







接着上次的文章“图的构建(邻接链表法)”,邻接链表法构建图相对来说比较简单,并且遍历起来也相对简单,但是要是动态添加图的节点和图的边,则是实在不方便,不过现在不管那么多,今天的主题是遍历。
- 有另外一种图的构建方法,叫做十字链表法,插入删除比较方便,但是相对来说比较复杂,改天闲着木事的再搞。(其实主要原因是因为三四年前写的代码,现在翻出来了,现成的,尼玛现在让我从头写那么复杂的数据结构,死的心都有了,所以还是等哪天心情好了,无聊了再写十字链表吧)
上篇:图的构建(邻接链表法)http://blog.csdn.net/sundong_d/article/details/44983671
本次接着上一篇的讲,图的遍历就是从图中的某一个顶点除法访遍图中的其余顶点,并且使每一个顶点仅被访问一次。图的遍历算法是求解图的连通性问题、拓扑排序和求解关键路径等算法的基础
深度优先遍历
假设一个图,图中的所有顶点都未曾被访问,则深度优先遍历是从图中的某一个顶点v出发,访问此顶点,然后找到与v邻接的并且未被访问的点m出发访问,然后从m的未被访问的邻接点n出发访问,再从那个点n的未被访问的邻接点出发访问,出发......访问......,循环下去,直至图中所有的和v与路径想通的顶点都被访问到;若此时图中还有顶点没有被访问,则另选图中的一个未曾被访问的顶点做起始点,重复上述过程,直到图中的所有顶点都被访问到为止。此处不太好用语言描述,不知道各位看官看明白没有,反正我没糊涂。
下面上个图(截图截人家的,自己懒的画,但是能讲明白就好,黑猫、白猫,逮到耗子就是好猫):
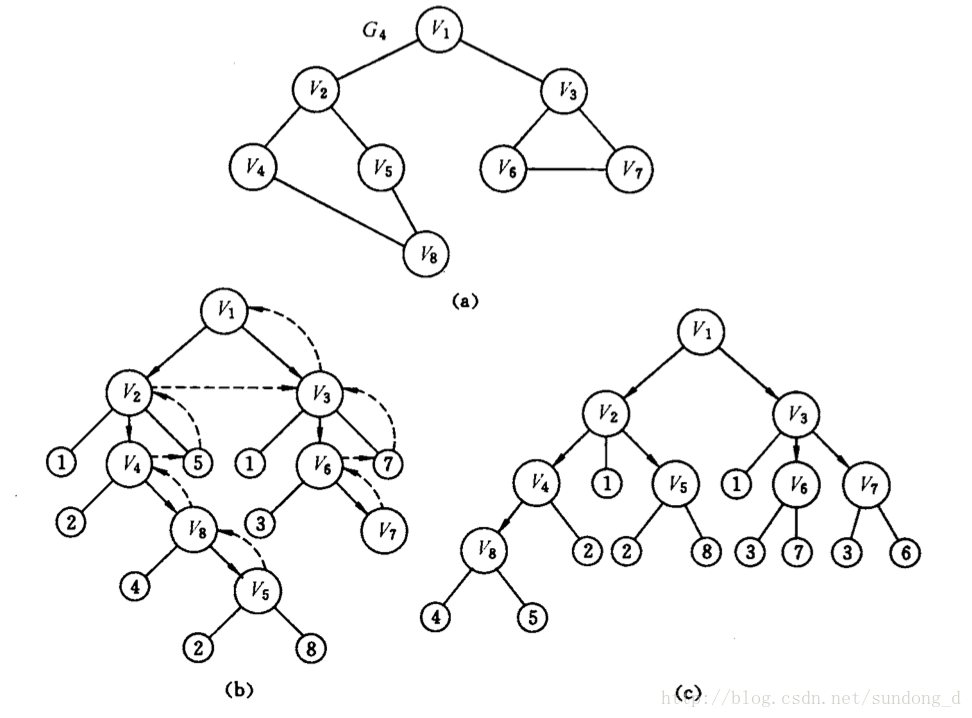 遍历过程:
以图(a)中的G4为例,深度优先遍历图的过程如图(b)所示。假设从顶点出发进行搜索,在访问了顶点v1之后,选择邻接点v2。因为v2未曾访问,则从v2出发进行搜索,以此类推,接着从v4,v8,v5出发尽心搜索。在访问了v5之后,由于v5的邻接点都被访问,则回到v8。然后......就这样一直回到v1,然后又从v1搜索v3,如此进行下去。由此的发哦的访问序列为:
v1-->v2-->v4-->v8-->v5-->v3-->v6-->v7
当然,也可以在首先访问图中任何一个点,那样就会有不通过的访问序列。
注:图(c)是广度优先遍历的示意图。
接下来是代码,C++实现,其实也可以用其他语言写,道理都是想通的,只不过实现的方式不同
遍历过程:
以图(a)中的G4为例,深度优先遍历图的过程如图(b)所示。假设从顶点出发进行搜索,在访问了顶点v1之后,选择邻接点v2。因为v2未曾访问,则从v2出发进行搜索,以此类推,接着从v4,v8,v5出发尽心搜索。在访问了v5之后,由于v5的邻接点都被访问,则回到v8。然后......就这样一直回到v1,然后又从v1搜索v3,如此进行下去。由此的发哦的访问序列为:
v1-->v2-->v4-->v8-->v5-->v3-->v6-->v7
当然,也可以在首先访问图中任何一个点,那样就会有不通过的访问序列。
注:图(c)是广度优先遍历的示意图。
接下来是代码,C++实现,其实也可以用其他语言写,道理都是想通的,只不过实现的方式不同
//----------------深度优先遍历--------------------//
//接上篇,上篇中以一个数组存储所有图中的顶点,所以如今访问时,可以用索引来标记该顶点是否被访问。
bool visited[MAX_VERTEX_NUM]; //访问标志数组,通过该数组表示顶点是否已访问,当visited[i]为false时,表示点i并未被访问。
int FirstAdjVex(ALGraph &G,int v) //找到在图G中的,与顶点G.vertices[v]相邻的未曾被访问的邻接点
{
int i;
int n=-1;
ArcNode*p;
p=G.vertices[v].firstarc;
if(p)
{
i=p->adjvex;
if(visited[i]==false)
n=i;
}
return n;
}
int NextAdjVex(ALGraph &G,int v)//功能与上面的函数类似,可以优化,合并为一个函数,但是。。。。我懒!
{
int i;
int n=-1;
ArcNode *p;
p=G.vertices[v].firstarc;
for(i=p->adjvex;i<G.vexnum,p!=NULL;)
{
i=p->adjvex;
if(visited[i]== 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2750
2750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









