







感谢朋友支持本博客,欢迎共同探讨交流,由于能力和时间有限,错误之处在所难免,欢迎指正!
如有转载,请保留源作者博客信息。
如需交流,欢迎大家博客留言。
1、filer调度函数入口:
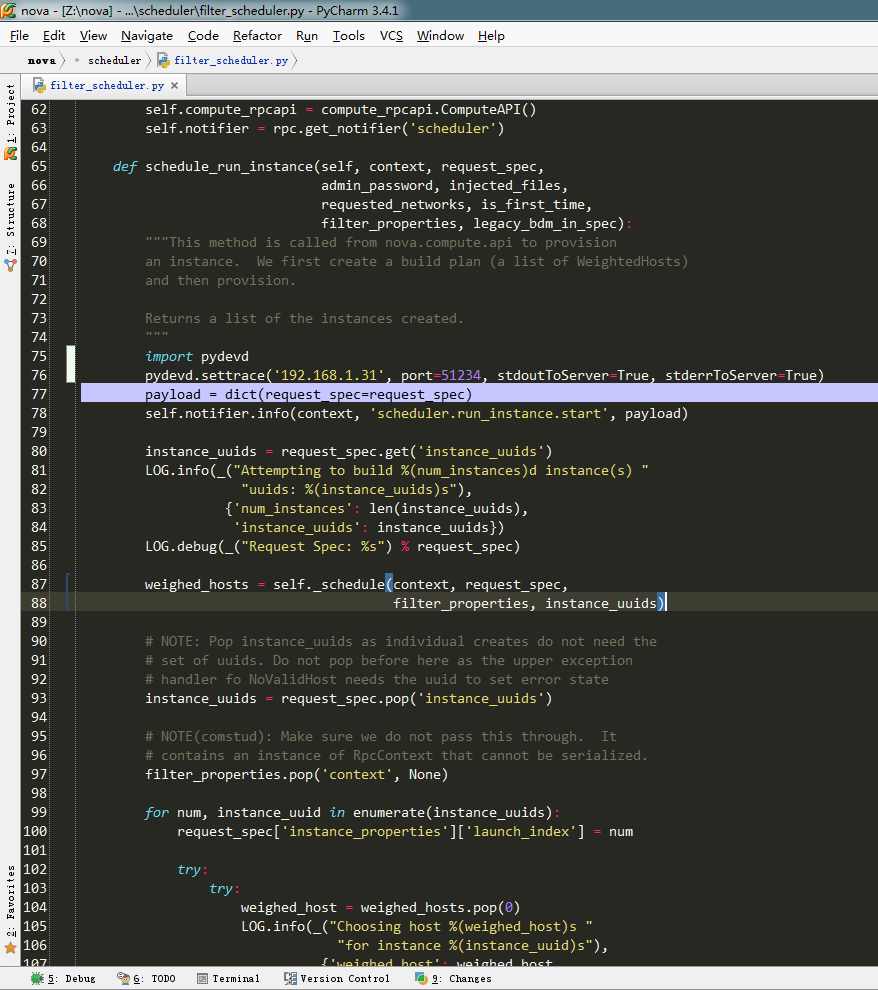
payload = dict(request_spec=request_spec)
#构造一个payload字典
self.notifier.info(context, 'scheduler.run_instance.start', payload)
#通知nova API开始执行调度
instance_uuids = request_spec.get('instance_uuids')
#获取uuid
LOG.info(_("Attempting to build %(num_instances)d instance(s) "
"uuids: %(instance_uuids)s"),
{'num_instances': len(instance_uuids),
'instance_uuids': instance_uuids})
LOG.debug(_("Request Spec: %s") % request_spec)
#获取所有节点的权重列表:具体参考1.1:
weighed_hosts = self._schedule(context, request_spec,
filter_properties, instance_uuids)
# NOTE: Pop instance_uuids as individual creates do not need the
# set of uuids. Do not pop before here as the upper exception
# handler fo NoValidHost needs the uuid to set error state
instance_uuids = request_spec.pop('instance_uuids')
# NOTE(comstud): Make sure we do not pass this through. It
# contains an instance of RpcContext that cannot be serialized.
filter_properties.pop('context', None)
#为每个虚拟机分配计算节点
for num, instance_uuid in enumerate(instance_uuids):
request_spec['instance_properties']['launch_index'] = num
try:
try:
weighed_host = weighed_hosts.pop(0)
LOG.info(_("Choosing host %(weighed_host)s "
"for instance %(instance_uuid)s"),
{'weighed_host': weighed_host,
'instance_uuid': instance_uuid})
except IndexError:
raise exception.NoValidHost(reason="")
self._provision_resource(context, weighed_host,
#远程调用nova compute服务德尔run_instance方法
request_spec,
filter_properties,
requested_networks,
injected_files, admin_password,
is_first_time,
instance_uuid=instance_uuid,
legacy_bdm_in_spec=legacy_bdm_in_spec)
except Exception as ex:
# NOTE(vish): we don't reraise the exception here to make sure
# that all instances in the request get set to
# error properly
driver.handle_schedule_error(context, ex, instance_uuid,
request_spec)
# scrub retry host list in case we're scheduling multiple
# instances:
retry = filter_properties.get('retry', {})
retry['hosts'] = []
#通知nova API调度结束
self.notifier.info(context, 'scheduler.run_instance.end', payload)
1.1、获取所有hosts权重排序列表:
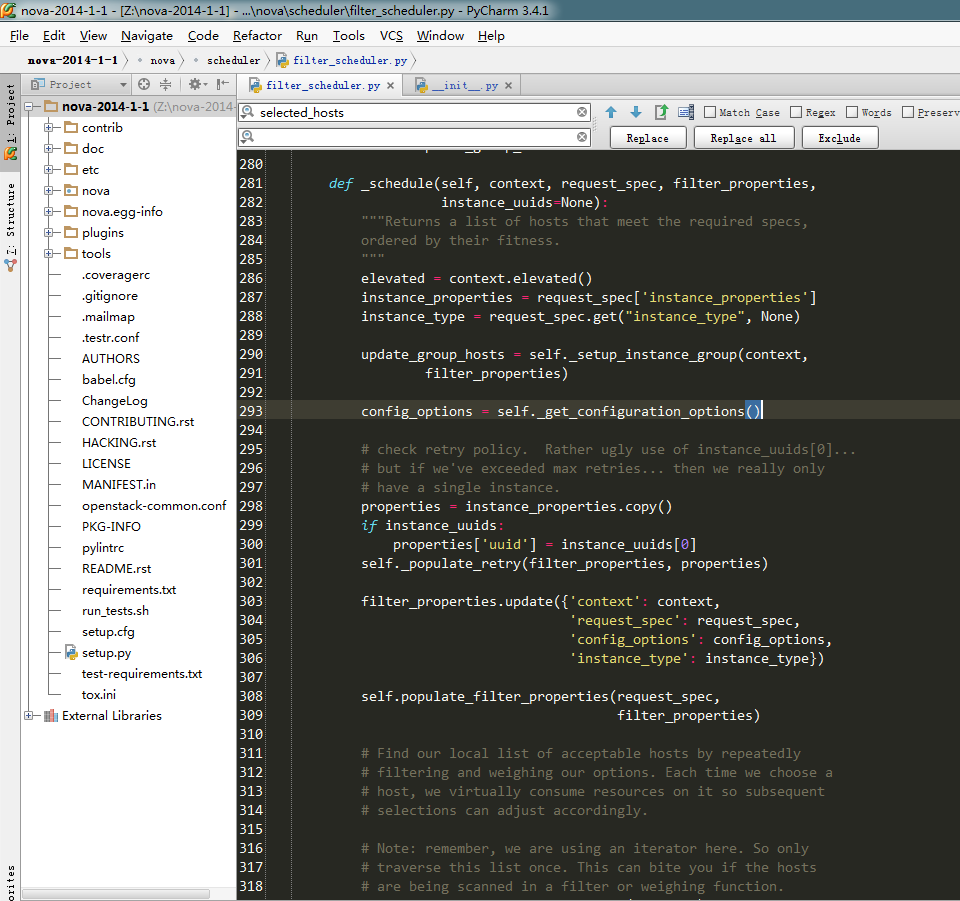
def _schedule(self, context, request_spec, filter_properties,
instance_uuids=None):
"""Returns a list of hosts that meet the required specs,
ordered by their fitness.
"""
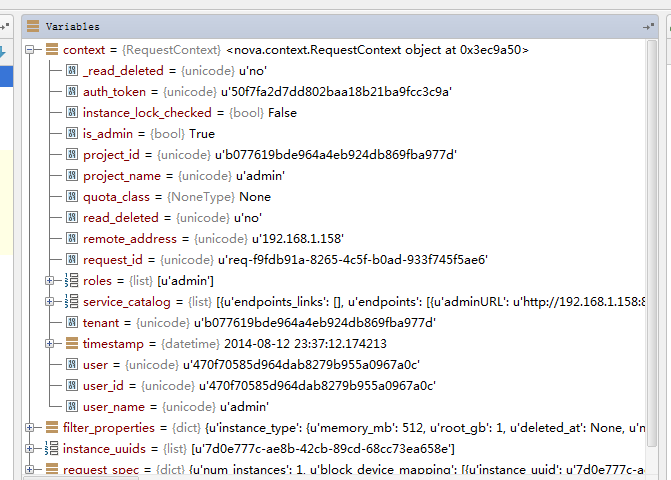
elevated = context.elevated()
#获取上下文信息,参考图1-1context变量值
instance_properties = request_spec['instance_properties']
#获取虚拟机信息
instance_type = request_spec.get("instance_type", None)
#获取虚拟机类型,参考虚拟机类型图1-2
update_group_hosts = self._setup_instance_group(context,
filter_properties)
config_options = self._get_configuration_options()
#获取配置项
# check retry policy. Rather ugly use of instance_uuids[0]...
# but if we've exceeded max retries... then we really only
# have a single instance.
properties = instance_properties.copy()
if instance_uuids:
properties['uuid'] = instance_uuids[0]
self._populate_retry(filter_properties, properties)
#构造主机过滤函数
filter_properties.update({'context': context,
'request_spec': request_spec,
'config_options': config_options,
'instance_type': instance_type})
#构造filter_properties的参数值,增加project_id到filter_properties字典中
self.populate_filter_properties(request_spec,
filter_properties)
# Find our local list of acceptable hosts by repeatedly
# filtering and weighing our options. Each time we choose a
# host, we virtually consume resources on it so subsequent
# selections can adjust accordingly.
# Note: remember, we are using an iterator here. So only
# traverse this list once. This can bite you if the hosts
# are being scanned in a filter or weighing function.
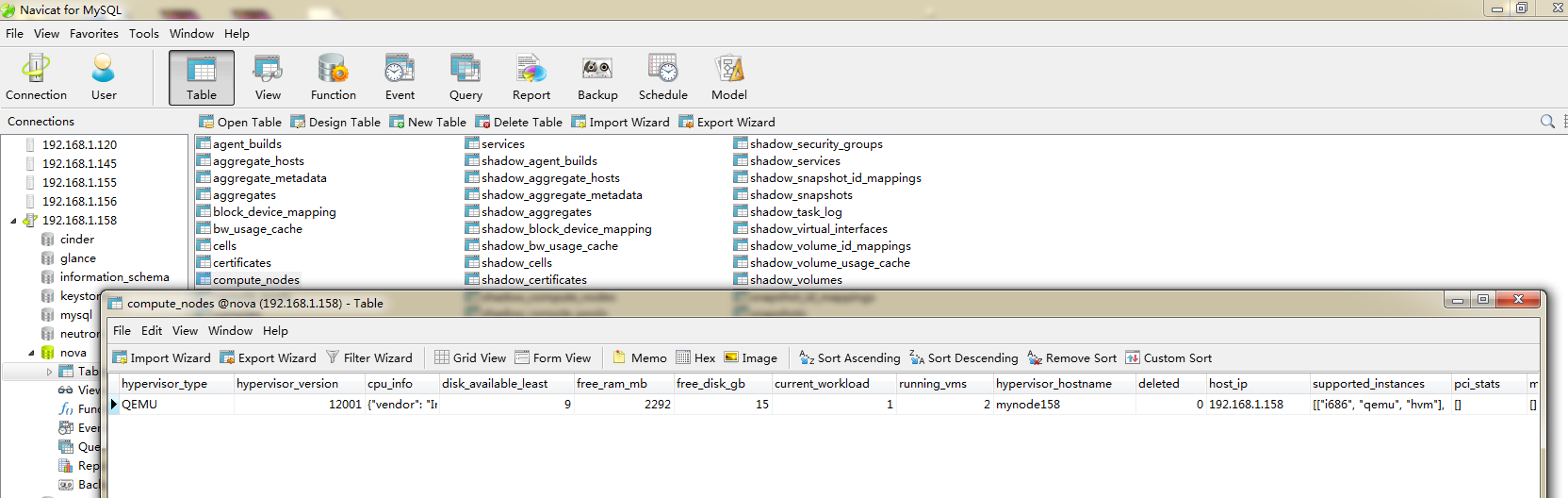
#此处通过db模块从数据库取出compute_nodes表中的所有计算几点状态列表(数据库compute_nodes表图1-3)
#更多参考1-4-1:
hosts = self._get_all_host_states(elevated)
selected_hosts = []
#需要启动的虚拟机数量
if instance_uuids:
num_instances = len(instance_uuids)
else:
num_instances = request_spec.get('num_instances', 1)
#为每个要创建的虚拟机选择权值最高host生成vm
for num in xrange(num_instances):
# Filter local hosts based on requirements ...
hosts = self.host_manager.get_filtered_hosts(hosts,
#过滤相应的hosts(此处会调用相应配置的过滤类),详情参考1.1.1:
filter_properties, index=num)
if not hosts:
#如果没有找到可用host则结束
# Can't get any more locally.
break
LOG.debug(_("Filtered %(hosts)s"), {'hosts': hosts})
weighed_hosts = self.host_manager.get_weighed_hosts(hosts,
#根据过滤后的host列表,得到权重列表,具体参考,1.2.1
filter_properties)
LOG.debug(_("Weighed %(hosts)s"), {'hosts': weighed_hosts})
scheduler_host_subset_size = CONF.scheduler_host_subset_size
if scheduler_host_subset_size > len(weighed_hosts):
scheduler_host_subset_size = len(weighed_hosts)
if scheduler_host_subset_size < 1:
scheduler_host_subset_size = 1
chosen_host = random.choice(
weighed_hosts[0:scheduler_host_subset_size])
selected_hosts.append(chosen_host)
# Now consume the resources so the filter/weights
# will change for the next instance.
chosen_host.obj.consume_from_instance(instance_properties)
if update_group_hosts is True:
filter_properties['group_hosts'].add(chosen_host.obj.host)
return selected_hosts
#图1-1context变量值:
#图1-2:虚拟机类型:

1.1.1过滤忽略的host或者强制生成虚拟机在每个host或者nodes上:
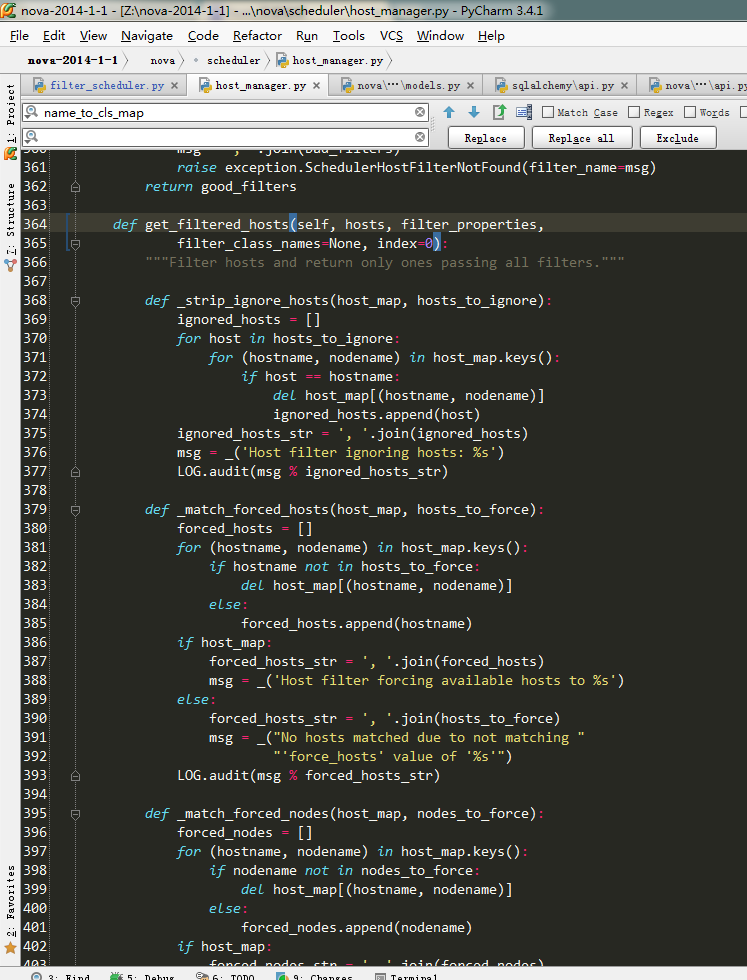
def get_filtered_hosts(self, hosts, filter_properties,
#参数hosts列表为上层获取到的所有计算节点列表
filter_class_names=None, index=0):
"""Filter hosts and return only ones passing all filters."""
#返回通过了所有过滤器过滤的hosts(函数执行入口在下面)
def _strip_ignore_hosts(host_map, hosts_to_ignore):
ignored_hosts = []
for host in hosts_to_ignore:
for (hostname, nodename) in host_map.keys():
if host == hostname:
del host_map[(hostname, nodename)]
ignored_hosts.append(host)
ignored_hosts_str = ', '.join(ignored_hosts)
msg = _('Host filter ignoring hosts: %s')
LOG.audit(msg % ignored_hosts_str)
def _match_forced_hosts(host_map, hosts_to_force):
forced_hosts = []
for (hostname, nodename) in host_map.keys():
if hostname not in hosts_to_force:
del host_map[(hostname, nodename)]
else:
forced_hosts.append(hostname)
if host_map:
forced_hosts_str = ', '.join(forced_hosts)
msg = _('Host filter forcing available hosts to %s')
else:
forced_hosts_str = ', '.join(hosts_to_force)
msg = _("No hosts matched due to not matching "
"'force_hosts' value of '%s'")
LOG.audit(msg % forced_hosts_str)
def _match_forced_nodes(host_map, nodes_to_force):
forced_nodes = []
for (hostname, nodename) in host_map.keys():
if nodename not in nodes_to_force:
del host_map[(hostname, nodename)]
else:
forced_nodes.append(nodename)
if host_map:
forced_nodes_str = ', '.join(forced_nodes)
msg = _('Host filter forcing available nodes to %s')
else:
forced_nodes_str = ', '.join(nodes_to_force)
msg = _("No nodes matched due to not matching "
"'force_nodes' value of '%s'")
LOG.audit(msg % forced_nodes_str)
#函数执行入口(这里将会加载所有配置文件里面配置的过滤器类):
filter_classes = self._choose_host_filters(filter_class_names)
#获取配置文件配置的过滤器类,具体查看1.1.2该函数_choose_host_filters解释
ignore_hosts = filter_properties.get('ignore_hosts', [])
#从参数列表中获取ignore_hosts 、force_hosts 、force_nodes ,其中hostname与nodename区别,见图1-2-2
force_hosts = filter_properties.get('force_hosts', [])
force_nodes = filter_properties.get('force_nodes', [])
if ignore_hosts or force_hosts or force_nodes:
# NOTE(deva): we can't assume "host" is unique because
# one host may have many nodes.#
(一个host可能有多个node)
name_to_cls_map = dict([((x.host, x.nodename), x) for x in hosts])
#其中此处的hosts是由之前代码从数据库获取
if ignore_hosts:
_strip_ignore_hosts(name_to_cls_map, ignore_hosts)
#去掉在忽略列表中的host
if not name_to_cls_map:
return []
# NOTE(deva): allow force_hosts and force_nodes independently
if force_hosts:
#如果hosts的host不在force_hosts里面则去掉
_match_forced_hosts(name_to_cls_map, force_hosts)
if force_nodes:
#如果hosts的host不在force_nodes里面则去掉
_match_forced_nodes(name_to_cls_map, force_nodes)
if force_hosts or force_nodes:
#如果有指定强制生成的host或者node,过滤完毕则直接返回hosts,不再进行后续的过滤
# NOTE(deva): Skip filters when forcing host or node
if name_to_cls_map:
return name_to_cls_map.values()
hosts = name_to_cls_map.itervalues()
#get_filtered_objects详细参考1.1.5:
return self.filter_handler.get_filtered_objects(filter_classes,
hosts, filter_properties, index)
1.1.2:
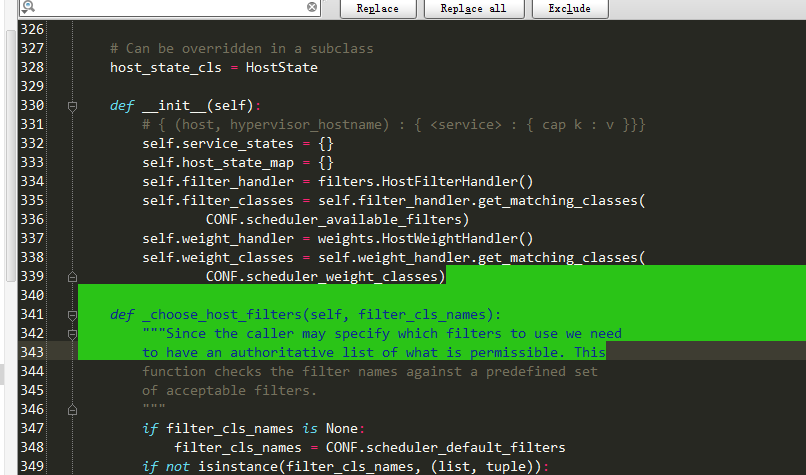
def _choose_host_filters(self, filter_cls_names):
"""Since the caller may specify which filters to use we need
to have an authoritative list of what is permissible. This
function checks the filter names against a predefined set
of acceptable filters.
"""
if filter_cls_names is None:
filter_cls_names = CONF.scheduler_default_filters
//获取配置文件过滤类,配置文件参考图1-2-1
if not isinstance(filter_cls_names, (list, tuple)):
filter_cls_names = [filter_cls_names]
cls_map = dict((cls.__name__, cls) for cls in self.filter_classes)
good_filters = []
bad_filters = []
for filter_name in filter_cls_names:
if filter_name not in cls_map:
bad_filters.append(filter_name)
continue
good_filters.append(cls_map[filter_name])
if bad_filters:
msg = ", ".join(bad_filters)
raise exception.SchedulerHostFilterNotFound(filter_name=msg)
return good_filters
#返回配置文件中的所有过滤类
图1-2-1:

图1-2-2:
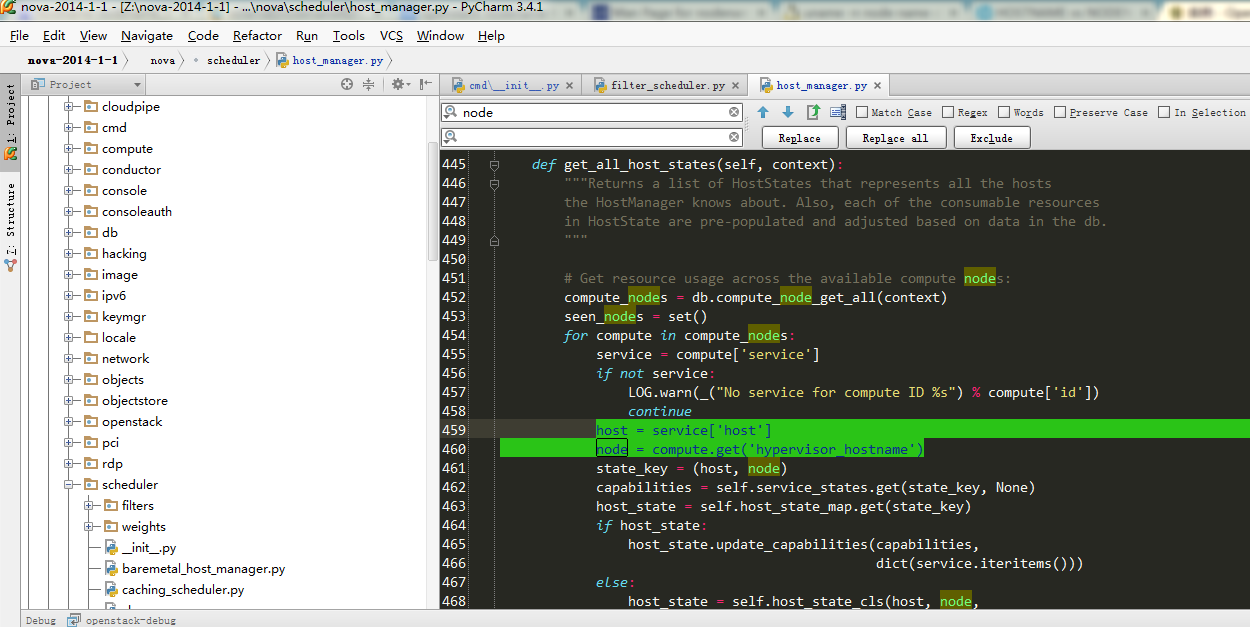
1.1.5:
class BaseFilterHandler(loadables.BaseLoader):
"""Base class to handle loading filter classes.
This class should be subclassed where one needs to use filters.
"""
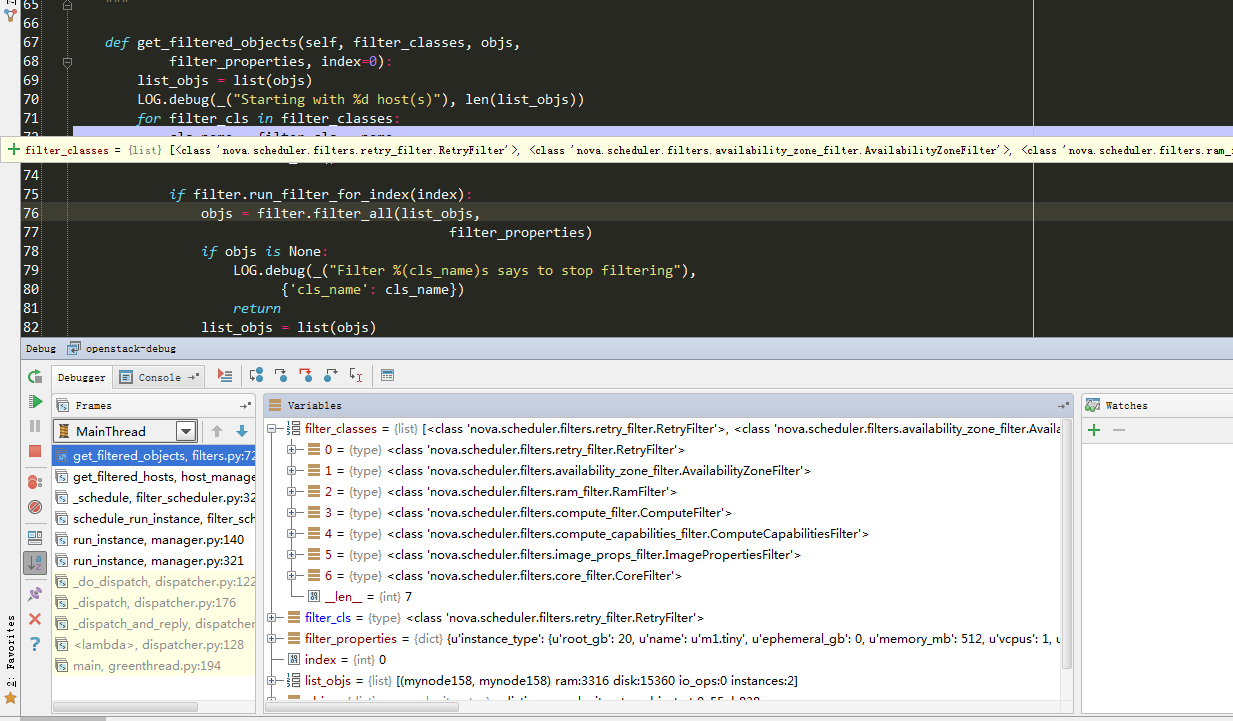
def get_filtered_objects(self, filter_classes, objs,
filter_properties, index=0):
list_objs = list(objs) #
list_objs
值为hosts
LOG.debug(_("Starting with %d host(s)"), len(list_objs))
for filter_cls in filter_classes:
#其中filter_classes为之前获取的配置文件过滤类,具体值见图1-2-3:
cls_name = filter_cls.__name__
filter = filter_cls()
if filter.run_filter_for_index(index):
objs = filter.filter_all(list_objs,
#详解见1.1.6
filter_properties)
if objs is None:
LOG.debug(_("Filter %(cls_name)s says to stop filtering"),
{'cls_name': cls_name})
return
list_objs = list(objs)
if not list_objs:
LOG.info(_("Filter %s returned 0 hosts"), cls_name)
break
LOG.debug(_("Filter %(cls_name)s returned "
"%(obj_len)d host(s)"),
{'cls_name': cls_name, 'obj_len': len(list_objs)})
return list_objs
|
1.1.6:
由于此函数有一定的复制度,接下来以AvailabilityZoneFilter的过滤为例简要讲解:

可以看出调用
AvailabilityZoneFilter的filter_all方法:
其实
AvailabilityZoneFilter没有
filter_all方法,但是父类BaseFilter中有此方法。
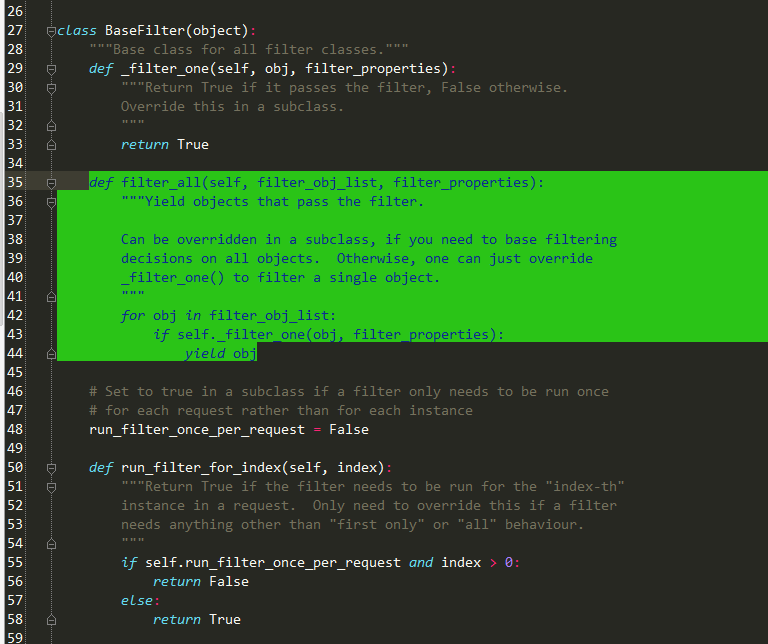
再调用_filter_one:
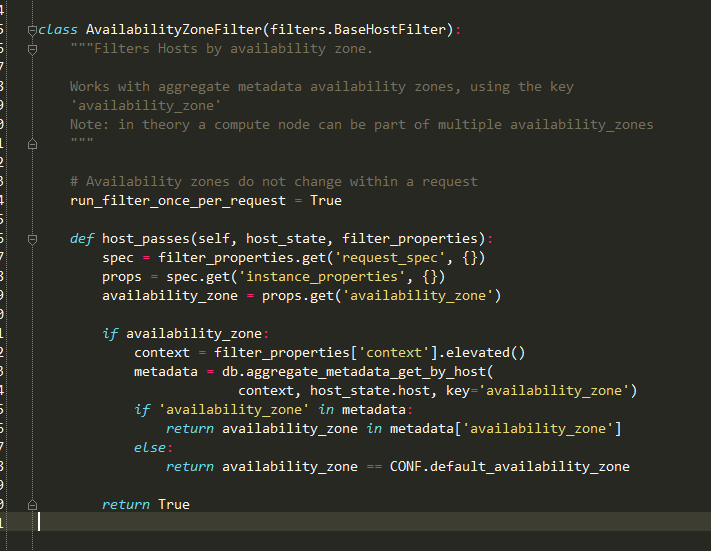
再看子类对filter_one的实现:

从上可以看出每次调用的是自身的host_passes方法:
|
重点在于理解:
def filter_all(self, filter_obj_list, filter_properties):
"""Yield objects that pass the filter.
Can be overridden in a subclass, if you need to base filtering
decisions on all objects. Otherwise, one can just override
_filter_one() to filter a single object.
"""
#此处for循环就是将hosts迭代,看是否满足_filter_one(即过滤器规则),如果为true则用yield语法加入到可迭代的生成器对象中
#更多关于yield语法,请参考博文:Python yield语法 使用实战详解
for obj in filter_obj_list:
if self._filter_one(obj, filter_properties):
yield obj
至此讲解完成如何从数据库取出所有可用的hosts列表,然后根据配置文件,加载对应的过滤类,将满足条件的hosts列表返回,回到1.1讲解 hosts = self.host_manager.get_filtered_hosts函数后面的代码
图1-2-3:
1.2.1:
def get_weighed_hosts(self, hosts, weight_properties):
"""Weigh the hosts."""
return self.weight_handler.get_weighed_objects(self.weight_classes,
#weight_classes参数详解,参见1.3.1
hosts, weight_properties)
1.3.1
nova.conf配置项:
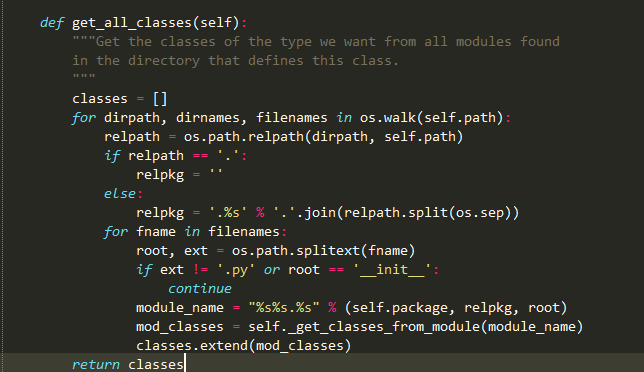
get_all_classes将weights文件夹下面所有的类作为loadable_class_names参数传递给以下函数:
def get_matching_classes(self, loadable_class_names):
"""Get loadable classes from a list of names. Each name can be
a full module path or the full path to a method that returns
classes to use. The latter behavior is useful to specify a method
that returns a list of classes to use in a default case.
"""
classes = []
for cls_name in loadable_class_names:
obj = importutils.import_class(cls_name)
if self._is_correct_class(obj):
classes.append(obj)
elif inspect.isfunction(obj):
# Get list of classes from a function
for cls in obj():
classes.append(cls)
else:
error_str = 'Not a class of the correct type'
raise exception.ClassNotFound(class_name=cls_name,
exception=error_str)
return classes
重点解析权重值计算方法:
class BaseWeightHandler(loadables.BaseLoader):
object_class = WeighedObject
def get_weighed_objects(self, weigher_classes, obj_list,
weighing_properties):
"""Return a sorted (descending), normalized list of WeighedObjects."""
if not obj_list:
#如果host为空,直接返回,obj_list值见图2-1-1:
return []
weighed_objs = [self.object_class(obj, 0.0) for obj in obj_list]
#weighed_objs 值见图2-1-2:
for weigher_cls in weigher_classes:
#weigher_classes值见图2-1-2:(加载了两种权重计算类)
weigher = weigher_cls()
weights = weigher.weigh_objects(weighed_objs, weighing_properties)#更多参照1.3.2:
# Normalize the weights
weights = normalize(weights,
minval=weigher.minval,
maxval=weigher.maxval)
for i, weight in enumerate(weights):
obj = weighed_objs[i]
obj.weight += weigher.weight_multiplier() * weight
return sorted(weighed_objs, key=lambda x: x.weight, reverse=True)
#对权重列表根据权重值进行排序,返回
图2-1-1:
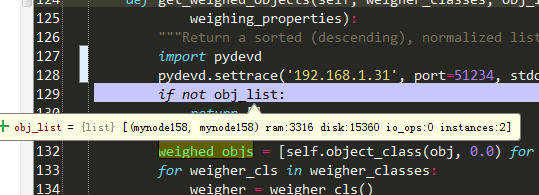
图2-1-2:
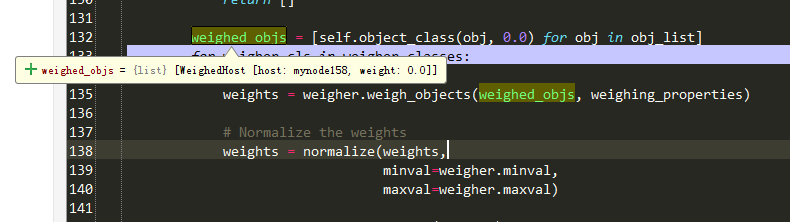
图2-1-3:

1.3.2:
def weigh_objects(self, weighed_obj_list, weight_properties):
"""Weigh multiple objects.
Override in a subclass if you need access to all objects in order
to calculate weights. Do not modify the weight of an object here,
just return a list of weights.
"""
# Calculate the weights
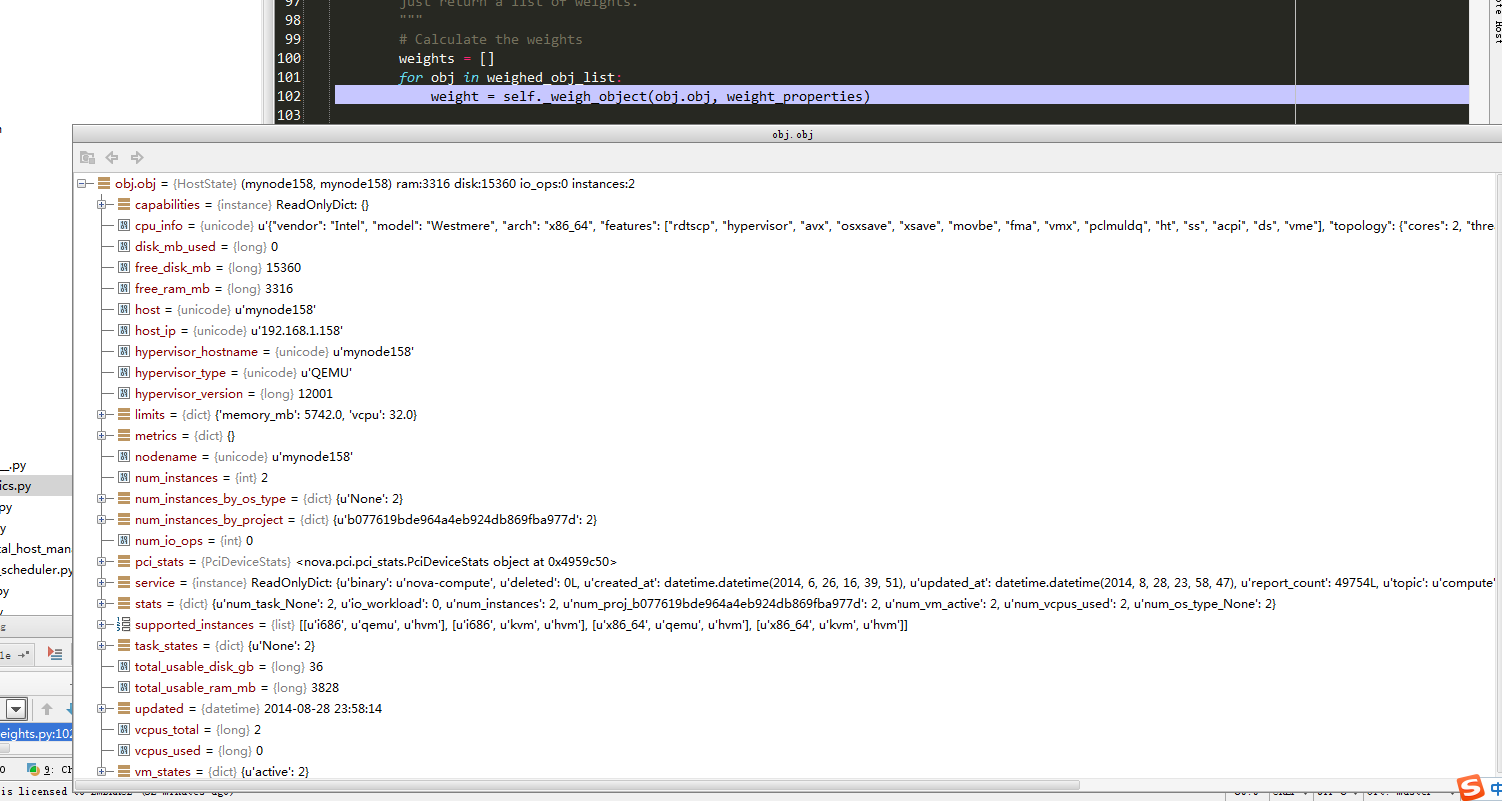
weights = []
for obj in weighed_obj_list:
#将hosts列表迭代,根据每个节点的host_state计算weights列表值、且记录最大最小值
weight = self._weigh_object(obj.obj, weight_properties) #更多参见1.3.3
# Record the min and max values if they are None. If they anything
# but none we assume that the weigher has set them
if self.minval is None:
self.minval = weight
if self.maxval is None:
self.maxval = weight
if weight < self.minval:
self.minval = weight
elif weight > self.maxval:
self.maxval = weight
weights.append(weight)
return weights
1.3.3:
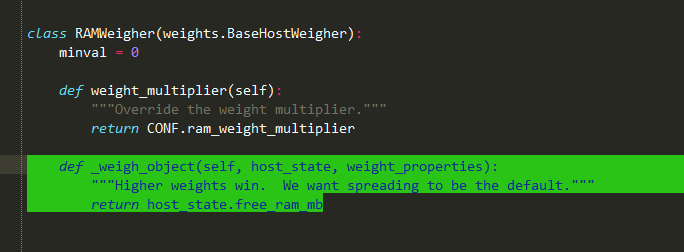
查看host_state数据结构:
以RAMWeigher为例:
_weigh_object就是返回free_ram_mb(剩余内存),更多请参考如何获取host_state讲解。
总结weights:RAMWeigher,则是根据每个节点host_state剩余内存作为权重值计算,剩余内存越多,则权重越大,也就能越先被调度
1-4-1
关于调度算法中host_state讲解:
hosts = self._get_all_host_states(elevated)
def _get_all_host_states(self, context):
"""Template method, so a subclass can implement caching."""
return self.host_manager.get_all_host_states(context)
def get_all_host_states(self, context):
"""Returns a list of HostStates that represents all the hosts
the HostManager knows about. Also, each of the consumable resources
in HostState are pre-populated and adjusted based on data in the db.
"""
# Get resource usage across the available compute nodes:
compute_nodes = db.compute_node_get_all(context)
seen_nodes = set()
for compute in compute_nodes:
service = compute['service']
if not service:
LOG.warn(_("No service for compute ID %s") % compute['id'])
continue
host = service['host']
node = compute.get('hypervisor_hostname')
state_key = (host, node)
capabilities = self.service_states.get(state_key, None)
host_state = self.host_state_map.get(state_key)
if host_state:
host_state.update_capabilities(capabilities,
dict(service.iteritems()))
else:
host_state = self.host_state_cls(host, node,
capabilities=capabilities,
service=dict(service.iteritems()))
self.host_state_map[state_key] = host_state
host_state.update_from_compute_node(compute)
seen_nodes.add(state_key)
# remove compute nodes from host_state_map if they are not active
dead_nodes = set(self.host_state_map.keys()) - seen_nodes
for state_key in dead_nodes:
host, node = state_key
LOG.info(_("Removing dead compute node %(host)s:%(node)s "
"from scheduler") % {'host': host, 'node': node})
del self.host_state_map[state_key]
return self.host_state_map.itervalues()
可以看到host_state是从数据库表中存取的:















 2789
2789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









