






前面一篇博文介绍的Ranking SVM是把LTR问题转化为二值分类问题,而RankNet算法是从另外一个角度来解决,那就是概率的角度。
RankNet方法就是使用交叉熵作为损失函数,学习出一些模型(例如神经网络、决策树等)来计算每个pair的排序得分,学习模型的过程可以使用梯度下降法。
首先,我们要明确RankNet方法的目的就是要学习出一个模型,这个模型就是给文档算法的函数f(d, w)。其中d为文档特征,w为模型参数。
输入:query的许多个文档结果,每个文档需要人为标注得分,等分越高的说明排名越靠前;
输出:打分模型f(d, w)。
Step 1:把query的结果分成pair,计算pair中排名的概率。在pair中,如果Ui排在Uj的前面,概率为:
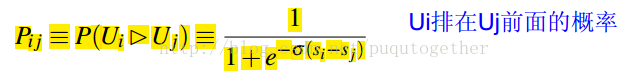
而Ui排在Uj的前面的真实概率计算为:
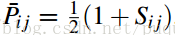
其中Sij=1表明Ui真实情况就是排在Uj的前面;否则,就是Ui排在Uj的后面。
Step 2:交叉熵作为损失函数。

这个损失函数是用来衡量Pij和Pij_的拟合程度的,当两个文档的不相关时,给与了一定的惩罚,让它们分开。RankNet算法没有使用学习排序中的一些衡量指标直接作为损失函数的原因在于,它们的函数形式都不是很连续,不太好求导,也就不太好用梯度下降法。而交叉熵的函数形式比较适合梯度下降法。
Step 3:梯度下降法更新迭代求最优的模型参数w。显然,我们需要设置一定的学习步长,不断的更新学习新的w,具体公式如下:
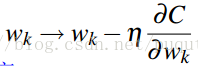
后面就是求损失函数C关于w的偏导计算公式了,如下:
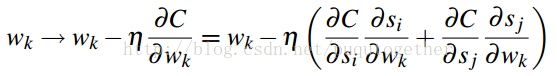
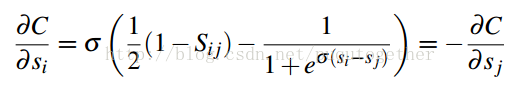
上式中,得分s关于w的偏导和具体的学习模型有关,原始的RankNet方法使用的是神经网络模型。这个需要具体模型,具体分析。
这样我们便直到了如何通过梯度下降法来求RankNet中的打分模型了~
最后我们说一下RankNet算法的一大好处:使用的是交叉熵作为损失函数,它求导方便,适合梯度下降法的框架;而且,即使两个不相关的文档的得分相同时,C也不为零,还是会有惩罚项的。














 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









