







1、如果启动报sudo相关命令错误,是因为启动用户未在sudoers里面,需要将用户添加到此文件中,添加方法搜下root位置,再后面添加即可。
内容如下:
| root ALL=(ALL) ALL hadoop ALL=(ALL) ALL |
同时把此文件中的:#Defaults requiretty 注释掉。
2、经过上面的设置之后,通过 alluxio-start.sh all 时,又报了另外一个错误,
| [sudo] password for hadoop |
的错误,解决方法如下:
| hadoop ALL=(ALL) NOPASSWD:ALL |
即可。
3、再次通过 alluxio-start.sh all 命令启动整个集群,但是启动worker时报错,报错内容:Pseudo-terminal will not be allocated because stdin is not a terminal。解决方法如下:
更改:alluxio\bin\alluxio-workers.sh 的44行内容
原始内容为:
| nohup ssh -o ConnectTimeout=5 -o StrictHostKeyChecking=no -t ${worker} ${LAUNCHER} \ |
改成如下:
| nohup ssh -o ConnectTimeout=5 -o StrictHostKeyChecking=no -tt $ {worker} ${LAUNCHER} \ |
4、经过上面的处理之后,通过 alluxio-start.sh all 命令再次启动集群时,Worker上的 AlluxioWorker 进程还是没有,然后在 alluxio-1.2.0/logs 目录下有一个 worker.out 文件,其中的内容如下:
| which: no java in (/sbin:/bin:/usr/sbin:/usr/bin) dirname: 缺少操作数 请尝试执行"dirname --help"来获取更多信息。 ALLUXIO_RAM_FOLDER was not set. Using the default one: /mnt/ramdisk Formatting RamFS: /mnt/ramdisk (1gb) Starting worker @ HDFS-YARN-2. Logging to /usr/alluxio-1.2.0/logs |
从错误信息中,可以看出,在启动脚本中运行which java 时报错了,然后找到报错的脚本,脚本内容如下:
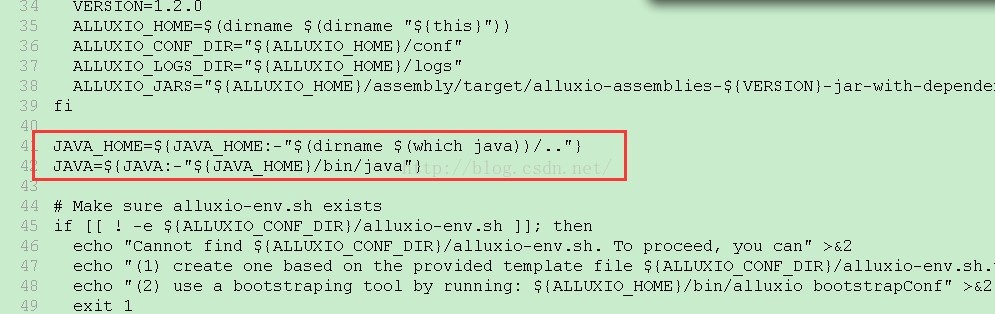
但是,我们已经在 /etc/profile 中已经配置了 JAVA_HOME,并将 JAVA_HOME/bin 加入到了 PATH 中了,如图:
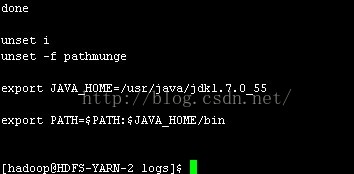
,并且在命令行中单独运行 which java 是没有问题的。
| [hadoop@HDFS-YARN-2 logs]$ which java /usr/java/jdk1.7.0_55/bin/java [hadoop@HDFS-YARN-2 logs]$ |
并且我又在 bin/alluxio-env.sh中,又配置了 JAVA_HOME 了,可为什么不行呢,原因还在上面的脚本中,可以看到其先是进行Java是否存在的判断,之后再进行conf/alluxio-env.sh脚本的运行,所以不管再怎么在alluxio-env.sh中设置JAVA_HOME已经没有用了。解决方法:
将两处的内容对调,如下图:
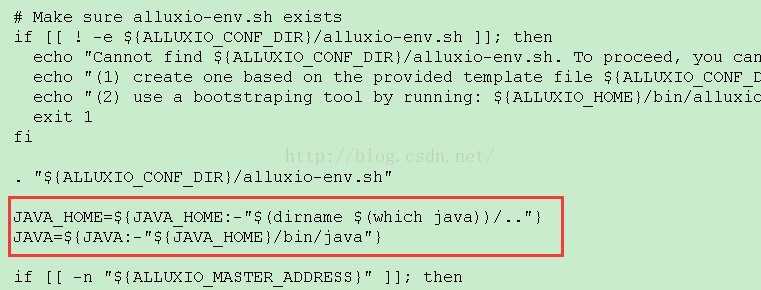
再次运行 alluxio-start.sh all 脚本,此时,整个集群启来了。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









