









在上一篇我们介绍了Genome类的一大堆函数,大家不要慌,所谓需求驱动进步,我们就着遗传算法的流程图中的三大关键算子(selection,copulation,heteromorphosis)来看,这样我们就会很自然的思考出来思路而不必陷入一大堆函数里不知所措。
更新.
*修改了变异操作,将单点变异变成了区间倒置,因为区间倒置对于TSP问题更加有效.
*轮盘赌操作的时候总是选择一个当前的最优个体,提高了算法的效率
注意!!! 一些很简单的函数,比如某变量的get(),set(),作者就不在赘述,避免篇幅膨胀。
初始化
在所有的函数开始之前我们要初始化我们即将用到的变量。在TSP问题中我们需要:
1. 随机初始化种群个体(不要有重复个体)
1) 随机初始化个体DNA(注意消除重复基因)
2)计算随机个体的适应度(_fittness),以及种群总适应度(_totalFittness)
3)根据适应度选出当前代的最优个体(_currBestIndividual),以及上一代最优个体(_lastBestIndividual),这两个最优个体只有在第一代相同
2.初始化距离矩阵(_distanceOfCities)
根据上述的需求我们有了以下函数:
void initPopulation(); //初始化种群
void initDisArr(); //初始化距离矩阵
double fitness(Individual &indexOfIndividual); //适应度函数,计算某一个个体适应度
Individual findBestIndividual(); //返回当前世代的最优个体
bool isSameIndividual(Individual &individual1, Individual &individual2);//比较两个个体是否相同。 相同则返回true部分函数代码
void GenomeTSP::initPopulation(){
//随机数种子
srand(static_cast<unsigned int>(time(0)));
//生成初始种群
int i=0;
while (i<MAX_INIT_POPULATION_COUT){
Individual tempIndividual=Individual();
tempIndividual._fittness=0; //初始化适应度
int DNA_Num=0;
//随机编写每一个个体DNA,DNA数量和城市数目对应
while(DNA_Num<MAX_DNA_SIZE){
//新的DNA片段
int newDNASegment=rand()%MAX_CITY_COUNT;
//检测是否重复
if(find(tempIndividual._DNA.begin(),
tempIndividual._DNA.end(),
newDNASegment)==tempIndividual._DNA.end()){
//不重复,则插入
tempIndividual._DNA.push_back(newDNASegment);
DNA_Num++;
}
}//create_unique_DNA
//生成互不相同的个体
bool hasSameInvididual=false;
for(size_t j=0;j<_populationVec.size();++j){
if(isSameIndividual(tempIndividual,_populationVec.at(j))){
hasSameInvididual=true;
}
}
if(!hasSameInvididual){
_populationVec.push_back(tempIndividual);
i++;
}
}
//初始化适应度
for (int i=0;i<_populationVec.size();i++){
fitness(_populationVec.at(i));
_totalFittness+=fitness(_populationVec.at(i));
}
//初始化当前和上一世代最优个体
_lastBestIndividual=findBestIndividual();
_currBestIndividual=findBestIndividual();
}
double GenomeTSP::fitness(Individual &individual){
//计算适应度,求DNA序列中相邻两个城市的距离,距离通过距离矩阵获取
for(size_t i=0;i<individual._DNA.size()-1;i++){
individual._fittness+=_distanceOfCities[individual._DNA.at(i)][individual._DNA.at(i+1)];
}
//记得是倒数
individual._fittness=1/individual._fittness;
return individual._fittness;
}
bool GenomeTSP::isSameIndividual(Individual &individual1, Individual &individual2){
for(size_t i=0;i<individual1._DNA.size();++i){
if(individual1._DNA.at(i)!=individual2._DNA.at(i)){
return false;
}
}
return true;
}
}选择算法
ok,搞定完初始化接下来我们就要搞选择算法,选择算法使用了轮盘赌的方法。
就像是扔飞镖的游戏

在我们的遗传算法里,轮盘赌类似:
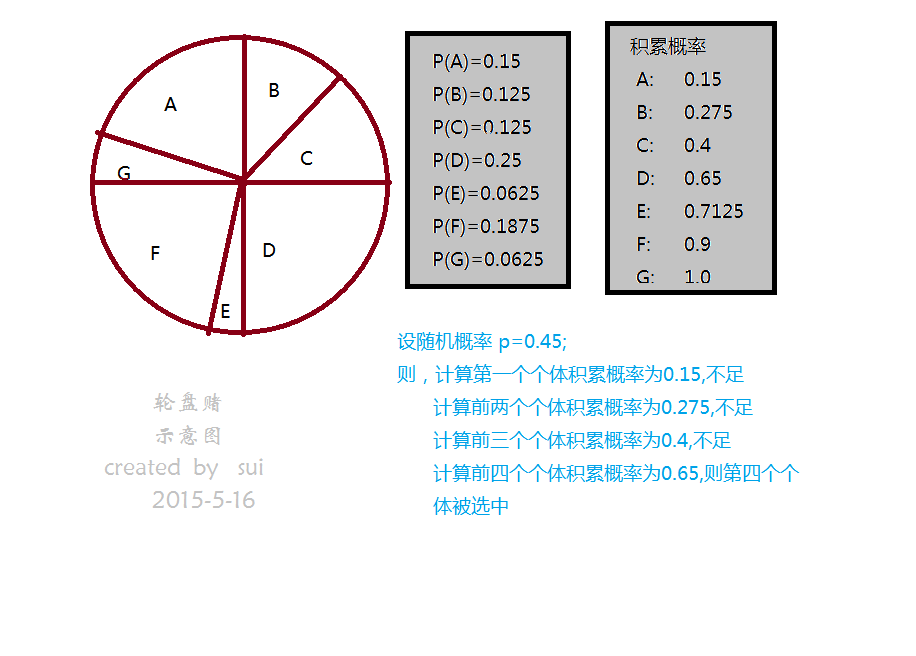
代码如下:
//随机种子
srand(static_cast<unsigned int >(time(NULL)));
//选择第一个个体
float naturalPossibility=rand()/(RAND_MAX+1.0f)*_totalFittness;
Individual indi1,indi2;
//遍历种群按照适应度概率淘汰不适应的,最好不要使用在本vector进行erase操作,不仅iterator会变化,而且遍历的条件也会变化,很繁琐
float livePossibility=0.0f;
Population::iterator it;
for(it=_populationVec.begin();it!=_populationVec.end();it++){
livePossibility+=(*it)._fittness;
if(livePossibility>naturalPossibility){//如果符合自然规律
indi1=*it;
}
}
// naturalPossibility=(rand()%1000)*0.0001f*_totalFittness;
// for(it=_populationVec.begin();it!=_populationVec.end();it++){
// livePossibility+=(*it)._fittness;
// if(livePossibility>naturalPossibility && (*it)._fittness!=indi1._fittness){//如果符合自然规律
// indi2=*it;
// }
// }
return make_pair(indi1,_currBestIndividual);
}怎么样,其实轮盘赌很简单吧。在作者的轮盘赌算法里,刻意选择了两个不相同的个体,为了交叉变异产生更多的变化.
变异算法
由于交叉算法较为繁琐,所以留在下一篇讲解,这一片先介绍变异算法.
变异算法网上的各种说法比较多,作者举两个例子
1). 随机某一个位置直接变异出新DNA片段,将被选中位置的DNA片段放到DNA序列的末尾,同时消除与变异DNA相同的DNA片段。
2). 随机选择某一区间,将区间内的DNA片段倒置
在这里作者选用了第一种。(现已修改为第二种-2015-5-20-)
示意图如下:
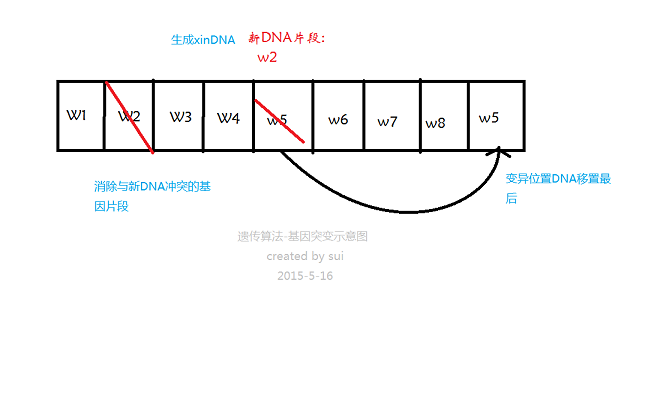
现变异操作
void GenomeTSP::heteromorphosis(Individual &individual){//变异算法
srand(static_cast<unsigned int>(time(NULL)));
float poss=rand()/(RAND_MAX+1.0f);
if(poss>0.6f && poss<0.9f){
//随机选择一个位置
pair<int,int> hetrPos=getRandomCopuSec();
/*----------新版变异,将变异区间倒置---------*/
DNA tempDNA;
copyDNASeg(individual._DNA,hetrPos.first,hetrPos.second,tempDNA);
for(int i=hetrPos.first,j=tempDNA.size()-1;i<=hetrPos.second,j>=0;i++,j--){
individual._DNA.at(i)=tempDNA.at(j);
}
}
}原变异操作
void GenomeTSP::heteromorphosis(Individual &individual){//变异算法
//随机选择一个位置
srand(static_cast<unsigned int>(time(0)));
//选择变异的DNA位置
int heteroPosition=(rand()%(individual._DNA.size())); //选择当前DNA序列长度中的随机位置
//重新生成DNA片段
int newDNASegment=(rand()%MAX_CITY_COUNT);
//旧的DNA偏短放到最后,
int oldDNASegment=(individual._DNA.at(heteroPosition));
individual._DNA.push_back(oldDNASegment);
//替换旧的DNA片段
individual._DNA.at(heteroPosition)=newDNASegment;
//删除与新DNA冲突的重复片段
eliminateDNAConfilct(individual,newDNASegment,heteroPosition);消除冲突算法
//消除个体DNA中的冲突元素,其中heteroPos位置为变异保存位置,此位置的冲突不可删除,confilctDNASeg为冲突的元素
void GenomeTSP::eliminateDNAConfilct(Individual &individual,int confilctDNASeg, int heteroPos){
DNA tempDNAVec; //临时保存
int index=0;
for(auto it=individual._DNA.begin();it!=individual._DNA.end();it++,index++){//把正确的元素复制出去
if( (*it)==confilctDNASeg && index!=heteroPos){//把和变异的newDNA相同但不是变异位置的DNA片段跳过
continue;
}
else
tempDNAVec.push_back((*it));
}
//清除原个体DNA,并复制回去
individual._DNA.clear();
individual._DNA=tempDNAVec;
}终
这一篇我们介绍了选择算法和变异算法,两个算法原理上都很简单,不过在实际应用中参数的设定比较重要。下一篇的交叉算法稍有难度,不过连作者这么笨的人都能做出来,相信聪明的你一定没问题。
我们下一篇再见。














 6311
6311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









