







 本文详细介绍了数据挖掘的步骤,包括字段选择、数据清洗、编码、数据挖掘、模型评估等,并探讨了变量分类、相关分析、卡方统计量、模型评估方法(如混淆矩阵、增益曲线)和数据转换技术(如正规化、离散化)。此外,还讨论了多种数据挖掘方法,如决策树、神经网络、逻辑回归和聚类分析,以及关联规则挖掘。
本文详细介绍了数据挖掘的步骤,包括字段选择、数据清洗、编码、数据挖掘、模型评估等,并探讨了变量分类、相关分析、卡方统计量、模型评估方法(如混淆矩阵、增益曲线)和数据转换技术(如正规化、离散化)。此外,还讨论了多种数据挖掘方法,如决策树、神经网络、逻辑回归和聚类分析,以及关联规则挖掘。
变量分类
SAS中
Binary:是二值类别型
Norninal:名义型,即多元类别型
Interval:数值型变量
Ordinal:顺序型,有序因子modeler中
nornimal:名以变量,指分类的1,2,3,4…变量,在R语言中叫因子.
continual:连续变量,指变量本身是数值的.
flag:标识,二值类别型,在只有两类的情况下,nornimal会退化成flag.
数据挖掘的6步骤
- 字段选择 attribute select
- 数据清洗 data cleaning
- 字段扩充 attribute enrichment(将其他部门的也扩充进去)
- 数据编码 data coding
- 数据挖掘 data mining
- 风险和报告 report
数据库的数据可能也是错的
如:同一个人但是有两个不同的名字
本身只有5种杂志但是有6个不同的名字
日期的购买日期大于开店的时间
住址本身没有用,但是可以整理成区域
data_coding:重编码
出生日期 –> 年龄
住址 –>区域
归一化,标准化
编码方式决定结果的形态,方式,或者结果的产生,或者能不能得到好结果
摊平处理
一个人一般只会有一笔记录,如果有多条记录,则需要摊平处理,比如购买5种杂志会有5条记录,则需要修改为是否购买1,2,3,4,5杂志这5个新字段。
即:行转列
相关分析
- 分类变量之间的相关关系:卡方统计量
- 连续变量之间的相关关系:pearson和斯皮尔曼(秩相关)
- 分类和连续变量之间的关系:两个就是t检验,3个及已收到就是方差分析,其原假设是均值相等或者方差相等。
学生化(标准化)
建议临界值:
|SR|>2:用于观察值较少的数据集
|SR|>3:用于观察值较多的数据集
字段观测方法
数值型字段:输出各种描述性统计量,直方图
类别型字段:用分布图
卡方统计量
- X^2 = (观察个数-期望个数)^2/期望数
- 再求 X2i 的和
- 先看总体的分布比例
- 如果总体的分布比例在各个子分类的情况下是一样的,则说明卡方值小
卡方值越大,代表字段与目标之间的关系越紧密。 - 先看总体的分布比例
- 先看在第一维度的各个概率值
- 再看第二维度的各个该录制
- 维度1 x 维度2 的各个概率值组合,得到理论概率值(期望 = 该概率值 x 总数)。前提是独立性假设,即音乐和酒之间是独立的,才能两个概率相乘。
- 看实际的两个维度下的各个实际值
- 看期望值和和实际值之间相差大不大,计算卡方值
数据挖掘的分类
描述性数据挖掘:无目标字段
关联规则:找出哪些事件会一起出现
集群分析:找出内部结果(聚类分析)
序列型样:循环出现,按照一定的顺序出现预测性数据挖掘:有目标字段
应用场景:
决策->分类
排序->信用卡评分
估计->预测数值,判断所属类别的概率预测->目标字段是数值型型(决策树,类神经网络,线性回归,时间序列)
分类->目标字段是分类型的(贝氏网络,决策树,神经网络,逻辑回归)
模型的评估
1.Gain-Cart绩效增益曲线
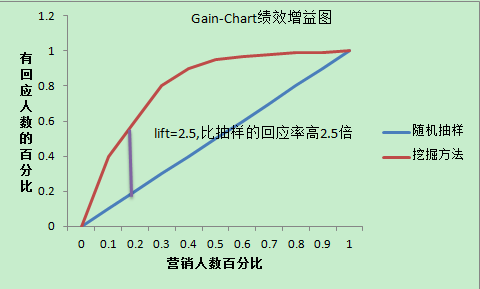
2.Lift-Chart绩效的增益
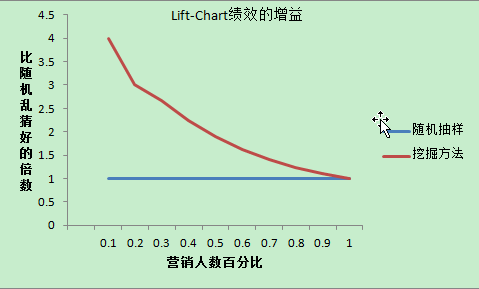
3.成本-收益矩阵(cost-matrix)
| 预测\实际 | 有 | 无 |
|---|---|---|
| 有 | 44元 | -1元 |
| 无 | 0元 | 0元 |
这是成本收益矩阵,取预测的前10%的人计算成本与收益,画图。
绘制10%,20%,30%……得到成本收益图。
建立区隔化模型
将年龄分三段,然后分别建立模型
噪声处理
1.类别型:看分布,找错误值
2.数值型:看分布,找离群值
3.用箱线图
4.均值3倍标准差
错误值
视为空值–>在用空值填补法(用fillter节点,即填充、替换的意思)
空值
banks and null 中的”undef”,也可以写成’ null ’(比较麻烦, null 外面还要有单引号)
空字符串:用两个双引号引住,没有空格即可。
离群值
1.排序后用肉眼看也是可以的,但是不好
2.均值的3倍标准差
3.四分位数法
处理:视为空值(替换),然后用空值填补法
天花板/地板法(比较好),结合四分位数替换
重要:在输出面板–>数据审核节点(离群值、空值)–>然后在数据审核的质量面板进行替换操作
数据审核节点–>质量面板
强制:使用天花板地板法替换
丢弃:这笔数据就不要了
无效:将离群值变成空值
处理空值的方法
- 直接删除
如果目标字段为空值,那么这条记录也是没办法用的,要删除
如果字段缺失值比例较大(50%),那么这个字段可以删除
modeler对应的空值过滤节点操作:
数据审核节点-->质量面板-->生成菜单-->缺失值选择节点- 将空值转变成指示变量
如果有空值则为0,无空值则1。
modeler对应的空值过滤节点操作:
使用导出节点:基于现有的字段产生新字段
选择导出为公式
函数选择 “逻辑函数”,空值的写法是 '$null$'- 空值填补
3.1 填入未知,那么这个是一个新的类型,但是建模的时候会有问题,很难解释模型的结果
3.2 填入众数:也可以用分类的方式,分类求众数
3.3 用推论法:把缺失值问题当作分类的问题
modeler对应的空值填补节点操作:
还是数据审核节点-->质量面板:四分位数法-->运行
-->在结果面板中:缺失值插补(选择空值),方法(指定)
-->然后算法(C&RT)
-->生产处理空值的超节点
# 指定的方法选项中也包括了众数,常数,未知(在常量)什么的
# C&RT算法针对的是类别型变量
# 如果是数值型变量:可以用众数,中位数,均值什么的填补空值,或者用推论法,将空值当作分类预测问题模型评估:
模型建完后如何看正确率
输出-->分析节点混淆矩阵
正确率(Accurary) = (实际为对–>预测为对,实际为错–>预测为错)/总数
回应率,命中率(pression) = (实际为对–>预测为对)/(预测为对的数量)
也就是预测集合中有多少是对的捕捉率,查全率(recall) = (实际为对–>预测为对)/(实际为对的数量)
也就是实际对的集合中预测对了几个F-指标 = (2 x 回应率 x 捕捉率)/(回应率+捕捉率)
F-指标只有在回应率和捕捉率都高的情况下才高,不然数据结果容易被人做手脚。
命中率:你预测为对的数据中,实际对了几个
捕捉率:在对的数据中,你猜中了多少个
果然是见名知意啊。
混淆矩阵在分析节点的第一个选项
模型之后接一个table节点
可以看到模型预测的概率值
模型之后接排序节点
则可以制作Gain-Chart增益曲线
即选择回应率什么的最高的前多少用户3种评估预测模型好坏的方法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 842
842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









