










【实例一】
分布式估算pi
假设正方形边长为x,则正方形面积为:x*x,圆的面积为:pi*(x/2)*(x/2),两者之比为:4/pi
随机产生位于正方形内的点x个,假设位于园中的有y个,则:pi=4*y/x
当x->无群大时,pi逼近真实值

object SparkPi{ //不要用继承,会有各种麻烦
def main(args:Array[String]){
//常规spark程序写法
val conf=new SparkConf().setAppName("Spark Pi")
val sc=new SparkContext(conf)
//args(0)表示启动几个task,默认是2,else 2
val slices=if(args.length>0)args(0).tolnt else 2//并发度2
val n=100000*slices //n表示x,产生多少点
//产生RDD元素1~n,RDD分成两个partition,每个partition执行下面逻辑
val count=sc.parallelize(1 to n,slices).map{i=>
val x=random*2-1 //random产生[0,1]之间的随机数。[-1,1]
val y=random*2-1 //[-1,1]
if(x*x+y*y<1) 1 else 0 //落到圆中记为1
}.reduce(_+_) //加起来,既得落到圆中点的数量
println("Pi is roughly" + 4.0 * count/n) //count是落到圆中的点,n是产生点的总数量
spark.stop()
}
}【实例二】
log query

任务:如何统计每个用户在每台机器(ip)上的查询(query)的次数和返回结果累积大小(byte)?
正则表达式提取出我们想要的字段:
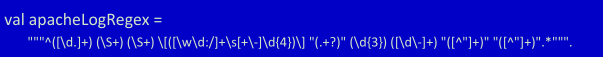
辅助函数:
//给我一行日志,返回(三元组)ip,user, 用户查询语句

//Stats(1,bytes.tolnt),1设置为1一个整数,bytes.tolnt(用户查询之后返回的元素大小)

代码开发过程:
object LogQuery{
def main(args:Array[String]){
val conf=new SparkConf().setAppName("Log Query")
val sc=new SparkContext(conf)
val dataset=sc.textFile(args(0))//传入参数(文本文件,映射成RDD)一行一行的日志
dataSet.map(line=>(extractKey(line),extractStats(line)))//对每一行日志执行一次这两个函数。extractKey(line)返回三元组,extractStats(line)返回一个对象。每一行日志映射为key/value对。
.reduceByKey((a,b)=>a.merge(b))//做归约把key相同的放到一起。对value做一个merge。a->extractStats(line)。a,b是如下图片所示Stats对象。
.collect().foreach{
case(user,query)=>println("%s\t%s".format(user,query))}//返回并打印
}
}merge函数示例:

【实例三】
逻辑回归(可以看成一个分类算法)迭代算法
找出一条最优的线,将所有点分成两部分
——寻找危险因素
——预测
——判别
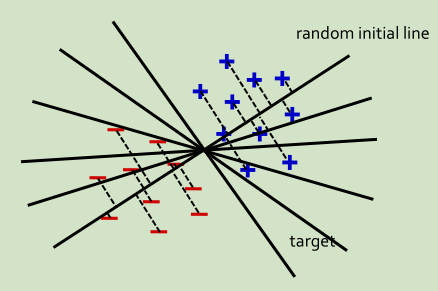
假设我们有很多点,就是数据样本,每个点就是一个数据样本,每个点有可能是多维的,通过训练找一条线(取决于是何种回归算法,线性回归可就是找一条线),这条线可以把这个文本集分成两类。有了这条线之后就可以把这条线拿来用在未知的样本上,对未知样本进行分类。
每一轮迭代都会求一个参数(权重的向量),之后可以根据向量求它离目标有多远。然后一直更新更新!直到我们求出的线是在可接受的误差范围内!
val D=10
val pointsRdd=sc.textFile(hdfs://...)//样本每次迭代都要读取所以使用cache
.map(parsePoint)
.cache()
var weight = Vector.random()//产生一个初始的权重列表
for(1 to ITERATIONS){
val gradient=pointsRdd.map(p=>calcGradient(p,weight))
.reduce(_+_)
weight-=gradient
}//进行迭代,更新权重
println("Result:" + weight)//最后把权重输出出来代码展示:

















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











