







1.波士顿房价线性回归模型
from sklearn import datasets
from sklearn.linear_model import LinearRegression
boston = datasets.load_boston()
data_X = boston.data
y = boston.target
model = LinearRegression()
model.fit(data_X,y)
pred = model.predict(data_X[:2,:])
actu = y[:2]
print(pred)
print(actu)
output:
前两个房屋预测价格:[ 30.00821269 25.0298606 ]
前两个房屋实际价格:[ 24. 21.6]
可见误差还是挺大的,还需要很多工作来对模型进行优化
2.对鸢尾花降维
from sklearn import datasets
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
iris = datasets.load_iris()
X = iris.data
y = iris.target
pca = PCA(n_components = 2)
reduced_X = pca.fit_transform(X)
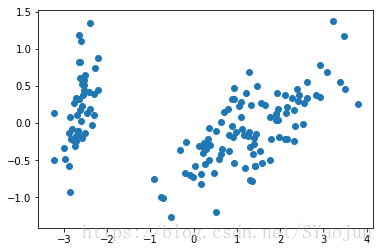
plt.scatter(reduced_X[:,:1],reduced_X[:,1:2])
鸢尾花原本是三种类别,此处把原本4个特征维度降低为2个特征维度,但是大致还是三类
3.KNN对鸢尾花分类
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris_X,iris_y = datasets.load_iris(return_X_y=True)
knn = KNeighborsClassifier()
X_train,X_test,y_train,y_test = train_test_split(iris_X,iris_y,test_size=0.3)
knn.fit(X_train,y_train)
print(knn.predict(X_test))
print(y_test)
output:
KNN测试集预测分类:[1 2 1 0 0 2 0 1 2 0 2 0 2 0 2 0 0 2 1 0 1 2 1 0 1 2 0 1 0 0 0 1 1 0 0 0 1 2 2 0 2 1 1 0 1]
KNN测试集实际分类:[1 2 1 0 0 2 0 1 2 0 1 0 2 0 2 0 0 2 1 0 1 2 1 0 1 2 0 1 0 0 0 1 1 0 0 0 1 2 2 0 2 1 1 0 2]
knn默认选择近邻5个数据,使用交叉验证,test数据为总数据的30%
4.标准化数据
import numpy as np
from sklearn import preprocessing
a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]])
print(a)
print(preprocessing.scale(a))
print(preprocessing.minmax_scale(a))
print(preprocessing.minmax_scale(a,feature_range=(-1,1)))
第三个输出默认标准化范围为0到1,第四个输出自定义标准化范围在-1到1之间
5.支持向量机对鸢尾花分类
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.svm import SVC
iris_X,iris_y = datasets.load_iris(return_X_y=True)
X_train,X_test,y_train,y_test = train_test_split(iris_X,iris_y,test_size=0.3)
clf = SVC()
clf.fit(X_train,y_train)
print(clf.predict(X_test))
print(y_test)
print(clf.score(X_test,y_test))
每次得到的结果都不相同,可能跟交叉验证取值有关吧,其中的训练数据70%应该是随机抽取的
6.交叉验证KNN中近邻数对精度的影响
from sklearn import datasets
from sklearn.cross_validation import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
iris_X,iris_y = datasets.load_iris(return_X_y=True)
krange = range(1,31)
kscores=[]
for k in krange:
knn = KNeighborsClassifier(n_neighbors = k)
scores = cross_val_score(knn,iris_X,iris_y,cv=10,scoring='accuracy')
kscores.append(scores.mean())
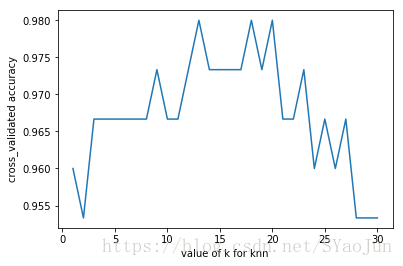
plt.plot(krange,kscores)
plt.xlabel('value of k for knn')
plt.ylabel('cross_validated accuracy')
plt.show()














 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









