







1、Apache Arrow:一个跨平台的内存数据交换格式
Apache Arrow是Apache基金会下一个全新的开源项目,同时也是顶级项目。它的目的是作为一个跨平台的数据层来加快大数据分析项目的运行速度。
用户在应用大数据分析时除了将Hadoop等大数据平台作为一个经济的存储和批处理平台之外也很看重分析系统的扩展性和性能。过去几年开源社区已经发布了很多工具来完善大数据分析的生态系统,这些工具涵盖了数据分析的各个层面,比如列式存储格式(Parquet/ORC)、内存计算层(Drill、Spark、Impala和Storm)以及强大的API接口(Python和R语言)。Arrow则是最新加入的一员,它提供了一种跨平台跨应用的内存数据交换格式。
提高大数据分析性能的一个重要手段是对列式数据的设计和处理。列式数据处理借助向量计算和SIMD使我们可以充分挖掘硬件的潜力。Apache Drill这一大数据查询引擎无论是在硬盘还是在内存中数据都是以列的方式存在的,而Arrow就是由Drill中ValueVector这一数据格式发展而来。除了列式数据,Apache Arrow也支持关系型和动态数据集,这使它成了处理物联网等数据时的理想格式选择。
Apache Arrow为大数据生态系统带来了可能性是无穷的。有Apache Arrow做为今后的标准数据交换格式,各个数据分析的系统和应用之间的交互性可以说是上了一个新的台阶。过去大部分的CPU周期都花在了数据的序列化和反序列化上,现在我们则能够实现不同系统之间数据的无缝共享。这意味着用户在将不同的系统结合使用时再也不用为数据格式多花心思了。
Performance Advantage of Columnar In-Memory
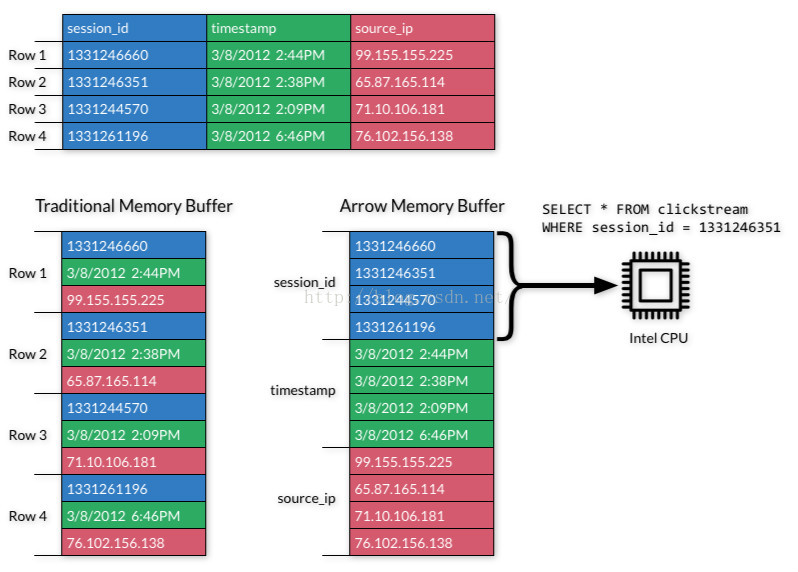
Advantages of a Common Data Layer
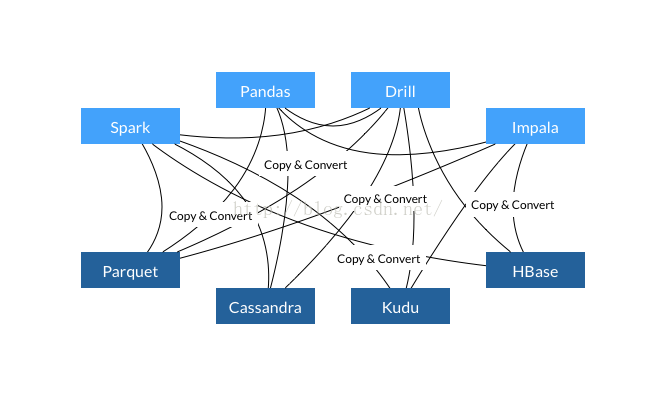
每个系统都有自己内部的内存格式
70-80%的CPU浪费在序列化和反序列化过程
类似功能在多个项目中实现,没有一个标准
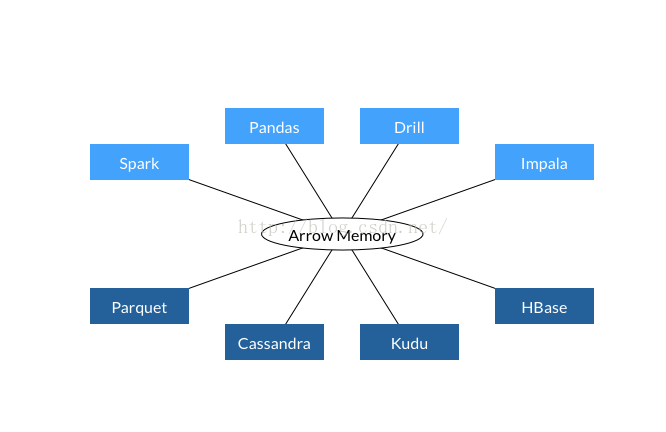
所有系统都使用同一个内存格式
避免了系统间通信的开销
项目间可以共享功能(比如Parquet-to-Arrow reader)
Apache Arrow可以使得数据的随机访问达到O(1)。这是因为Apache Arrow对分析结构化的数据进行了优化,如下的数据:
people = [
{
name: ‘mary’, age: 30,
places_lived: [
{city: ‘Akron’, state: ‘OH’},
{city: ‘Bath’, state: OH’}
]
},
{
name: ‘mark’, age: 33,
places_lived: [
{city: ‘Lodi’, state: ‘OH’},
{city: ‘Ada’, state: ‘OH’},
{city: ‘Akron’, state: ‘OH}
]
}
]现在假如我们需要访问people.places_lived.city的值。在Arrow中,数组值的访问看起来如下:
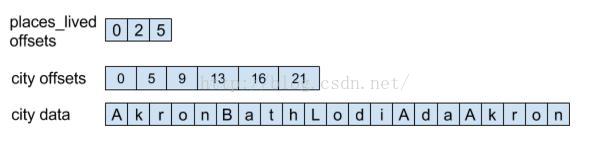
Arrow记录了places_lived字段和city字段的偏移量,我们可以通过这个偏移量得到字段的值。因为Arrow通过记录offset,使得数据的访问非常的高效。
转自:http://geek.csdn.net/news/detail/58169
Apache Arrow项目官网:http://arrow.apache.org/
Apache Arrow项目Github:https://github.com/apache/arrow
转载请注明出处:














 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









