







一、数字音频
音频信号是一种连续变化的模拟信号,但计算机只能处理和记录二进制的数字信号,由自然音源得到的音频信号必须经过一定的变换,成为数字音频信号之后,才能送到计算机中作进一步的处理。
数字音频系统通过将声波的波型转换成一系列二进制数据,来实现对原始声音的重现,实现这一步骤的设备常被称为模/数转换器(A/D)。A/D转换器以每秒钟上万次的速率对声波进行采样,每个采样点都记录下了原始模拟声波在某一时刻的状态,通常称之为样本(sample),而每一秒钟所采样的数目则称为采样频率,通过将一串连续的样本连接起来,就可以在计算机中描述一段声音了。对于采样过程中的每一个样本来说,数字音频系统会分配一定存储位来记录声波的振幅,一般称之为采样分辨率或者采样精度,采样精度越高,声音还原时就会越细腻。
数字音频涉及到的概念非常多,对于在Linux下进行音频编程的程序员来说,最重要的是理解声音数字化的两个关键步骤:采样和量化。采样就是每隔一定时间就读一次声音信号的幅度,而量化则是将采样得到的声音信号幅度转换为数字值,从本质上讲,采样是时间上的数字化,而量化则是幅度上的数字化。
下面介绍几个在进行音频编程时经常需要用到的技术指标:
采样频率
采样频率是指将模拟声音波形进行数字化时,每秒钟抽取声波幅度样本的次数。采样频率的选择应该遵循奈奎斯特(Harry Nyquist)采样理论:如果对某一模拟信号进行采样,则采样后可还原的最高信号频率只有采样频率的一半,或者说只要采样频率高于输入信号最高频率的两倍,就能从采样信号系列重构原始信号。正常人听觉的频率范围大约在20Hz~20kHz之间,根据奈奎斯特采样理论,为了保证声音不失真,采样频率应该在40kHz左右。常用的音频采样频率有8kHz、11.025kHz、22.05kHz、16kHz、37.8kHz、44.1kHz、48kHz等,如果采用更高的采样频率,还可以达到DVD的音质。
量化位数
量化位数是对模拟音频信号的幅度进行数字化,它决定了模拟信号数字化以后的动态范围,常用的有8位、12位和16位。量化位越高,信号的动态范围越大,数字化后的音频信号就越可能接近原始信号,但所需要的存贮空间也越大。
声道数
声道数是反映音频数字化质量的另一个重要因素,它有单声道和双声道之分。双声道又称为立体声,在硬件中有两条线路,音质和音色都要优于单声道,但数字化后占据的存储空间的大小要比单声道多一倍。
二、声卡驱动
出于对安全性方面的考虑,Linux下的应用程序无法直接对声卡这类硬件设备进行操作,而是必须通过内核提供的驱动程序才能完成。在Linux上进行音频编程的本质就是要借助于驱动程序,来完成对声卡的各种操作。对硬件的控制涉及到寄存器中各个比特位的操作,通常这是与设备直接相关并且对时序的要求非常严格,如果这些工作都交由应用程序员来负责,那么对声卡的编程将变得异常复杂而困难起来,驱动程序的作用正是要屏蔽硬件的这些底层细节,从而简化应用程序的编写。
目前Linux下常用的声卡驱动程序主要有两种:OSS和ALSA。
ALSA和OSS最大的不同之处在于ALSA是由志愿者维护的自由项目,而OSS则是由公司提供的商业产品,因此在对硬件的适应程度上OSS要优于ALSA,它能够支持的声卡种类更多。ALSA虽然不及OSS运用得广泛,但却具有更加友好的编程接口,并且完全兼容于OSS,对应用程序员来讲无疑是一个更佳的选择。
三、Linux OSS音频设备驱动
3.1 OSS驱动的组成
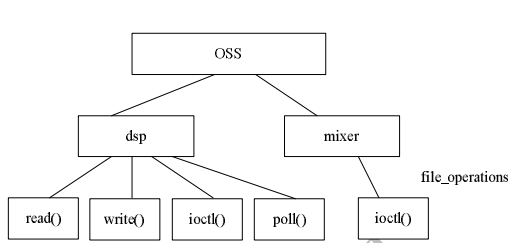
OSS标准中有2个最基本的音频设备:mixer(混音器)和DSP(数字信号处理器)。
在声卡的硬件电路中,mixer是一个很重要的组成部分,它的作用是将多个信号组合或者叠加在一起,对于不同的声卡来说,其混音器的作用可能各不相同。OSS驱动中,/dev/mixer设备文件是应用程序对mixer进行操作的软件接口。
混音器电路通常由两个部分组成:输入混音器(input mixer)和输出混音器(output mixer)。输入混音器负责从多个不同的信号源接收模拟信号,这些信号源有时也被称为混音通道或者混音设备。模拟信号通过增益控制器和由软件控制的音量调节器后,在不同的混音通道中进行级别(level)调制,然后被送到输入混音器中进行声音的合成。混音器上的电子开关可以控制哪些通道中有信号与混音器相连,有些声卡只允许连接一个混音通道作为录音的音源,而有些声卡则允许对混音通道做任意的连接。经过输入混音器处理后的信号仍然为模拟信号,它们将被送到A/D转换器进行数字化处理。
输出混音器的工作原理与输入混音器类似,同样也有多个信号源与混音器相连,并且事先都经过了增益调节。当输出混音器对所有的模拟信号进行了混合之后,通常还会有一个总控增益调节器来控制输出声音的大小,此外还有一些音调控制器来调节输出声音的音调。经过输出混音器处理后的信号也是模拟信号,它们最终会被送给喇叭或者其它的模拟输出设备。对混音器的编程包括如何设置增益控制器的级别,以及怎样在不同的音源间进行切换,这些操作通常来讲是不连续的,而且不会像录音或者放音那样需要占用大量的计算机资源。由于混音器的操作不符合典型的读/写操作模式,因此除了 open()和close()两个系统调用之外,大部分的操作都是通过ioctl()系统调用来完成的。与/dev/dsp不同,/dev/mixer允许多个应用程序同时访问,并且混音器的设置值会一直保持到对应的设备文件被关闭为止。
DSP也称为编解码器,实现录音(录音)和放音(播放),其对应的设备文件是/dev/dsp或/dev/sound/dsp。OSS声卡驱动程序提供的 /dev/dsp是用于数字采样和数字录音的设备文件,向该设备写数据即意味着激活声卡上的D/A转换器进行放音,而向该设备读数据则意味着激活声卡上的 A/D转换器进行录音。
在从DSP设备读取数据时,从声卡输入的模拟信号经过A/D转换器变成数字采样后的样本,保存在声卡驱动程序的内核缓冲区中,当应用程序通过 read()系统调用从声卡读取数据时,保存在内核缓冲区中的数字采样结果将被复制到应用程序所指定的用户缓冲区中。需要指出的是,声卡采样频率是由内核中的驱动程序所决定的,而不取决于应用程序从声卡读取数据的速度。如果应用程序读取数据的速度过慢,以致低于声卡的采样频率,那么多余的数据将会被丢弃(即overflow);如果读取数据的速度过快,以致高于声卡的采样频率,那么声卡驱动程序将会阻塞那些请求数据的应用程序,直到新的数据到来为止。
在向DSP设备写入数据时,数字信号会经过D/A转换器变成模拟信号,然后产生出声音。应用程序写入数据的速度应该至少等于声卡的采样频率,过慢会产生声音暂停或者停顿的现象(即underflow)。如果用户写入过快的话,它会被内核中的声卡驱动程序阻塞,直到硬件有能力处理新的数据为止。
与其它设备有所不同,声卡通常不需要支持非阻塞(non-blocking)的I/O操作。即便内核OSS驱动提供了非阻塞的I/O支持,用户空间也不宜采用。
无论是从声卡读取数据,或是向声卡写入数据,事实上都具有特定的格式(format),如无符号8位、单声道、8KHz采样率,如果默认值无法达到要求,可以通过ioctl()系统调用来改变它们。通常说来,在应用程序中打开设备文件/dev/dsp之后,接下去就应该为其设置恰当的格式,然后才能从声卡读取或者写入数据。
3.2 mixer接口
int register_sound_mixer(structfile_operations *fops, int dev);
上述函数用于注册1个混音器,第1个参数fops即是文件操作接口,第2个参数dev是设备编号,如果填入-1,则系统自动分配1个设备编号。mixer 是 1个典型的字符设备,因此编码的主要工作是实现file_operations中的open()、ioctl()等函数。
mixer接口file_operations中的最重要函数是ioctl(),它实现混音器的不同IO控制命令。
3.3 DSP接口
int register_sound_dsp(structfile_operations *fops, int dev);
上述函数与register_sound_mixer()类似,它用于注册1个dsp设备,第1个参数fops即是文件操作接口,第2个参数dev是设备编号,如果填入-1,则系统自动分配1个设备编号。dsp也是1个典型的字符设备,因此编码的主要工作是实现file_operations中的read()、write()、ioctl()等函数。
dsp接口file_operations中的read()和write()函数非常重要,read()函数从音频控制器中获取录音数据到缓冲区并拷贝到用户空间,write()函数从用户空间拷贝音频数据到内核空间缓冲区并最终发送到音频控制器。
dsp接口file_operations中的ioctl()函数处理对采样率、量化精度、DMA缓冲区块大小等参数设置IO控制命令的处理。
在数据从缓冲区拷贝到音频控制器的过程中,通常会使用DMA,DMA对声卡而言非常重要。例如,在放音时,驱动设置完DMA控制器的源数据地址(内存中 DMA缓冲区)、目的地址(音频控制器FIFO)和DMA的数据长度,DMA控制器会自动发送缓冲区的数据填充FIFO,直到发送完相应的数据长度后才中断一次。
在OSS驱动中,建立存放音频数据的环形缓冲区(ring buffer)通常是值得推荐的方法。此外,在OSS驱动中,一般会将1个较大的DMA缓冲区分成若干个大小相同的块(这些块也被称为“段”,即 fragment),驱动程序使用DMA每次在声音缓冲区和声卡之间搬移一个fragment。在用户空间,可以使用ioctl()系统调用来调整块的大小和个数。
除了read()、write()和ioctl()外,dsp接口的poll()函数通常也需要被实现,以向用户反馈目前能否读写DMA缓冲区。
在OSS驱动初始化过程中,会调用register_sound_dsp()和register_sound_mixer()注册dsp和mixer设备;在模块卸载的时候,会调用unregister_sound_dsp(audio_dev_dsp)和unregister_sound_mixer(audio_dev_mixer)。
Linux OSS驱动结构如下图所示:
3.4 OSS用户空间编程
1、DSP编程DSP接口的操作一般包括如下几个步骤:
① 打开设备文件/dev/dsp
采用何种模式对声卡进行操作也必须在打开设备时指定,对于不支持全双工的声卡来说,应该使用只读或者只写的方式打开,只有那些支持全双工的声卡,才能以读写的方式打开,这还依赖于驱动程序的具体实现。Linux允许应用程序多次打开或者关闭与声卡对应的设备文件,从而能够很方便地在放音状态和录音状态之间进行切换。
② 如果有需要,设置缓冲区大小
运行在Linux内核中的声卡驱动程序专门维护了一个缓冲区,其大小会影响到放音和录音时的效果,使用ioctl()系统调用可以对它的尺寸进行恰当的设置。调节驱动程序中缓冲区大小的操作不是必须的,如果没有特殊的要求,一般采用默认的缓冲区大小也就可以了。如果想设置缓冲区的大小,则通常应紧跟在设备文件打开之后,这是因为对声卡的其它操作有可能会导致驱动程序无法再修改其缓冲区的大小。
③ 设置声道(channel)数量
根据硬件设备和驱动程序的具体情况,可以设置为单声道或者立体声。
④ 设置采样格式和采样频率
采样格式包括AFMT_U8(无符号8位)、AFMT_S8(有符号8位)、AFMT_U16_LE(小端模式,无符号16位)、 AFMT_U16_BE(大端模式,无符号16位)、AFMT_MPEG、AFMT_AC3等。使用SNDCTL_DSP_SETFMT IO控制命令可以设置采样格式。
对于大多数声卡来说,其支持的采样频率范围一般为5kHz到44.1kHz或者48kHz,但并不意味着该范围内的所有连续频率都会被硬件支持,在 Linux下进行音频编程时最常用到的几种采样频率是11025Hz、16000Hz、22050Hz、32000Hz 和44100Hz。使用SNDCTL_DSP_SPEED IO控制命令可以设置采样频率。
⑤ 读写/dev/dsp实现播放或录音
2. mixer编程
声卡上的混音器由多个混音通道组成,它们可以通过驱动程序提供的设备文件/dev/mixer进行编程。
对声卡的输入增益和输出增益进行调节是混音器的一个主要作用,目前大部分声卡采用的是8位或者16位的增益控制器,声卡驱动程序会将它们转换成百分比的形式,也就是说无论是输入增益还是输出增益,其取值范围都是从0~100。














 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









