScalable Memory Allocator for Multithreaded Applications. ASPLOS 2000
Bohra A, Gabber E (2001) Are Mallocs Free of Fragmentation? InUSENIX 2001 Annual Technical Conference: FREENIX Track
Bonwick J, Adams J (2001) Magazines and Vmem: Extending the SlabAllocator to Many CPUs and Arbitrary Resources. In Proceedings of the 2001USENIX Annual Technical Conference
Butenhof DR (1997) Programming with POSIX Threads. Addison–Wesley,Reading, Massachusetts Feng Y, Berger ED (2005) A Locality-Improving DynamicMemory Allocator. MSP
Kamp PH (1998) Malloc(3) revisited. In USENIX 1998 AnnualTechnical Conference: Invited Talks and FREENIX Track, 193–198
Larson P, Krishnan M (1998) Memory allocataion for long-runningserver applications. In Proceedings of the International Symposium on MemoryManagement (ISSM), 176–185
Lever C, Boreham D (2000) malloc() Performance in a MultithreadedLinux Environment. In USENIX 2000 Annual Technical Conference: FREENIX Track
Wilson PR, Johnstone MS, Neely M, Boles D (1995) Dynamic StorageAllocation: A Survey and Critical Review. In Proceedings of the 1995International Workshop on Memory Management














 1501
1501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









