







引论(出自http://blog.csdn.net/changyuanchn/article/details/14564403)
前面已经有了链表,堆栈,队列,树等数据结构,尤其是树,是一个很强大的数据结构,能做很多事情,那么为什么还要引进一个优先队列的东东呢?它和队列有什么本质的不同呢?看一个例子,有一个打印机,但是有很多的文件需要打印,那么这些任务必然要排队等候打印机逐步的处理。这里就产生了一个问题。原则上说先来的先处理,但是有一个文件100页,它排在另一个1页的文件的前面,那么可能我们要先打印这个1页的文件比较合理。因此为了解决这一类的问题,提出了优先队列的模型。
优先队列是一个至少能够提供插入(Insert)和删除最小(DeleteMin)这两种操作的数据结构。对应于队列的操作,Insert相当于Enqueue,DeleteMin相当于Dequeue。
链表,二叉查找树,都可以提供插入(Insert)和删除最小(DeleteMin)这两种操作,但是为什么不用它们而引入了新的数据结构的。原因在于应用前两者需要较高的时间复杂度。对于链表的实现,插入需要O(1),删除最小需要遍历链表,故需要O(N)。对于二叉查找树,这两种操作都需要O(logN);而且随着不停的DeleteMin的操作,二叉查找树会变得非常不平衡;同时使用二叉查找树有些浪费,因此很多操作根本不需要。
因此这里引入一种新的数据结构,它能够使插入(Insert)和删除最小(DeleteMin)这两种操作的最坏时间复杂度为O(N),而插入的平均时间复杂度为常数时间,即O(1)。同时不需要引入指针。
当我们删除一个数组中的最小数,然后再插入一个数,当这种操作频度较大,或者数据太多,进行这种排序的操作,或者插入的操作的时候,时间复杂度较大,因此我们使用堆来进行数据的处理。
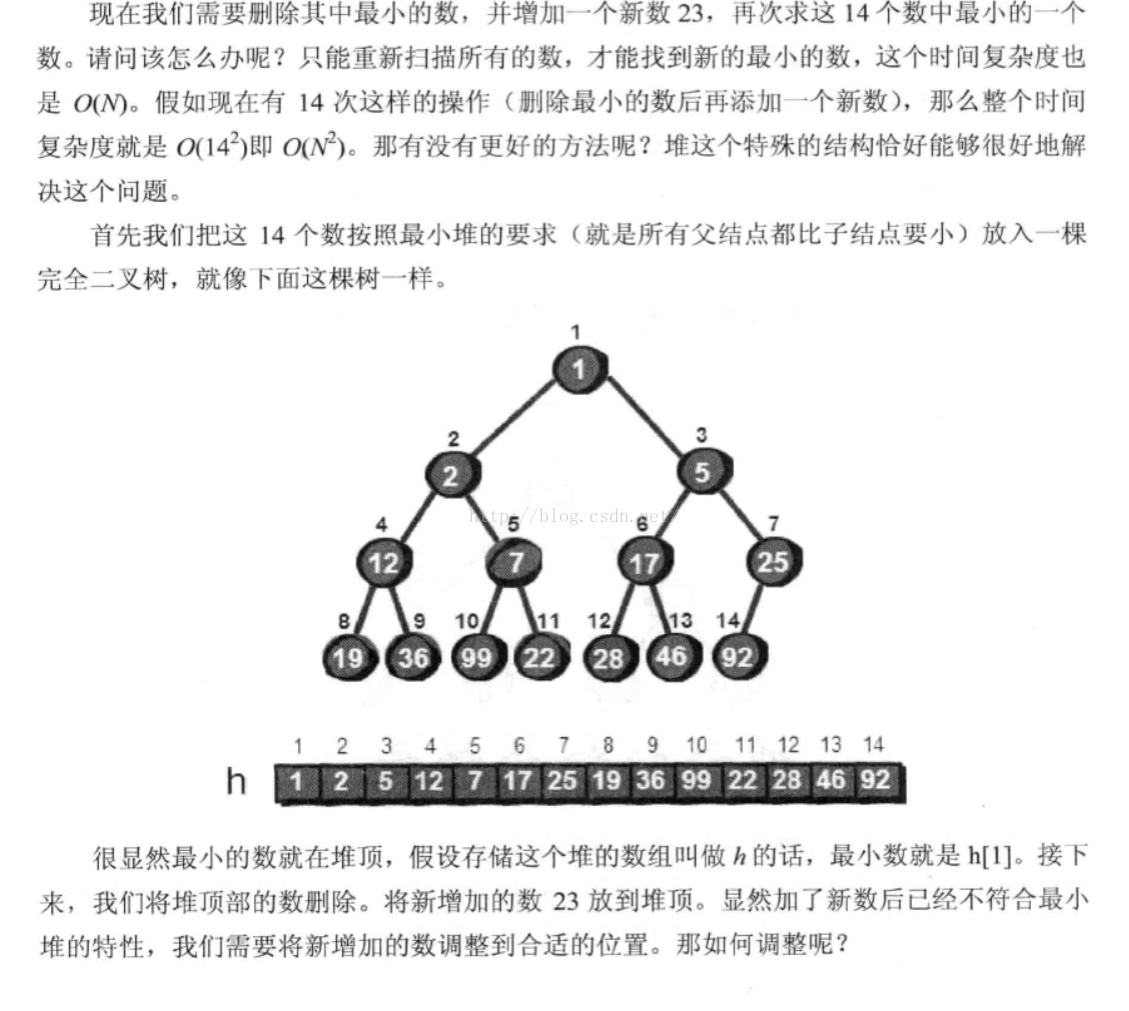
堆也是用数组进行储存的,它是一种特殊的完全二叉树,根据它们的性质不同分为最小堆和最大堆,最小堆是指对于每一个父亲结点都比孩子结点小,最大堆反之,因为这种特性,所以为我们再进行排序,插入后排序构造了方便。
删除后插入的调整
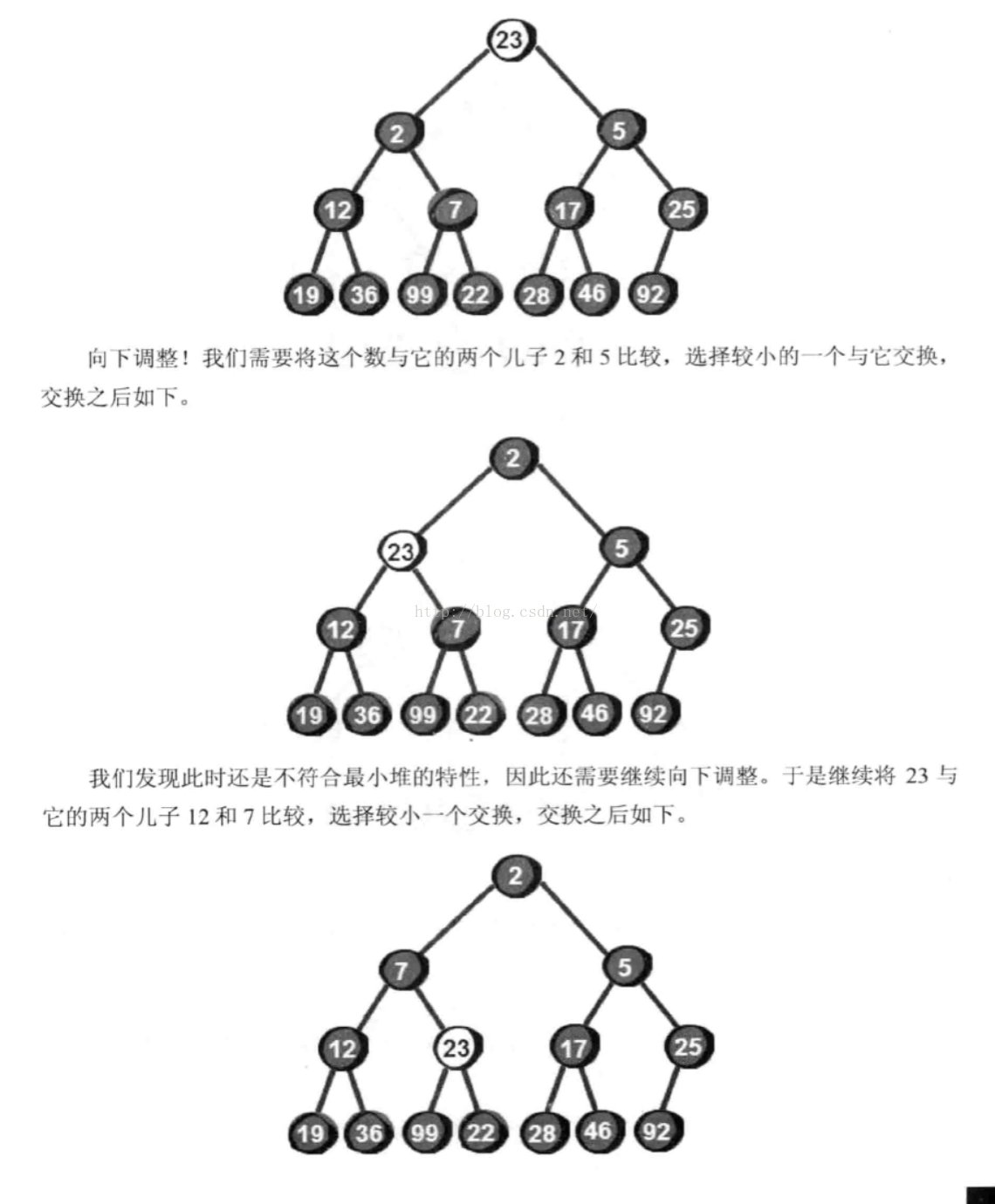
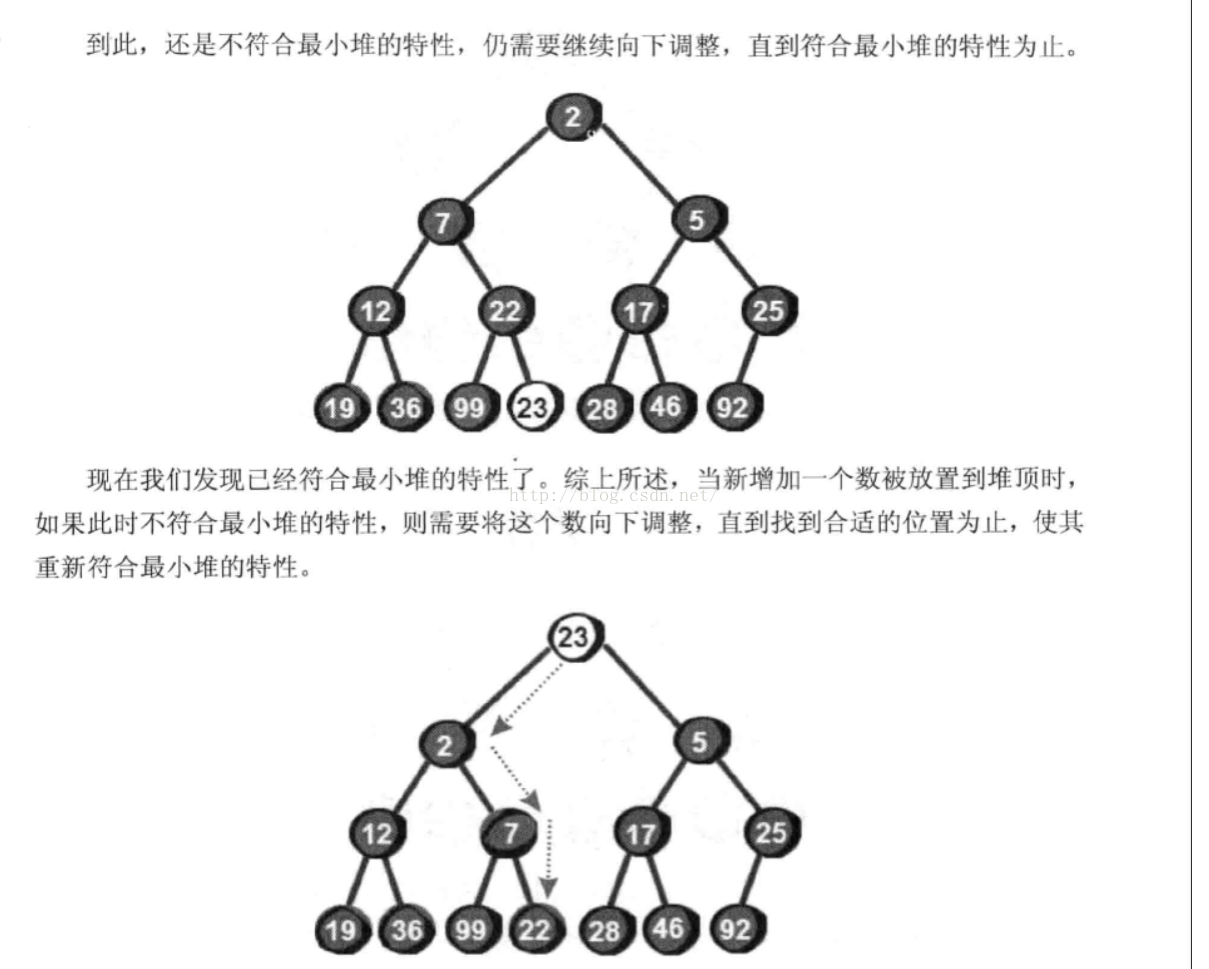
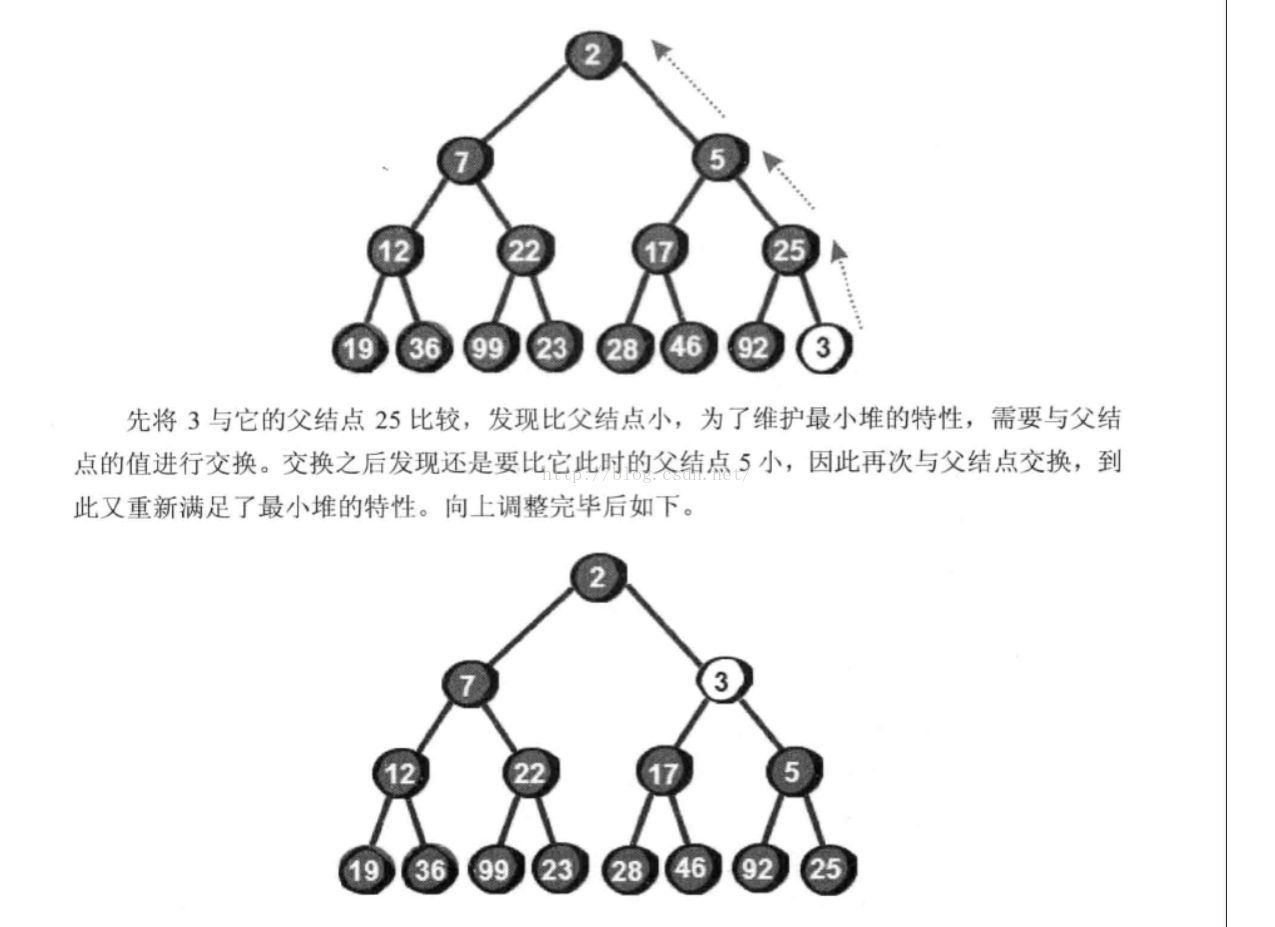
不删除插入的调整
<span style="font-size:14px;">void siftleft(int i)
{
int flag=0;
if(i==1)
return;
while(i!=1 && flag==0)
{
if(h[i]<h[i/2])
{
swap(i,i/2);
}
else
flag=1;
i=i/2;
}
}</span>完整的从小到大输出代码
#include <iostream>
using namespace std;
int n,h[1000];
void swap(int a,int b)
{
int c;
c=h[a];
h[a]=h[b];
h[b]=c;
}
void siftdown(int i)
{
int flag=0,t;
while(i*2<=n && flag==0)
{
if(h[i]>h[i*2])
{
t=i*2;
}
else
t=i;
if(i*2+1<=n)
{
if(h[t]>h[i*2+1])
{
t=i*2+1;
}
}
if(t!=i)
{
swap(t,i);
i=t;
}
else
{
flag=1;
}
}
}
void create()
{
for(int i=n/2;i>=1;i--)
{
siftdown(i);
}
}
int delete_()
{
int t;
t=h[1];
h[1]=h[n];
n--;
siftdown(1);
return t;
}
int main()
{
int i,num;
cin>>num;
for(i=1;i<=num;i++)
cin>>h[i];
n=num;
create();
for(i=1;i<=num;i++)
{
printf("%d ",delete_());
}
}














 1202
1202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









