







向量空间模型(VSM:Vector space model)是最常用的相似度计算模型,在自然语言处理中有着广泛的应用,这里简单介绍一下其在进行文档间相似度计算时的原理。
假设共有十个词:w1,w2,......,w10,而共有三篇文章,d1,d2和d3。统计所得的词频表(杜撰的,为了便于演示用法)如下:
|
| w1 | w2 | w3 | w4 | w5 | w6 | w7 | w8 | w9 | w10 |
| d1 | 1 | 2 |
| 5 |
| 7 |
| 9 |
|
|
| d2 |
| 3 |
| 4 |
| 6 | 8 |
|
|
|
| d3 | 10 |
| 11 |
| 12 |
|
| 13 | 14 | 15 |
常用的向量空间公式见下图:

假设计算d1和d2的相似度,那么ai和bi分别表示d1和d2中各个词的词频,我们以Cosine为例:
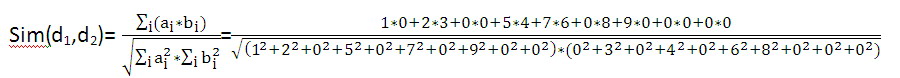
(得数请读者自己计算,各个数代表什么从上表中可以轻易看出)
为什么叫向量空间模型呢?其实我们可以把每个词给看成一个维度,而词的频率看成其值(有向),即向量,这样每篇文章的词及其频率就构成了一个i维空间图,两个文档的相似度就是两个空间图的接近度。假设文章只有两维的话,那么空间图就可以画在一个平面直角坐标系当中,读者可以假想两篇只有两个词的文章画图进行理解。
我们看到,上面公式的计算量是很大的,尤其当文档中词数量巨大时。那么怎么样来提高运算的效率呢?我们可以采取降维的方法。其实只要理解了向量空间模型原理,就不难理解降维的概念。所谓降维,就是降低维度。具体到文档相似度计算,就是减少词语的数量。常见的可用于降维的词以功能词和停用词为主(如:"的","这"等),事实上,采取降维的策略在很多情况下不仅可以提高效率,还可以提高精度。这也不难理解,比如下面两句话(可能举地不是特别恰当,见谅):
- 这是我的饭。
- 那是你的饭。
如果把"这"、"那"、"你"、"我"、"是"、"的"都当功能词处理掉,那么相似度就是100%。如果都不去掉,相似度可能只有60%。而这两句话的主题显示是一样的。
倒排词频平滑(Inverse Document Frequency)方法,就是用整个语料中所有词语的词频来调整某篇语料中词语的权重,可以理解为把某篇内词语的频率与全局词频相乘后再代入公式(因为相似度是个相对值,所以只要保证它的值落在0和1之间即可)。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
直接使用词的个数在比较词数很多和词数很少的文档时存在着问题。例如文档I中含有10000个词,而词a出现了10次;文档II中含有100个词,而a出现了5次。这样在相似度计算时,文档I中a对最后结果的影响比文档II中的a要大。这显然是不合理的,因为a只点文档I的0.1%而却占文档II的5%。为了解决这类问题,我们引入词频(TF)和反词频(IDF)两个概念。














 2745
2745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









