









这一期的神作论文有蛮多的,都非常有意思。
Feature Representation In ConvolutionalNeural Networks
该论文中论述了在某种CNN结构下,是否有准确率较高的off model的分类方法(这里是指非softmax)能达到更有效的分类结果呢?
论文给出了肯定的答案。
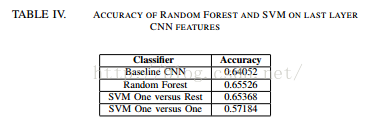
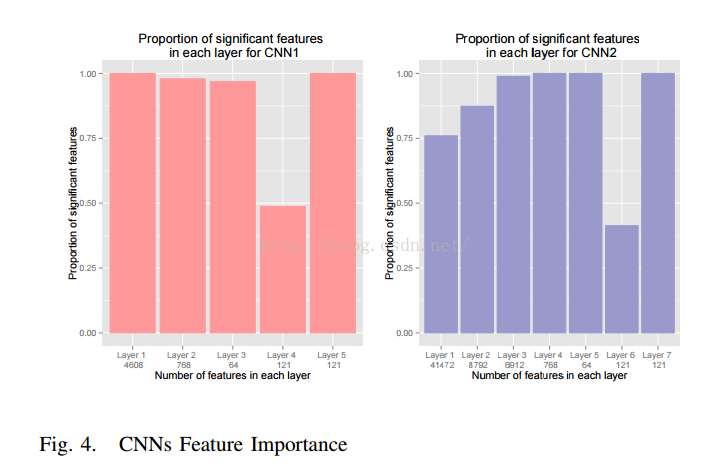
该论文还给出了各层特征重要性的图表,蛮有意思的
该论文还交代了实验中用到的开源代码。
Towards Good Practices for Very DeepTwo-Stream ConvNets

Openmpi for multi-gpu
Code: https://github.com/yjxiong/caffe/tree/action_recog
Two-Stream Convolutional Networks forAction Recognition in Videos

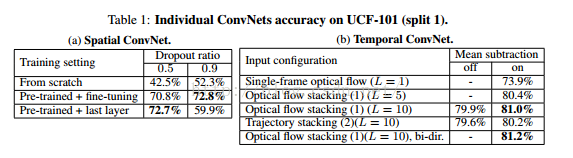
其中单个stream的准确率如下:
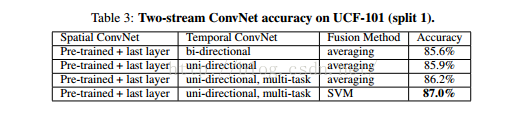
Combine的结果如下:
Understanding Intra-Class Knowledge InsideCNN
该论文利用可视化技术表述了cnn是如何进行类内区分的
另外在该文中也有引用到利用可视化表述cnn如何进行类间区分的。
是很好的一篇cnn可视化理解文章
COMPRESSING DEEP CONVOLUTIONAL NETWORKSUSING VECTOR QUANTIZATION
该论文描述了手机级别的模型存储压缩,非常好的一篇论文。
其实模型参数的压缩不仅会起到存储空间压缩(PQ)的作用,还会起到加速模型的作用例如SVD。
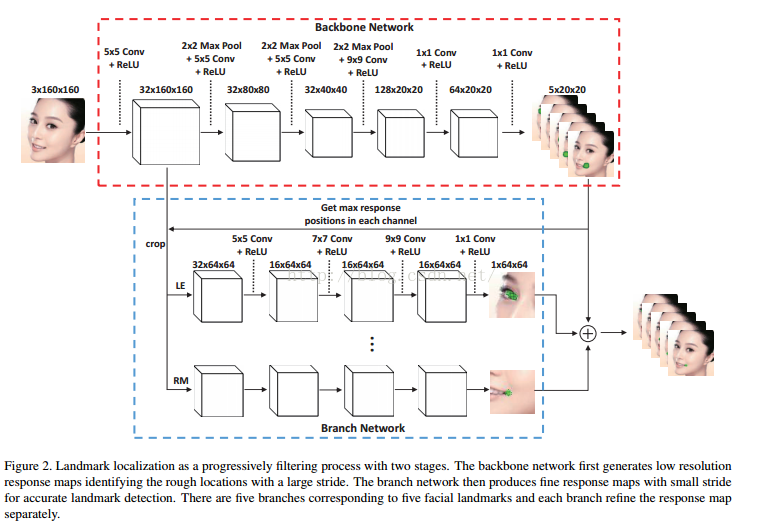
Unconstrained Facial Landmark Localizationwith Backbone-Branches Fully-Convolutional Networks
论文提出了Backbone-Branches Fully-Convolutional Neural Network (BB-FCN)的网络结构,非常有趣,论文中还给出了很多商业非商业的方法做比较,是一篇很好的人脸定位切入文章。
其中的网络结构如下:
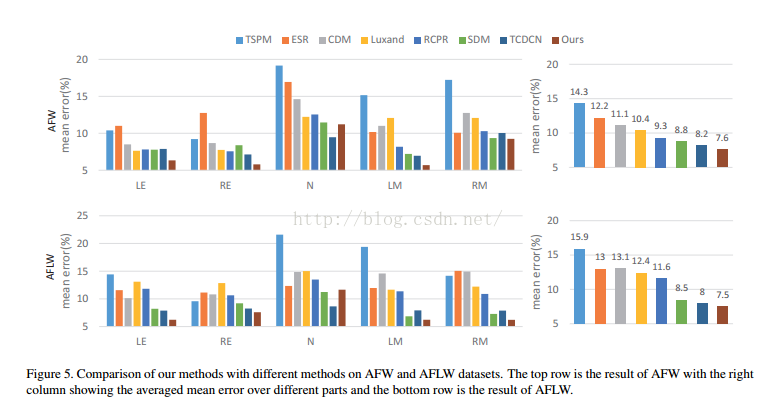
结果对比表格:
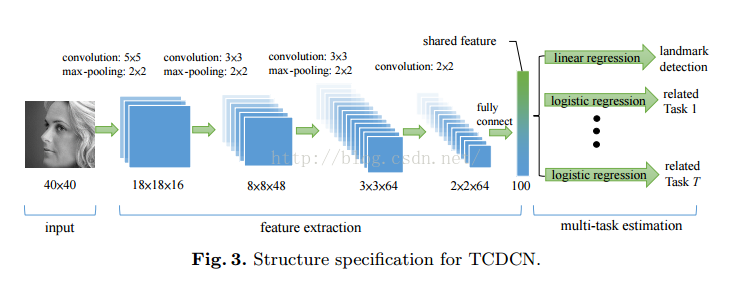
Facial Landmark Detection by DeepMulti-task Learning















 881
881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











