







当时上云计算课的时候,搭建的Hadoop+开发IDE及插件+spark的笔记,这里是第一部分CentOS下Hadoop的伪分布的搭建。
一、环境
CentOS 6.5
Jdk 1.8
选择CentOS6.5是因为该系统相对比较稳定,很多服务也以在系统安装的时候附带安装好。但是系统安装时会自带open JDK,这里我们需要安装sun JDK。此外,我们搭建的是伪分布,所有的操作都是在root用户下进行的。
注意:在centos系统安装时,如果指定了主机名,在后面hadoop的namenode格式化时可能会出现错误。(当时出现的错误是Shutting down NameNode at 主机名/IP地址),这是因为主机名错误,需要进行配置。执行命令
gedit /etc/sysconfig/network将其中的HOSTNAME改为HOSTNAME=localhost,修改完成后重启network服务:
service network restart其实按说这里修改/etc/hosts文件应该也是可以的,在127.0.0.1的IP后面加上你原来设定的主机名。不过该方法没有测试
二、 安装JDK
1、卸载自带的open jdk
这里我们首先需要卸载系统自带的open jdk,通过下面的命令查看系统上已经安装的JDK。
rpm -qa | grep java
Eg:
java-1.6.0-openjdk-1.6.0.0-1.45.1.11.1.el6.i686
java-1.7.0-openjdk-………
……将上述出现的每个已经安装的软件卸载,执行命令:
rpm -e –nodeps java-1.6.0-openjdk-1.6.0.0-1.45.1.11.1.el6.i686
rpm -e –nodeps …注意:要想卸载全部的jdk,每条卸载命令都要执行。
2、安装sun jdk
首先,从网上下载jdk(自己找吧,这里用的是jdk1.8),下载完成应该是一个tar包,把解压之后得到的文件夹,重命名为jdk(为了后期配置路径方便)复制到/usr目录下。然后编辑系统配置文件:
gedit /etc/profile在文件的最后加上如下的语句:
#JAVA环境变量
export JAVA_HOME=/usr/jdk
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:/lib/dt.jar
export PATH=$JAVA_HOME/bin:$PATH保存退出之后,执行命令,使配置文件立即生效,否则需要重启。
source /etc/profile最后,我们可以在终端执行命令,java –version,出现如下提示,即证明成功:

如果后续过程中,出现jdk相关的问题(如卸载openjdk并安装sunjdk后,jps命令可能不能用等),应该考虑系统的默认jdk并不是现在安装的jdk,需要进行手动设置(/usr/jdk/是自己的jdk路径):
sudo update-alternatives --install /usr/bin/javac javac /usr/jdk/bin/javac 300
sudo update-alternatives --install /usr/bin/java java /usr/jdk/bin/java 300
update-alternatives --config java
update-alternatives --config javac
如果jps命令还是不能用,或提示/usr/bin没有文件,那么执行下面命令,把软链接加进去:
ln -s /usr/jdk/bin/jps /usr/bin三、 关闭防火墙
在终端执行,注意执行完毕后需要重启系统
service iptables stop
chkconfig iptables off四、 配置ssh免密码登陆
在命令行执行下列命令
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys # 加入授权使用ssh localhost试试能否直接登录,若能无密码登陆,证明成功
五、 安装Hadoop
从hadoop的官网(http://www.apache.org/dyn/closer.cgi/hadoop/common)选择合适的版本下载(这里选择的是比较稳定的2.6.0)
在/usr目录下建立一个文件夹名为BigData, hadoop-2.6.0下载完成后,像安装jdk一样,解压,把解压后的文件夹重命名为hadoop-2.6.0(重命名是为了后面配置方便,带上版本号是后期配置插件、IDE、SPARK、SCALA之类的有版本限制,不要忘记自己的版本号)复制到/usr/BigData下面。
接下来可以在/etc/profile文件中添加Hadoop的环境变量,如下:
#Hadoop环境变量
export HADOOP_HOME=/usr/BigData/hadoop-2.6.0
export PATH = $HADOOP_HOME/bin: $PATH然后开始修改配置文件(均在hadoop2.6.0/etc/hadoop下),可以右键编辑,也可以命令行gedit 文件名。如下:
1.配置core-site.xml,将文件中的 修改,注意file部分是根据自己的路径写:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/BigData/hadoop-2.6.0/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>2.配置 hdfs-site.xml,同上,修改为:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/BigData/hadoop-2.6.0/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/BigData/hadoop-2.6.0/tmp/dfs/data</value>
</property>
</configuration>注意: 这里虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),但是如果没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
3.配置yarn-site.xml,同上,修改为:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>4.配置mapred-site.xml
目录中只有一个mapred-site.xml.template文件,复制一个并重命名为mapred-site.xml,然后将文件修改为
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5.配置hadoop-env.sh,找到该文件中原本配置JAVA_HOME的语句,修改:
export JAVA_HOME=/usr/jdk #这里要使用绝对路径配置完成后,格式化namenode,在hadoop-2.6.0/bin目录下,打开终端,执行
hadoop namenode –format最后出现Exitting with status 0 表示成功,若为 Exitting with status 1 则是出错。如果出错了,可能的原因参见文档刚开始红字注意部分,其他原因再找资料解决吧。还需要注意的是,如果执行过格式化失败了,调试之后在执行需要将/tmp目录下所有有关hadoop的目录删掉,不然还是会失败。
启动所有hadoop进程,在hadoop-2.6.0/sbin目录下,执行:
start-all.sh查看各个进程是否正常启动,执行:jps。如果一切正常,将看到下列结果:
2583 DataNode
2970 ResourceManager
3461 Jps
3177 NodeManager
2361 NameNode
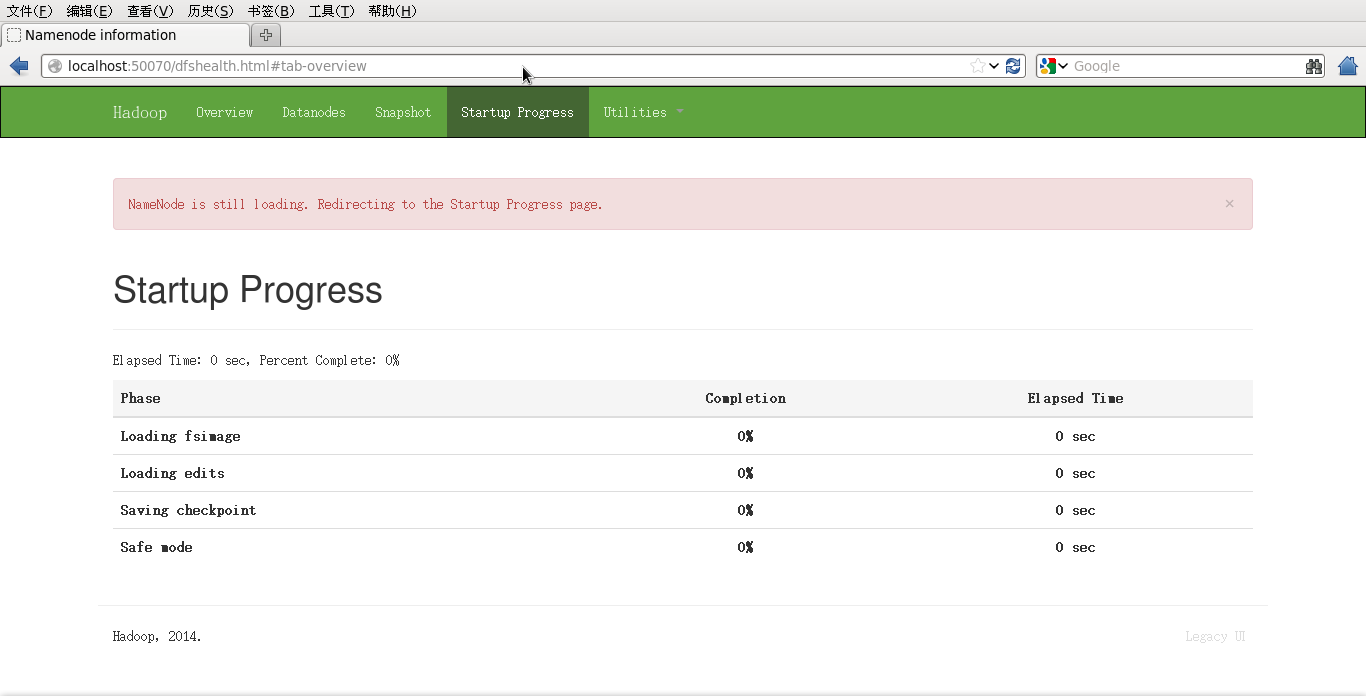
2840 SecondaryNamnode我们可以在浏览器中输入http://localhost:5007,查看相关信息如下,若能正常出现,即证明配置成功。
具体的程序运行测试会在插件篇中提到。
在JDK+Hadoop+Spark+Scala全部配置完成后,/etc/profile文件如下:
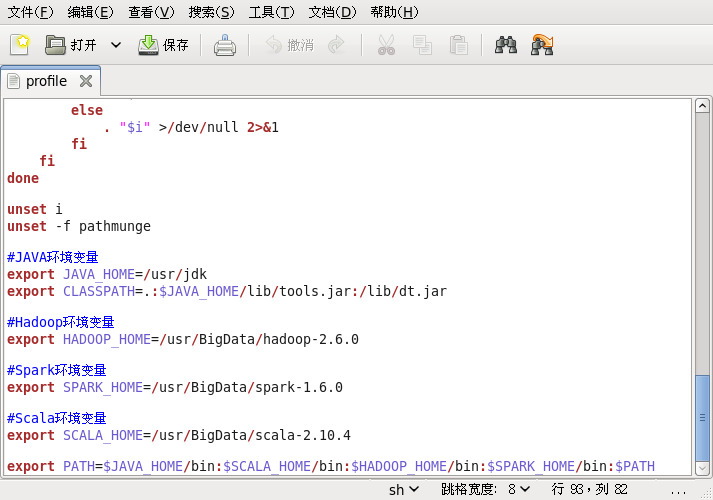
附
#JAVA环境变量
export JAVA_HOME=/usr/jdk
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:/lib/dt.jar
#Hadoop环境变量
export HADOOP_HOME=/usr/BigData/hadoop-2.6.0
#Spark环境变量
export SPARK_HOME=/usr/BigData/spark-1.6.0
#Scala环境变量
export SCALA_HOME=/usr/BigData/scala-2.10.4
export PATH=$JAVA_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATHSpark+Scala环境搭建http://blog.csdn.net/sunglee_1992/article/details/53024749
Scala与MapReduce开发的IDE插件http://blog.csdn.net/sunglee_1992/article/details/53026421















 2535
2535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









