






无论你想建立自己的论坛,在你的网站上从一个邮件列表发布消息,或编写自己的cms:你将会遇到一种情况:将分层数据(层级结构)存储在数据库中。除非你使用一个类似xml的数据库,通用的关系型数据库是很难做到这一点。关系型数据库中的表不分层;他们只是一个简单列表。你必须找到一个方法来把层次结构数据转换为一个简单文件数据。
存储树是一种常见的问题,可以有多个解决方案来实现。有两种主要方法:邻接表模型和修改后的树前序遍历的算法。
在本文中,我们将探讨这两种方法来存储层级结构数据。我将使用从一个虚构的在线食品商店虚拟的这棵树为例。这个食品商店通过类别、颜色以及种类来来组织它的食品。
这颗树如下:
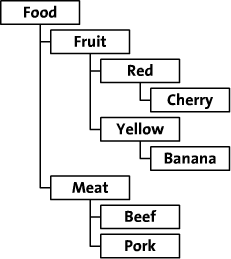
这篇文章包含一些代码示例展示了如何保存和检索数据。原文是使用的PHP,在这我将使用java来演示它的代码展示。
[一] 邻接列表模型
我们最先尝试或者最优雅的方式我们称为“邻接表模式”或者我们称它为“递归方法”。
这是一种优雅的方法,因为你只需要一个简单的函数就可以遍历树。在我们的食品商店的例子中,邻接表的表可以这样表示:
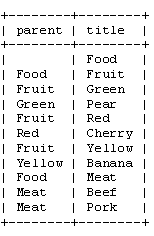
如您所见,在邻接表的方法,你只保存每个节点的父节点。我们可以从表上清楚的看到,“Pear”是“Green”的一个孩子,同时“Green”又是'Fruit'的孩子。
根节点“Food”没有父节点。为简单起见,我使用了“标题”值来确定每个节点。当然,在一个真正的数据库,可以使用id来标示。
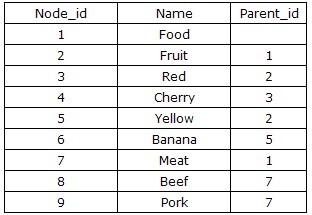
Give Me the Tree
既然我们已经在数据库中插入我们的树,是时候写一个显示功能。这个函数将不得不从根节点(没有父节点)开始,应该显示所有该节点的孩子。对于这些孩子节点来说,这个函数应该检索和显示这些孩子节点的所有子节点。然后在显示这些孩子节点的子节点,递归的进行。
public void DisplayTree(int parentId,int level){
String sql = "select NodeId,NodeName,ParentId from Tree where parentid="+ parentId;
conn = sqlManager.GetConn();
try {
statement = conn.createStatement();
ResultSet rs = statement.executeQuery(sql);
while(rs.next()){
for(int i = 0;i < level*2;i++){
System.out.print("-");
}
System.out.println(rs.getString("NodeName"));
DisplayTree(rs.getInt("NodeId"),level+1);
}
} catch (SQLException e) {
e.printStackTrace();
}
}注:sqlManager类是数据库操作类。
数据库存储的数据:
DisplayTree(0,0)
结果:

如果你只是想看到一个子树,你可以告诉函数这个开始节点的Id即可。
例如,显示“Fruit”子树,运行DisplayTree(2,0);
The Path to a Node
有时候我们需要知道某个节点所在的路径。举例来说,“Cherry”所在的路径为Food > Fruit > Red > Cherry。在这里,我们可以从Cherry开始查起,然后递归查询查询节点前的节点,直到某节点的父节点ID为0。
//获取某个节点所在路径
public ArrayList<String> GetPath(int nodeId){
String sql = "select ParentId,NodeName from Tree where NodeId = "+nodeId;
ArrayList<String> path = new ArrayList<String>();
try {
conn = sqlManager.GetConn();
statement = conn.createStatement();
ResultSet rs = statement.executeQuery(sql);
rs.next();
int parentId = rs.getInt("ParentId");
String nodeName = rs.getString("NodeName");
if(parentId != 0){
path.addAll(GetPath(parentId));
}
path.add(nodeName);
} catch (SQLException e) {
e.printStackTrace();
}
return path;
}ArrayList<String> path = main.GetPath(9);
int index = 0;
for (String node : path) {
if(index != 0){
System.out.print("->");
}
System.out.print(node);
index++;
}
优缺点
我们可以看到,用邻接表模型确实是个不错的方法。它简单易懂,而且实现的代码写起来也很容易。那么,缺点是什么呢?那就是,在大多数语言中,邻接表模型执行起来效率低下和缓慢。这主要是由于递归引起的,我们查询树中的每个节点的时候都需要进行依次数据库查询。因为每个查询需要一些时间,这使得函数非常缓慢的在处理大树时。第二个原因是在你可能使用的编程语言这个方法不是那么快,。对于一门程序语言来说,除了Lisp这种,大多数不是为了递归而设计。当一个节点深度为4时,它得同时生成4个函数实例,它们都需要花费时间、占用一定的内存空间。所以,邻接表模型效率的低下可想而知。
[二] 树前序遍历的算法变形
那么就让我们来看另外一种存储树形结构的方法。如之前所讲,我们希望能够减少查询的数量,最好是只做到查询一次数据库。
现在我们把树“横”着放。如下图所示,我们首先从根节点(“Food”)开始,先在它左侧标记“1”,然后我们到“Fruit”,左侧标记“2”,接着按照前序遍历的顺序遍历完树,依次在每个节点的左右侧标记数字。最后一个数字写在“Food”节点右边的。在这张图片里,你可以看到用数字标记的整个树和几个箭头指示编号顺序。
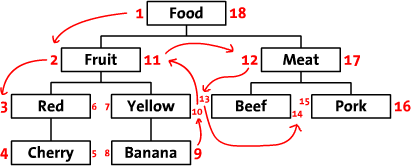
我们叫这些数字为Left和Right(例如“Food”的Left值是1,Right值是18)。正如你所看到的,这些数字表示每个节点之间的关系。
比如,“Red”节点左边的数为3、右边的数为6,它是Food(1-18)的后代。同样的,我们可以注意到,左数大于2、右数小于11的节点都是“Fruit”的子孙。现在,所有的节点将以左数-右数的方式存储,这种通过遍历一个树、然后给每一个节点标注左数、右数的方式称为修改过的前序遍历算法。
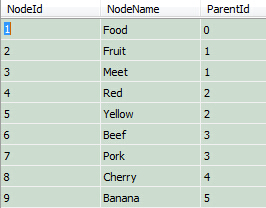
在我们继续之前,让我们来看看在我们的表的这些值:
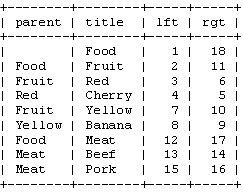
注意,“Left”和“Right”在SQL中有特殊的意义。因此,我们必须使用“lft”和“rgt”标识列。还要注意,我们并不真的需要“parent”列了。我们现在有lft和rgt值存储树结构。
Retrieve the Tree
SELECT * FROM FoodTree WHERE Lft BETWEEN 2 AND 11;注:FoodTree是存储数据的表
返回:
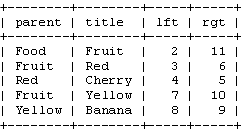
整个树只需要一次查询。
显示这棵树就像我们做递归函数,我们将不得不ORDER BY子句添加到查询语句中。如果你从你的表添加和删除行,你的表可能不会以正确的顺序存储。我们应该按左值进行排序。
SELECT * FROM FoodTree WHERE Lft BETWEEN 2 AND 11 ORDER BY Lft ASC;现在唯一的问题是缩进问题。
显示树结构,孩子应该缩进略高于他们的父母。这里,我们可以维护一个只保存右数的栈。每次你从一个节点的孩子节点开始,你将该节点的Rgt值添加到堆栈中。我们知道该节点所有的孩子的Rgt值小于父节点的Rgt值,所以通过比较当前节点的Rgt值和堆栈中最后一个节点的Rgt值。当当前节点的Rgt值大于栈顶元素的值(说明栈顶元素的子树都以遍历完毕),这个时候弹出栈顶值。再循环检查栈顶值,直到栈顶值小于当前查询节点的Rgt值。这个时候只要检查栈中元素,有多少个元素说明当前查询节点有多少个祖先节点代码如下:
public void DisplayTree2(String nodeName) {
String sql = "select Lft,Rgt from FoodTree where NodeName ='" + nodeName+"'";
conn = sqlManager.GetConn();
Stack<Integer> RgtStack = new Stack<Integer>();
try {
statement = conn.createStatement();
ResultSet rs = statement.executeQuery(sql);
rs.next();
int lft = rs.getInt("Lft");
int rgt = rs.getInt("Rgt");
sql = "select NodeName,Lft,Rgt from FoodTree where Lft between "+lft+" and "+rgt +" order by Lft asc";
statement = conn.createStatement();
ResultSet rs2 = statement.executeQuery(sql);
while (rs2.next()) {
int rightValue = rs2.getInt("Rgt");
if(RgtStack.size() > 0){
//栈顶元素
int cur = RgtStack.peek();
while(cur < rightValue){
RgtStack.pop();
if(RgtStack.size() > 0){
cur = RgtStack.peek();
}
else{
break;
}
}
}
for(int i = 0;i < RgtStack.size()*2;i++){
System.out.print("-");
}
System.out.println(rs2.getString("NodeName"));
RgtStack.push(rightValue);
}
} catch (SQLException e) {
e.printStackTrace();
}
}运行代码,打印结果和之前邻接表模型打印的结果一样。但是新方法更快,原因就是:没有递归,且一共只使用两次查询。
The Path to a Node
使用这种新算法,我们还将必须找到一种新的方式去找到一个特定节点的路径。这条路径,我们将需要一个列表来保存所有祖先节点。
例如,当你看4 - 5“Cherry”节点,您将看到所有的祖先节点都是左值小于4,右值大于5。得到所有的祖先,我们可以使用这个查询:
SELECT NodeName,Lft,Rgt FROM FoodTree WHERE Lft < 4 AND Rgt > 5 ORDER BY Lft ASC;+-------+
| title |
+-------+
| Food |
| Fruit |
| Red |
+-------+How Many Descendants
如果你给我一个节点的左和右值,我可以利用数学公式告诉你有多少子节点。
descendants = (right - left - 1) / 2
这个简单的公式,我可以告诉你,2 - 11“Fruit”节点有4个子节点,8 - 9“Banana”节点没有子节点。
Automating the Tree Traversal
这儿的自动生成表指的是:如何把一个表从邻接表模型转换成修改过的前序遍历模型。我们在开始的临界表上增加"lft“和”rgt“字段。执行以下代码,完成转换:
//邻接表模型转换为修改后前序遍历遍历算法模型
public int RebuildTree(int parentId,int lft){
int rgt = lft + 1;
String sql = "select NodeId,NodeName from AdjTree where ParentId=" + parentId;
conn = sqlManager.GetConn();
try {
statement = conn.createStatement();
ResultSet rs = statement.executeQuery(sql);
while(rs.next()){
rgt = RebuildTree(rs.getInt("NodeId"), rgt);
}
sql = "update AdjTree set Lft = "+lft+", Rgt = "+rgt + " where NodeId = "+parentId;
statement = conn.createStatement();
statement.executeUpdate(sql);
return rgt + 1;
} catch (SQLException e) {
e.printStackTrace();
return 0;
}
}结果:
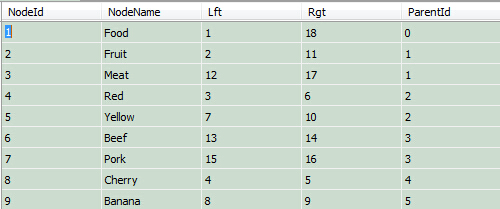
我们所写的运行函数是一个递归函数。对于某一节点,如果其没有子孙节点,那么他的右数值等于左数值+1;如果有那么返回其子树右数值+1。这个函数稍微有点复杂,不过梳理通了以后就不难理解。
这个函数将会从根节点开始遍历整个树。运行了可以发现和我们之前手动所建的表一样。这里有个快速检查的方法:那就是检查根节点的右数值,如果它等于节点总数的2倍,那就是正确的。
Adding a Node
我们如何将一个节点添加到树中?这里有两种方法:(1)你可以在你的表中保存父节点字段‘ParentId’并重新运行RebuildTree()函数。这是一个简单但是效率不高的方法;
你可以使用邻接表的方法进行更新和修改后的前序遍历树算法进行检索。如果你想添加一个新节点,您就将其添加到表并设置父节点。然后,只需重新运行RebuildTree()函数就可以了。对一个大树来说这是一个很容易,但不是非常高效方法。
(2)第二种方法为添加、删除节点时更新新插入节点右边所有节点的左值和右值。让我们来看一个例子。我们想添加“Strawberry“到”Red“节点下,那么“Red”节点的右数就得从6到8,而“Yellow”就得从7-10变成9-12,以此类推。更新Red节点就意味着大于5的左数和右数都要增加2。
UPDATE FoodTree SET Rgt = Rgt+2 WHERE Rgt > 5;
UPDATE FoodTree SET Lft = Lft+2 WHERE Lft > 5;现在我们可以添加一个新的节点“Strawberry”来填补新腾出的空间。这个节点左值为6和右值为7。
INSERT INTO FoodTree (Lft,Rgt,NodeName)values(6,7,'Strawberry');如果我们运行DisplayTree2()函数,我们将看到新的“Strawberry”节点已经成功插入到树:
Food
--Fruit
----Red
------Cherry
------Strawberry
----Yellow
------Banana
--Meet
----Beef
----Pork
Disadvantages
首先,修改过的前序遍历算法似乎更难理解。但是它有着邻接表模型无法比拟的速度优势,虽然,在增或着删数据的时候步骤多了些,但是,查询的时候只需要一条SQL语句。不过,这里我要提醒,当使用前序遍历算法存储树的时候,要注意临界区问题,就是在增或者删的时候,不要出现其他的数据库操作。
注:SqlManager类
package com.sql;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class SqlManager {
private String SqlConectionString = "com.microsoft.sqlserver.jdbc.SQLServerDriver";
private String ip = "localhost";
private String databaseName = "SJF";
private String user = "sa";
private String password = "123";
private String url = null;
private Connection conn = null;
public SqlManager(){
//加载驱动
try {
Class.forName(SqlConectionString);
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.out.println("加载数据库驱动失败:\n"+e.getMessage());
}
url = "jdbc:sqlserver://" + ip + ":1433;DatabaseName="+databaseName+";";
}
//+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
public Connection GetConn(){
try {
conn = DriverManager.getConnection(url, user, password);
} catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
//+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
//关闭
public void CloseConn(){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
//+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
}














 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









