




 Rocchio算法是一种相关反馈技术,用于优化查询向量。在已知部分相关和不相关文档的情况下,通过调整原始查询向量,使其接近相关文档的质心向量,远离不相关文档的质心向量。公式中包含原始查询向量、相关文档集合和不相关文档集合的权重。这种技术能提高信息检索的召回率和正确率,尤其在重召回率场景下。参数α、β和γ控制着查询向量的更新,实际应用中常倾向于正反馈,即γ通常小于β。Ide dec-hi公式被研究认为在性能上表现稳定。
Rocchio算法是一种相关反馈技术,用于优化查询向量。在已知部分相关和不相关文档的情况下,通过调整原始查询向量,使其接近相关文档的质心向量,远离不相关文档的质心向量。公式中包含原始查询向量、相关文档集合和不相关文档集合的权重。这种技术能提高信息检索的召回率和正确率,尤其在重召回率场景下。参数α、β和γ控制着查询向量的更新,实际应用中常倾向于正反馈,即γ通常小于β。Ide dec-hi公式被研究认为在性能上表现稳定。
Rocchio算法是IR中通过查询的初始匹配文档对原始查询进行修改以优化查询的方法。Rocchio 算法是相关反馈实现中的一个经典算法,它提供了一种将相关反馈信息融到向量空间模型的方法。基本理论:假定我们要找一个最优查询向量q ,它与相关文档之间的相似度最大且同时又和不相关文档之间的相似度最小。若Cr表示相关文档集,Cnr表示不相关文档集,那么我们希望找到的最优的q 是:
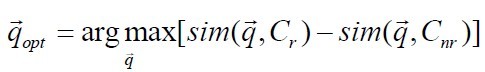
sim 函数用于计算相似度。采用余弦相似度计算时,能够将相关文档与不相关文档区分开的最优查询向量为:
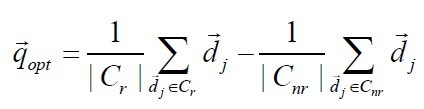
这就是说,最优的查询向量等于相关文档的质心向量和不相关文档的质心向量的差。然而,这个发现并没有什么意义,因为检索本来的目的就是要找相关文档,而所有的相关文档集事先却是未知的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4775
4775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









