







作者:Simon Jégou Michal Drozdzal David Vazquez ..
Abstract
典型的语义分割架构由(a)一条下采样路径,负责提取粗的语义特征,再加一个(b)一条上采样路径,负责回复图像分辨率,(c)和一个可选的后处理模块(比如,条件随机场)来精调模型预测。
最近一个新的架构DenseNets,主意来源于:如果每层直接连接其他层,就像前馈机制一样,网络会变得更精确和更好训练。
1. Introduction
全卷积网络(FCN)来源于CNN的自然扩展,为了处理每个像素的预测问题,比如语义图像分割。为了补偿由于引入池化的引起的分辨率损失,FCN在上采样和下采样之间引入跳跃连接。跳跃连接帮助上采样路径恢从下采样层复有细密纹理的信息。
这里还用到了残差网络的思想。残差网络通过引入残差模块来训练非常深的网络。残差模块将输入的非线性变换和输入的本征映射(identity mapping,通过短路经)相加。残差网络在FCN中引入额外路径(短路径),增加了分割网络内部的连接数量,这个短路经不仅提高分割精确度,还帮助网络优化过程,促进更快的收敛。
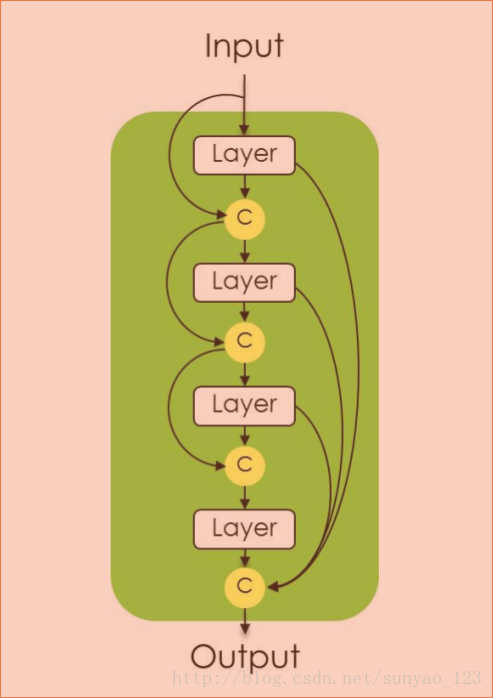
enseNet, 一个新的CNN架构,由dense blocks和池化操作组成,每个dense blocks是先前特征图的迭代连接,这个架构可以被看成ResNets的演化,不断对先前产生的特征图的叠加。然而这个小的变体却有一些有趣的应用:(1)参数利用率,DenseNets的参数利用率更高(2)隐晦的深度监督,DenseNets通过架构里边对所有特征图的短路经来进行深度监督(和深度监督网络相似)(3)特征重利用,所有的层可以很容易连接到他们的先前层,使得它能够重复利用先前产生的特征图信息。DenseNets架构使得它非常适合语义分割,因为它自然的引入跳跃连接和多级监督。
本论文将DenseNets扩展为FCNs,再加上上采样路径来恢复输入分辨率。单纯的增加一个上采样路径将会导致在softmax层前产生难以计算数量的有高分辨率的特征图。这是因为我们会用大量的滤波器(来自所有下边的层)乘以高分辨率特征图,导致了大量的计算和许多参数。为了缓和这种影响,我们仅仅上采样由先前的dense block产生的特征图。这样做使得在上采样路径的每一个分辨率有一些dense blocks独立于池化层的个数。更重要的是,上采样dense block结合了包含同样分辨率的另一个dense blocks的信息。高分辨率信息通过在下采样和上采样直接的标准跳跃连接来传递。
2. Related Work
关于语义分割的工作主要有3方面:(1)提高上采样路径,增加FCN内部的连接;(2)引入能解释更广泛上下文理解的模型(3)使得FCN架构具有产生结构化输出的能力。
首先,不同架构被提出来处理FCN上采样路径分辨率恢复问题:从简单的双线性插值到更加复杂的操作比如unpooling或者transposed convolutions。降采样层和上采样层的跳跃连接也被采用允许更好的信息恢复。文献[8]对语义分割中本征映射和跳跃连接的结合进行了非常透彻的分析。
第二,一些方法在语义分割网络中引入大的上下文背景。
第三,条件随机场一直以来很受欢迎,用来增强分割输出的结果一致性。
最后,值得一提的是最近结果最好的语义分割FCN架构经常依靠预训练模型来提高他们的分割结果。
3. Fully Convolutional DenseNets
残差网络的一个作用是:使得梯度直接流向先前层。
DenseNets:将前几层的输出结合起来(加),然后通过BN+ReLU+convolution+dropout。这种连接模式对特征进行非常强的再利用,使得架构里的所有层接受直接的监督信号。
transition down用来减少特征图的空间维度,它由一个1×1的卷积(保护了特征图的个数)加2×2的池化。
在下采样路径上,特征个数的线性增长,通过在池化操作后每个特征图空间分辨率的下降来补偿。为了恢复输入空间分辨率,上采样路径有卷积,上采样,(或者反卷积,transposed convolutions , unpooling操作)和跳跃连接。
Transition up模块包括transposed convolution(上采样先前的特征图)。然后关联跳跃连接层,形成新的dense block的输入。因为上采样路径增加了特征图的空间分辨率,特征个数的线性增长将会非常耗内存, 特别是在softmax层前的全分辨率特征。
为了解决这个限制,在上采样层,dense block的输入不和它的输出关联。因此,transposed convolution仅仅应用于由最近的dense block产生的特征图,并不是到此所有关联过来的特征图。最近的dense block将所有先前的同一分辨率的dense block获得的信息相加。要注意的是,先前dense block产生的一些信息由于pool操作在transition down中损失了。然而,这些信息可以在网络的下采样路径中得到,可以通过跳跃连接传递。因此上采样路径中的dense block使用所有的能得到的给定分辨率的特征图来计算。
因此我们的上采样路径方法允许我们来建立更深的FC-DenseNets而不会产生特征图爆炸。运用这种上采样路径的一个可行办法是,进行连续的transposed convolutions并且通过跳跃连接来补偿(在下采样路径通过unet或者FCN-like方式)。
模型如下图:
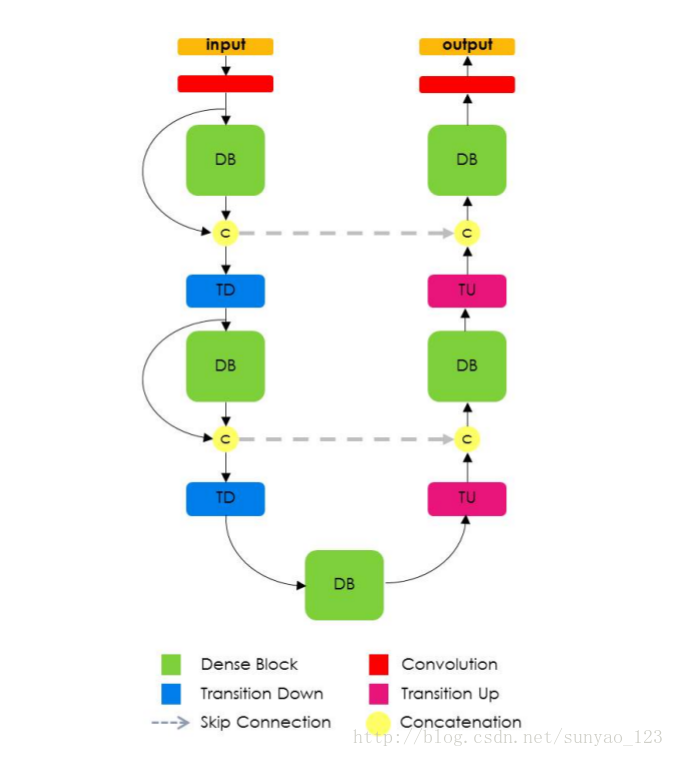
dense blocks模块:
3.3. Semantic Segmentation Architecture

如图tabel1:Dense block:BN+ReLU+3 × 3 same convolution (no resolution loss)+dropout(p=0.2)。增长率k=16。只卷积了一次。所以Transition up才会用反卷积。
Transition down:BN+ReLU+1 × 1 convolution+dropout(p=0.2)+non-overlapping max pooling(2×2)。
Transition up:3 × 3 transposed convolution(stride=2)。

如上tabel2:这个架构从103卷积层建立:input(m=3),downsampling path(38),bottleneck(15),upsampling path(38)。m为核个数。
我们使用5个TD(每个包含一个额外的卷积),5个TU(每个包含一个反卷积)。网络的最后一层是一个1 × 1 convolution+softmax non-linearity给每个像素产生每类的概率。
值得一提的是,提出的上采样路径合理的缓解了DenseNet的特征图爆炸,产生合理的pre-softmax feature map有256个。
最后模型通过减少每个像素的交叉熵损失来训练。
4. Experiments
论文使用检测评价函数(IoU)和全局精确度(数据集上每个像素精确度)提交结果。
意思就是:对于每一类,IoU=label与预测的交集/label与预测的并集。
4.1. Architecture and training details
使用HeUniform初始化,优化器为RMSprop(lr=0.001, exponential decay=0.995 each epoch)。所有的模型在通过随机裁剪和垂直反转增强过的数据上训练。所有的实验,我们在全图上和用0.0001的学习率进行微调。我们使用验证集提前结束训练和微调。监测平均IoU或者平均精确度。
通过0.0001的权重下降率和0.2的dropout调整网络。对于BN,在训练,验证,测试时使用最近的batch statistics(数据归一化,减去均值除以标准差)。














 7267
7267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









