







 本文介绍了在GPU上实现双调排序和快速排序的方法。对于小于1024个元素,使用共享内存加速的双调排序,但速度并不占优;大于1024个元素时,采用一种限制于单个block的排序方法。GPU快排在元素数量超过5000时表现出优势,递归深度过深则转用双调排序。程序重点在于分隔函数,使用warp处理元素并利用atomicAdd进行偏移地址计算。由于不是原地排序且涉及递归,需要特殊处理数组和缓冲区的交换。代码示例参考NVIDIA CUDA Samples。
本文介绍了在GPU上实现双调排序和快速排序的方法。对于小于1024个元素,使用共享内存加速的双调排序,但速度并不占优;大于1024个元素时,采用一种限制于单个block的排序方法。GPU快排在元素数量超过5000时表现出优势,递归深度过深则转用双调排序。程序重点在于分隔函数,使用warp处理元素并利用atomicAdd进行偏移地址计算。由于不是原地排序且涉及递归,需要特殊处理数组和缓冲区的交换。代码示例参考NVIDIA CUDA Samples。
单机版的双调排序可以参考 http://blog.csdn.net/sunmenggmail/article/details/42869235
还是这张图片
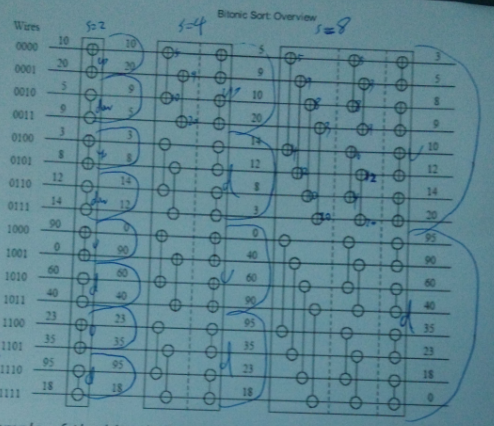
基于cuda的双调排序的思路是:
为每一个元素提供一个线程,如果大于1024个元素,还是提供1024个线程,这是因为__syncthreads只能作为block内的线程同步,而一个block最多有1024个线程,如果元素个数大于1024则每个线程可能就要负责一个以上的元素的比较
就上图而言,一个矩形代表一次多线程的比较,那么此图仅需要6次比较,就可以有右边的输出。
#include <vector>
#include <algorithm>
#include <iostream>
#include <time.h>
#include <sys/time.h>
#include <string.h>
#include <math.h>
#include <stdlib.h>
#include <stdio.h>
using namespace std;
#define CHECK_EQ1(a,b) do { \
if ((a) != (b)) { \
cout <<__FILE__<<" : "<< __LINE__<<" : check failed because "<<a<<"!="<<b<<endl;\
cout << cudaGetErrorString(a) <<endl;\
exit(1);\
}\
} while(0)
#define CUDA_CHECK(condition)\
do {\
cudaError_t error = condition;\
CHECK_EQ1(error, cudaSuccess);\
} while(0)
static __device__ __forceinline__ unsigned int __btflo(unsigned int word)
{
unsigned int ret;
asm volatile("bfind.u32 %0, %1;" : "=r"(ret) : "r"(word));
//return the index of highest non-zero bit in a word; for example, 00000110, return 2
return ret;
}
//for > 1024
__global__ void bigBinoticSort(unsigned int *arr, int len, unsigned int *buf) {
unsigned len2 = 1 << (__btflo(len-1u) + 1);//
unsigned int MAX = 0xffffffffu;
unsigned id = threadIdx.x;
if (id >= len2) return;
unsigned iter = blockDim.x;
for (unsigned i = id; i < len2; i += iter) {
if (i >= len) {
buf[i-len] = MAX;
}
}
__syncthreads();
int count = 0;
for (unsigned k = 2; k <= len2; k*=2) {
for (unsigned j = k >> 1; j > 0; j >>= 1) {
for (unsigned i = id; i < len2; i += iter) {
unsigned swapIdx = i ^ j;
if (swapIdx > i) {
unsigned myelem, other;
if (i < len) myelem = arr[i];
else myelem = buf[i-len];
if (swapIdx < len) other = arr[swapIdx];
else other = buf[swapIdx-len];
bool swap = false;
if ((i & k)==0 && myelem > other) swap = true;
if ((i & k) == k && myelem < other) swap = true;
if (swap) {
if (swapIdx < len) arr[swapIdx] = myelem;
else buf[swapIdx-len] = myelem;
if (i < len) arr[i] = other;
else buf[i-len] = other;
}
}
}
__syncthreads();
}
}
}
//for <= 1024
__global__ void binoticSort(unsigned int *arr, int len) {
__shared__ unsigned int buf[1024];
buf[threadIdx.x] = (threadIdx.x < len ? arr[threadIdx.x] : 0xffffffffu);
__syncthreads();
for (unsigned k = 2; k <= blockDim.x; k*=2) {//buid k elements ascend or descend
for (unsigned j = k >> 1; j > 0; j >>= 1) {//merge longer binotic into shorter binotic
unsigned swapIdx = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8746
8746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









