







R语言 非标准化求值(Non-standard evaluation, NSE)
非标准化求值(Non-standard evaluation, NSE)在R语言中起着重要的作用,在交互式数据操作中可以简化操作。Hadley Wickham大神的ggplot2,dplyr,plyr 等神器均用到了NSE,但是理解起来比较困难,我们这里做简单介绍.
先来简单认识一下几个函数。
substitute
我们在R终端键入的任何有效语句都是表达式,但这些表达式在输入后即被求值(evaluate)了,获得未经求值的纯粹“表达式”就要使用函数。这样的函数有expression、quote、bquote和substitute这几个常用函数,可以参考
http://developer.51cto.com/art/201306/396747.htm,这里我们重点讲解substitute。
substitute()可以返回表达式,而不是直接求值(evaluation)
ex <- substitute(x+y)
ex## x + yex1 <- substitute(x+y, list(x=1)) # 给其中一个赋值
ex1## 1 + yclass(ex1) # call 类## [1] "call"在画图时使用将表达式嵌入plot中
par(mar = rep(0.1, 4), cex = 2)
plot.new()
plot.window(c(0, 10), c(0, 1))
for (i in 1:9) text(i, 0.5, substitute(sqrt(x, a), list(a = i + 1))) 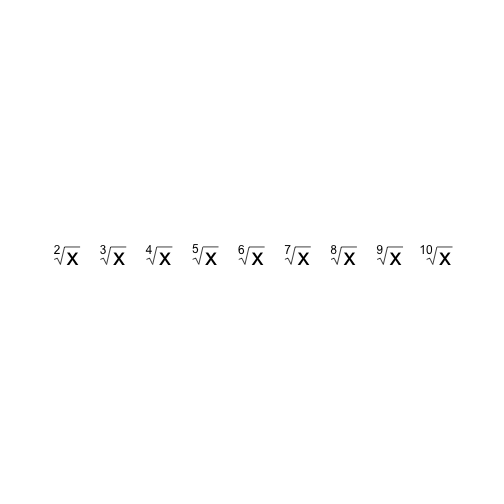
deparse
deparse与substitute 配合使用,可以返回表达式的字符串
g <- function(x) deparse(substitute(x))
g(1:10)## [1] "1:10"g(x)## [1] "x"class(g(x))## [1] "character"g(x + y^2)## [1] "x + y^2"这样的操作就可以在一些特殊的函数中直接使用表达式,而不需要使用字符串.比如说 library(plyr) 与 library(‘plyr’)功能相同.
names
可以返回列名
x <- 1:4
y <- letters[1:4]
names(data.frame(x, y))## [1] "x" "y"以subset为例说明NSE
我们可以直接在subset中输入 表达式 来对数据进行操作
sample_df <- data.frame(a = 1:5, b = 5:1, c = c(5, 3, 1, 4, 1))
subset(sample_df, a >= 4)## a b c
## 4 4 2 4
## 5 5 1 1subset(sample_df, b == c)## a b c
## 1 1 5 5
## 5 5 1 1a,b,c 都是sample_df中的数据而不是全局变量,这就是NSE的实质.
这里我们要获取sample_df 中的 a, b, c,就需要使用 eval().使用eval之前需要使用quote()捕获表达式(quote 跟 substitute 类似,只是只有一个参数,不能做转换).
quote(1:10)## 1:10quote(x)## xquote(x + y^2)## x + y^2eval(quote(x <- 1))
eval(quote(x))## [1] 1y = 1:10
eval(quote(y))## [1] 1 2 3 4 5 6 7 8 9 10#substitute 也是可以的
eval(substitute(y))## [1] 1 2 3 4 5 6 7 8 9 10eval 的第二个参数定义环境变量, 默认为全局变量
x <- 10
eval(quote(x))## [1] 10e <- new.env()
e$x <- 20
eval(quote(x), e)## [1] 20# list 和 dataframe也是可以的
eval(quote(x), list(x = 30))## [1] 30#> [1] 30
eval(quote(x), data.frame(x = 40))## [1] 40那么关于 subset 我们就可以这样写
eval(quote(a >= 4), sample_df)## [1] FALSE FALSE FALSE TRUE TRUEeval(quote(b == c), sample_df)## [1] TRUE FALSE FALSE FALSE TRUE基于以上我们可以写出subset函数
subset2 <- function(x, condition) {
#为 data.frame
condition_call <- substitute(condition)
r <- eval(condition_call, x)
x[r, ]
}
subset2(sample_df, a >= 4)## a b c
## 4 4 2 4
## 5 5 1 1以上就是利用NSE方法构建的subset函数
本文参考:
http://adv-r.had.co.nz/Computing-on-the-language.html
https://cran.r-project.org/web/packages/lazyeval/vignettes/lazyeval.html















 2271
2271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











