










第二篇 MapReduce日志分析
做日志分析之前, 我觉得要先了解下MapReduce , 网上很多, 你可以搜下, 这位哥们讲的还不错 点击打开链接
日志长这样的:
<?php if ( ! defined('ROOT_PATH')) exit('No direct script access allowed'); ?>
[2016-06-01 00:10:27] POST 218.82.131.157 /user/HealthCenter.php?m=submit uid=14&hash=dd16e3e4d0e8786f13166a4065f24fa0&num=13.0&type=1&time=1464711029 0(OK)
[2016-06-01 08:10:27] POST 218.82.131.157 /user/HealthCenter.php?m=submit uid=14&hash=863fbf2535639c16d885a55c78dff665&num=13.0&type=1&time=1464739829 0(OK)
[2016-06-01 09:10:28] POST 124.74.69.134 /user/HealthCenter.php?m=submit uid=14&hash=9a310b722e795e2673cdba76bea29b26&num=13.0&type=1&time=1464743429 0(OK)
[2016-06-01 09:16:05] GET 124.74.69.134 /index/Main.php?hash=eac57627d3407963dab81da2bb07e378&page_num=1&page_size=10&time=1464743769&uid=8 0(OK)
[2016-06-01 10:01:30] GET 124.74.69.134 /index/Main.php?hash=7979353ef669c61f75a5a7e9d39cd646&page_num=1&page_size=10&time=1464746494&uid=8 0(OK)
[2016-06-01 10:10:28] POST124.74.69.134 /user/HealthCenter.php?m=submit uid=14&hash=98012832769b5a0e45f036e92032f1ef&num=13.0&type=1&time=1464747029 0(OK)
[2016-06-01 10:11:12] GET 124.74.69.134 /index/Main.php?hash=77938b0fdf1b733a9e15d9a2055767d1&page_num=1&page_size=10&time=1464747076&uid=8 0(OK)
[2016-06-01 10:48:00] GET 124.74.69.134 /index/Main.php?hash=1a1979e9fdcfca2f17bf1b287f4508aa&page_num=1&page_size=10&time=1464749284&uid=8 0(OK)
[2016-06-01 10:48:42] POST 124.74.69.134 /user/Position.php uid=9&address=undefine&latitude=4.9E-324&time=1464749394&type=1&hash=d4aebe936762be3a0420b62a77e37b00&longitude=4.9E-324 0(OK)分别是: 时间 请求方式 IP 请求地址 参数 返回值
每天产生一个, 分别已Y-m-d.php 方式命名.
达到的目的是: 统计每天 每个接口的请求次数, 以返回结果分组,
编写程序
/**
* @ClassName: LogMapReduce.java
* @author 273030282@qq.com
* @version V1.0
* @Date 2016-7-11 10:20:11
* @Description: TODO
*
*/
package www.com.cn;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class LogMapReduce extends Configured implements Tool {
public static void main(String[] args) {
Configuration conf = new Configuration();
try {
int res = ToolRunner.run(conf, new LogMapReduce(), args);
System.exit(res);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
final Job job = Job.getInstance(conf, "LogParaseMapReduce");
job.setJarByClass(LogMapReduce.class);
FileInputFormat.setInputPaths(job, args[0]);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean success = job.waitForCompletion(true);
if (success) {
System.out.println("process success!");
} else {
System.out.println("process failed!");
}
return 0;
}
enum Counter{
LINESKIP,
}
static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if ("".equals(value)) {
return;
}
String line = value.toString();
if (line.length() == 0 || !"[".equals(line.substring(0, 1))) {
return;
}
try {
String[] lines = line.split(" ");
String data = lines[0].replace("[", "") + "\t";
if ("GET".equals(lines[2])) {
String url = "";
String[] urls = lines[4].split("[?]");
String[] params = urls[1].split("[&]");
if (params[0].indexOf('m') != -1) {
url = urls[0] + "?" + params[0];
} else {
url = urls[0];
}
data += url + "\t" + lines[5];
} else if ("POST".equals(lines[2])) {
data += lines[4] + "\t" + lines[6];
}
Text out = new Text(data);
context.write(out, one);
} catch (ArrayIndexOutOfBoundsException e) {
context.getCounter(Counter.LINESKIP).increment(1);
}
}
}
static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable v: values) {
count = count + 1;
}
context.write(key, new IntWritable(count));
}
}
}然后将程序打jar包:LogMapReduce.jar
打包时注意选择 Main class, 这时候选择就不用在调用时指定包目录了
Shell脚本
脚本分为两个, 一个执行脚本, 一个运行执行的脚本
运行脚本 run.sh:
#! /bin/bash
d=`date "+%Y-%m-%d %H:%M:%S"`
echo "{$d} start..."
file=$1;
if [ -f ${file} ];then
echo "${file} exists"
else
echo "${file} not exists"
exit 0
fi
#获取文件名
fileinfo=(${file })
filename=${fileinfo[$[${#fileinfo[@]}-1]]}
info=(${filename//./ })
name=${info[0]}
echo "hadoop put file to /api/put/${filename}"
hadoop fs -put ${file} /api/put/${filename}
echo "call LogMapReduce.jar"
hadoop jar /home/hadoop/hadoop-2.7.0/share/hadoop/mapreduce/LogMapReduce.jar /api/put/${filename} /api/out/${name}
echo "hive load into api_logs"
hive -e "load data inpath '/api/out/${name}/part-r-00000' into table apis.api_logs"
echo "delete /api/put/${filename}"
hadoop fs -rm /api/put/${filename}
echo "delete /api/out/${name}"
hadoop fs -rmr /api/out/${name}
echo "end"
~ 大致的逻辑, 接收传入的文件(含路径), 然后分割, 得到文件名, 然后将文件put到hadoop, 调用LogMapReduce.jar, 将结果插入到hive, 删除文件
运行执行的脚本 process_2016_06.sh:
#!/bin/sh
for((i=5;i<31;i++))
do
logdate=`printf "%'.02d" $i`
./run.sh /home/hadoop/data/2016-06-${logdate}.php
done也可以折腾在一起.
折腾到hive 就i可以查询了, 比如查询6月份失败率前20
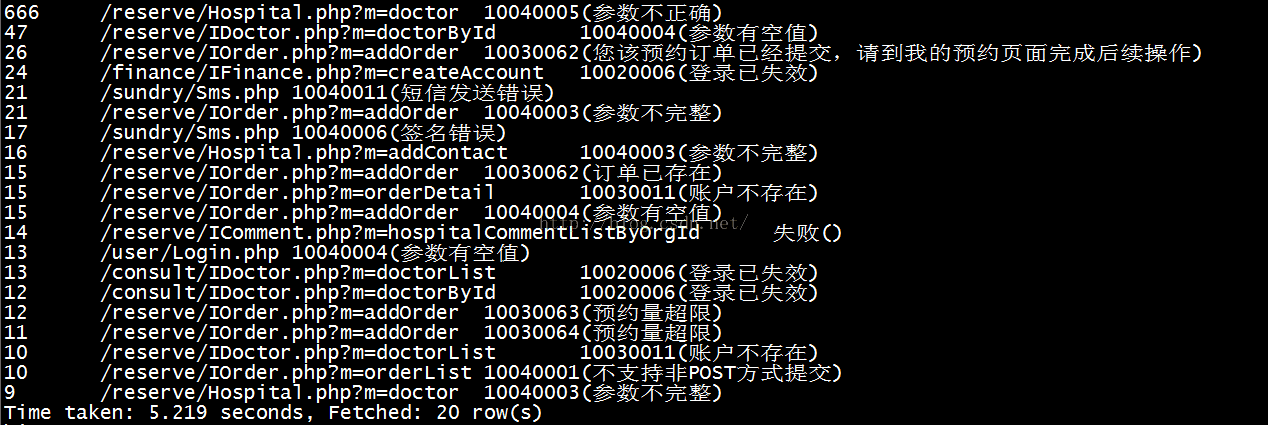














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









