







- 算法排序
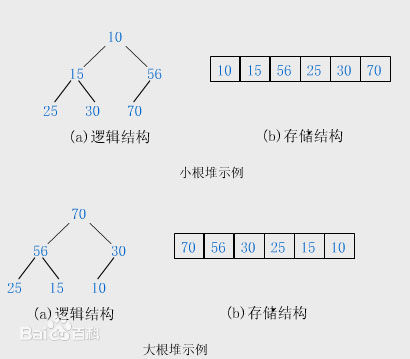
堆排序类似于归并排序,二叉堆是一个数组,它可以被看成一个近似的完全二叉树。树上的每一个节点对应数组中的一个元素。
在排序算法中我们使用的最大堆。
2.
package sxd.learn.algorithms;
/**
* date Mar 19, 2015
* desc HeapSort 堆排序
*/
public class HeapSort {
private static int heapSize = 0;
public static void main(String[] args) {
// TODO Auto-generated method stub
int[] iArray = {4, 1, 3, 2, 16, 9, 10, 14, 8, 7};
heapSize = iArray.length;
BUILD_MAZ_HEAP(iArray);
HEAP_SORT(iArray);
for(int i : iArray){
System.out.print(i + " ");
}
}
public static void HEAP_SORT(int[] iArray){
for(int i = iArray.length - 1; i>= 0; i--){
EXCHANGE(iArray,0, i);
heapSize--;
MAX_HEAPIFY(iArray,0);
}
}
public static void BUILD_MAZ_HEAP(int[] iArray){
//iArray[n/2 + 1......n]都是叶子节点,已经满足最大堆性质
for(int i = iArray.length / 2; i >= 0; i--){
MAX_HEAPIFY(iArray, i);
}
}
/**
* @param iArray
* @param index
* 维持最大堆的性质,即使iArray[i]节点满足最大堆的性质
*/
public static void MAX_HEAPIFY(int[] iArray, int index){
int lIndex = LEFT(index);
int rIndex = RIGHT(index);
int largest = index;
//lIndex <= heapSize判断是为了放置溢出,某些节点没有孩子节点或者没有右孩子节点
if(lIndex < heapSize && iArray[lIndex] > iArray[index]){
largest = lIndex;
}
if(rIndex < heapSize && iArray[rIndex] > iArray[largest]){
largest = rIndex;
}
if(largest != index){
EXCHANGE(iArray,index,largest);
MAX_HEAPIFY(iArray, largest);
}
}
//返回i节点的左孩子节点的下标
public static int LEFT(int i){
return 2 * i + 1;
}
//返回i节点的右孩子节点的下标
public static int RIGHT(int i){
return 2 * i + 2;
}
/**
* @param iArray
* @param i
* @param j
* 交换数组中i,j下标的位置
*/
public static void EXCHANGE(int[] iArray, int i, int j){
int temp = iArray[i];
iArray[i] = iArray[j];
iArray[j] = temp;
}
}
3.算法分析
堆排序和归并排序一样,算法时间复杂度为O(nlgn),并与插入排序相同具有空间原址性。















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









