







作者:R. Guerrero ∗1 , C. Qin ∗1 , O. Oktay 1
这篇主要介绍网络部分,下一篇介绍评估方法
Abstract
最近,一些方法被提出来自动分割WMH区域。这些方法大多分割MRI图像的WHM,但是不能区分WMH和中风。其他能够区分脑部MRI图像不同病理的方法,不能同时分割大脑WMH和中风。这篇论文提出一种卷积神经网络,能过分割高信号,并且能够区分WMH和中风区域。特别的是,我们的目的是区分由于中风损伤造成(由于皮层大的或小的皮质下梗死造成)的不同的WMH病理学。有我们所知,这种区分任务是第一次被明确提出来。提出的全卷积神经网络架构叫做uResNet,由分析路径(逐渐学习低维高维特征),在加一个综合路径(逐渐结合并且上采样高维低维特征,最后形成类似然语义风割)。
1 Introduction
1.1 Clinical motivation
其中最广泛应用之一的评价WMH负担和敏感度的标准是Fazekas可视化评定率。在本篇论文中,一个放射科医生将一个MR图像中深度白质和peri-ventricular区域进行可视化等级化,依据病变的大小,位置,交汇,分为4种可能的类别。等级为0~6.WMH在大小,形状,位置上变化不定,在与其他临床参数相关时,Fazekas量表的类别本质在研究它们的变化时就收到限制。WMH的体积已经被证明与症状的严重程度,残疾进程,临床表现相关。
1.2 Related work
根据数据集的标注程度,以下介绍3类方法:非监督,半监督,监督分割方法。
非监督分割 一些工作关注于一个事实:WMH在FLAIR MR图像观察更明显,但是在T1加权的MR图像上很难区分。这些方法中的一些依赖于根据观察到的T1加权MR图像使用随机森林,有生成能力的混合模型,支持向量回归,或者卷积神经网络等,生成合成的FLAIR图像。使用生成的和真实的FLAIR来检测异常。Weiss等人提出,利用免费的大脑T1加权MR图像,使用字典学习来学习稀疏表达。然后,它们将这些字典应用于稀疏重建大脑MR图像,这次额图像包括病理,并且使用重建误差来确定异常值,这些异常值被定义为病理区域。这些方法的一个重要的不足就是,它们实际上是非正常检测算法,不是WMH分割算法,因此,原则上来说,它们检测任何的病理,不管是不是与WMH相关的病理。Schmidt等人提出里一种病变增长算法,这个算法建造一个保守的病变深度映射,预先设置一个阈值k,然后再加沿着体积增长 的initial map,在FLAIR图像中表现为病理。本质上,这些方法在检测轻微的WMH还是有些困难。
Semi-supervised segmentation 文献中提出的一些半自动分割方法依赖于区域增长技术,这个技术要求手术者放置初始种子点。Kawata等人使用从初始确定的WMH候选人中提取的图像特征,提出一个区域增长方法,用SVM自适应选择分割。Qin等人提出优化基于最大化目标函数的核方法,最大化内外节点平均的margin,同时利用有些可得的有标记数据。Itti等人提出一种区域增长算法,这个算法通过传播种子点到相邻像素值超过优化阈值的体素,来提取WMH。过程循环直到收敛为止,比如,所有的在阈值之上被连接到初始种子点的体素被标注。虽然在理论上有趣并且有启发性,但将有用的知识从未标记的数据转移到部分标记的比赛上,仍然是一个挑战,也是一个研究的开放领域。因此,即使这些方法要求一些精确的输入,半监督WMH分割方法仍然没有监督方法好,即使是监督方法使用适中数量的数据。
Supervised segmentation 病变区预测算法在SPM’s LST toolbox中应用,这种算法还没有发表,是一种逻辑回归模型,53个MS病人的label被作为响应值。作为这个模型的相关变量,病变的信念映射与LGA相似,被用来关联空间关联,这种空间关联考虑在损伤概率体素的指定变化。Ithapu等人提出自适应SVM和随机森林,使用由纹理滤波器组产生的纹理特征,来进行WMH分割任务。讨论的大多数这些方法的一个重要缺点就是不能处理多类分割。Kamnitsas等人提出使用多通道多分辨率3D CNN 来进行基于块的分类器,每个分辨率使用不同的路径,然后在网络深处merge,最后给出任何输入块的中间体素的类别概率。Ghafoorian等人提出一个多分辨率网络,输入是FLAIR和T1图像,来分割WMH,对不同分辨率使用不同路径。Both Kamnitsas等人和Ghafoorian等人使用多分辨率输入增加感受野。然而,大的下采样块有一个缺点,有用的信息在任何预处理之前就被丢掉了。在论文22中,这样做是为了节约内从,能够在高分辨率有更多的非线性。通常来说,CNN第一层的滤波器是一些基本的特征检测器,并且很好解释,比如是直线,或者曲线。因此,不同的路径捕获了多余的信息。3D卷积直觉上说明3D体图像的处理是有道理的。然而,FLAIR图像通常是通过2D图像来获取的,而且厚度很大,然后堆叠为3D体。而人为的标注是在2D上一张一张来的,因此,3D卷积对于FLAIR MR图像分割来说是缺少直观性。
1.3 Contributions
关于U-net,作者是这么分析的:这个架构由一条分析路径(目的是捕获纹理)和一条对称的综合推理路径(逐步结合分析和推理特征),最后进行精确的定位。这种架构由高分辨率的图像块训练,能够通过单条路径提取高维和的低维的特征,因此避免了滤波器冗余。但本文做了修改:使用惨差模块代替卷积,在U-net中使用的级联架构使用加和而不是拼接,来减小模型复杂度。本文的一个重要的工作是处理用来训练的数据采集。由于在WMH分割中的大量类别不平衡问题,对数据采集应该非常小心,这个问题由于对精确分割的影响而受到关注。作者使用patch而不是整张图片训练来缓解类别不平衡问题,而且,这些patch一定包含WMH,并且随机移动中心位置(为了使WMH可以出现在patch中的任何位置,而并不是只在中间)。而且,作者还实验了多通道输入,来评估增加T1MR图片和白质或者脑积液概率图的增加的优点。网络被称为uResNet,如图:
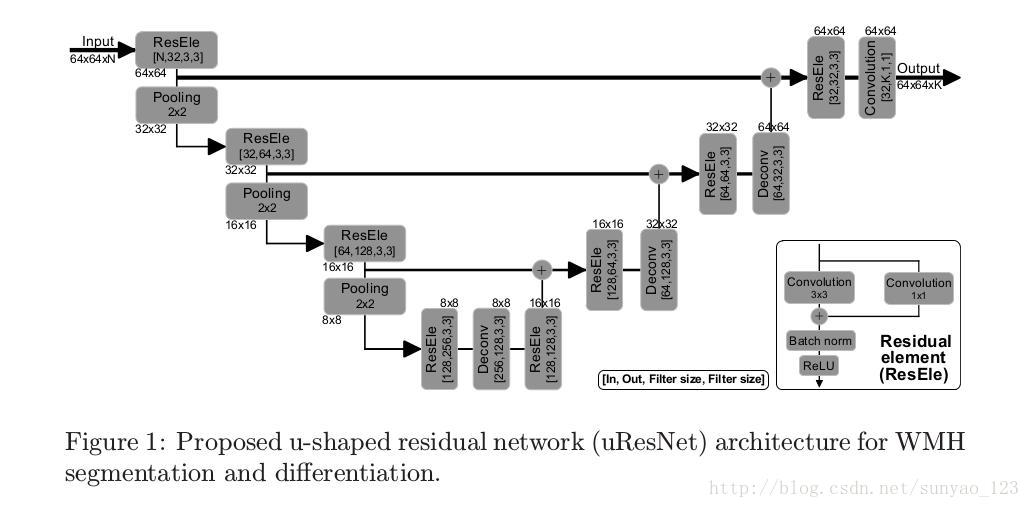
2 Methods
2.1 Network architecture
定义一个网络架构要求仔细考虑任务。要考虑的一个重要因素是网络的感受野或者接收野,能力或者复杂度。这个架构遵循Simonyan and Zisserman的建议,使用3×3的小核。这使得在同样接收野下最少参数的情况下,非线性能力的增长。
这是一个FCN网络,所以,虽然使用patch训练,但是可以直接输入整张图片来预测,而不用改变架构。网路有12层,1M的可训练参数:8个惨差模块,3个反卷积层,一个最后的卷积层将特征图转变为label大小。然后最后一层再通过像素级的softmax函数,产生预测类概率映射:
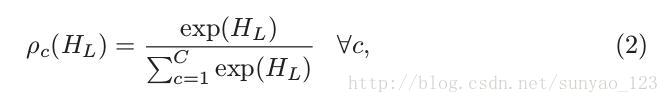
小c代表类,大C代表总类的个数。
这实际上产生图像每一个像素的一个类似然估计,输出和一个loss function结合,通过反向传播算法更新。
2.2 Loss function and class imbalance
因为像素级别的语义分割会有类别不平衡问题,所以可以定义一个loss function,考虑到类别不平衡问题。下边将详细讲述不考虑类别不平衡的loss function,和直接或间接考虑类别不平衡的loss function。
1)
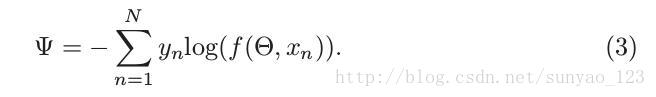
2)
这是传统的交叉熵损失函数,没有考虑类别不平衡问题,当类别不平衡时可能会学习到带偏见的预测。一种简单的解决类别不平衡问题就是调整交叉熵损失函数,通过给不同的类别不同权重,如下:
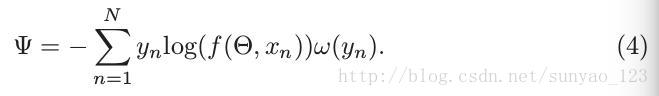
ω(y n )是类别yn的权重。
3)
还可以设置一个阈值,如果预测结果大于这个阈值,我们就忽略loss贡献,方法就是在求loss时,将大于阈值的用1替换,这样其loss就为0.
Dubbed online bootstrapped categorical cross-entropy公式如下:

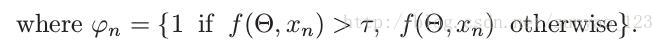
dice系数在二值空间定义,计算相同类的重合度。比较二值分割label的一个流行的评价标准。由此提出的一个伪dice系数损失函数为:
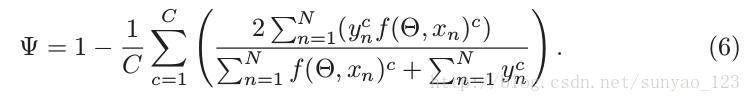
预测的二值label由连续的softmax输出代替,然后将所有的labels C进行平均。
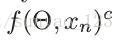
代表进过softmax对类别C的预测。将每类的dice 系数平均有一个额外的影响,正则化每类的损失贡献。
2.3 Data sampling and class imbalance
一般来说,在病理分割时,正常组织比病变组织大很多,这是造成类别不平横问题的原因。所以这就是为什么采用patch进行训练的原因。缓解类别不平衡问题。选取patch的方法有:一半的数据是以正常组织为中心,一半的数据以WMH组织为中心。但当patch较大时,这种办法不太能够缓解类别不平衡问题,因为单个的patch里边也会涉及高度类别不平衡(像素级别)。另一种方法就是,只取以病变区为中心的patch,这种办法实际上是将健康组织减少了90% .然而这会导致位置偏见,即病变区总是被认为是在patch中央。相反的是,当定义好要从哪儿提取随机WMH训练patch后,一半的数据通过随机移动大于patch size的一半∆ x,y,然后提取patch,来增强数据。
图二说明这一方法。需要说明的一点是,这里提到的位置敏感在自然图像训练中不是一个问题,因为不同的类可能出现在场景中任何位置(脸可以在任何位置),或者类别位置给出了有意义的描述(天空在场景上边)。这个问题只在从训练数据中有规则的采样patch时才会出现,比如本文问的问题。
3 Data
所有的图片在轴向被重新插值到1mm,剩下一个方向保持不变(切片厚度)。为了得到一致的像素值,所有的MR数据归一化为0均值1方差(包括背景)。经过0均值后,低于3个标准差的像素值被clipped,为了保证所有图片背景像素值的一致性。
4 Experiments and results
数据组成:20%在所有标记为WMH可能的区域随机选取,80%在标记为中风的区域提取。所有167图像都包含WMH区域,其中59张还包含中风损伤区。使用2交叉验证,每个fold包含只有WMH区的一半图像和一半既有WMH又有中分的图片,每个fold都表现了数据的分布。
有两中评估方法。主要的是,与其他发表的最好的方法和临床分析比较。与其他方法比较包括,分割图像label重叠区域的评估,使用dice系数,和自动分割区与专家划定区域的区别分析。临床分析包括一些临床变量相关性分析(主要是Fazekas and MMSE),通用线性模型(GLM)的已知的风险因子相关性分析。
4.1 Model training
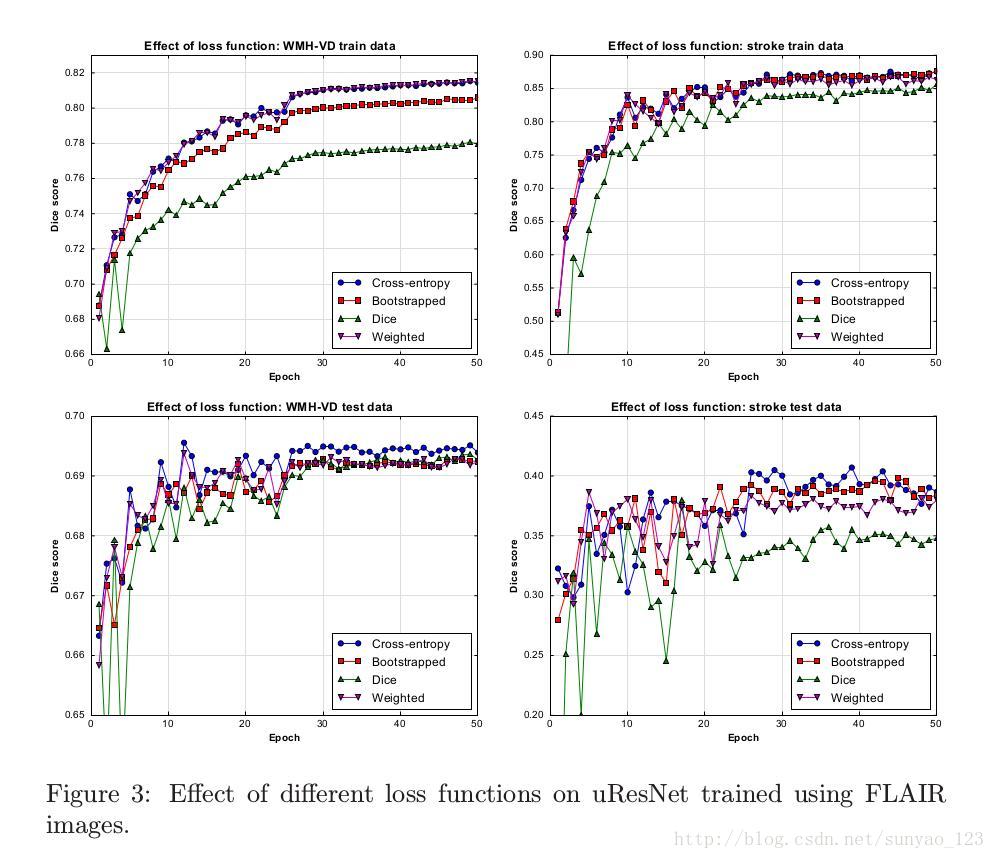
训练CNN的一个重要因素就是,定义loss function,因为loss function会指导学习过程。图三是使用不同的loss function训练后使用dice系数得分来评估。横轴表示训练周期,纵坐标表示dice得分。第一行是训练数据的dice得分,第二行是测试的dice得分。当然这里的dice得分是=是基于整张图而不是按照提取的patch来计算的。
从图三看出,加权的和传统的交叉熵表现最好,几乎没有区别。但是,加权的交叉熵还额外需要相关的权重参数。因此在本论文这种情况下,传统的交叉熵是最好选择。一个非常重要的需要注意的是:在训练阶段,不管是loss function还是评估标准,使用dice系数,模型的表现都比较差。因此,我们推断,对于这个特定的问题,我们优化的解决空间对于dice评估来说比对与其他更复杂,所以找全局最优解就更麻烦一点。
WMH在FLAIR MR图像中表现的最好,T1 加权MR图像中有补充信息。文章还探索了给提出的分割框架增加了额外的多模型信息贡献。额外的输入通道包括T1加权图像,白质概率图和脑脊髓束图集。分割精确度还使用dice得分。从图四看出,大该在30个epochs时收敛。
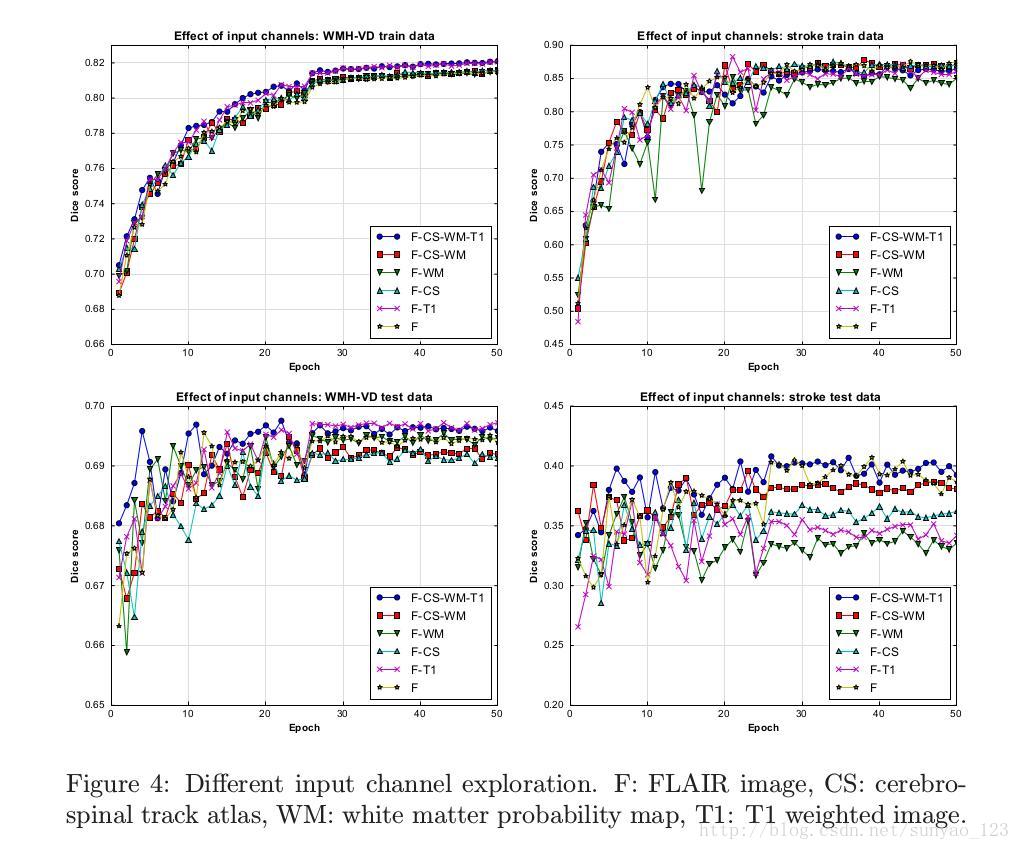
从图四看出,使用四个通道输入,和一个通道输入没有太大的区别。从3和图四看出,在训练和测试中,中风分割的dice得分比WMH的dice得分要震荡一些。作者分析是因为中分数据少一些,随着每个周期提供关联到这类的更加随机的梯度,因此对变化更加敏感一些。更重要的是,中风高的训练精确度,和低的测试精确度是由于类别不平衡造成的,因为它们潜在的指向过拟合问题。














 2669
2669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









