







概述
集成学习(ensemble learning)构建多个基础的分类器,然后将多个分类器进行组合的一种学习方式。其通常也被称为多分类器系统(multi-classifer system)。下图显示了集成学习的一种普遍的方式:
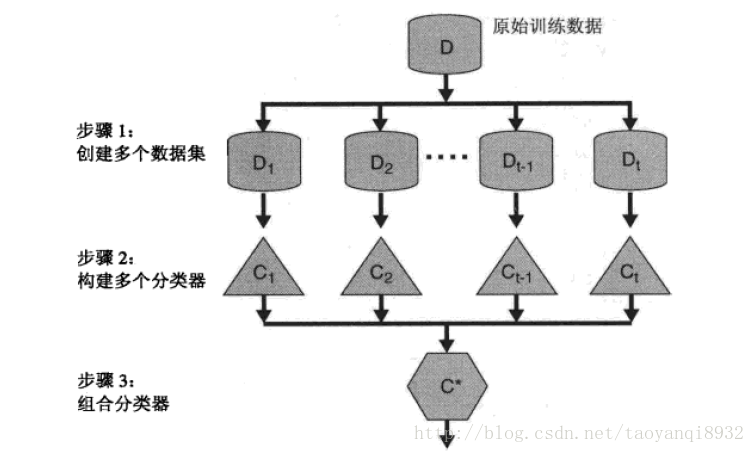
从图中可以看到,首先从原始的数据集中构造多个数据集,然后分别构造单个分类器,最后将这些分类器进行组合的到组合的分类器。
一个很自然的问题:为什么集成学习不任意单分类器的效果好,下面去一个例子进行说明。
假设25个二元的分类器,每个分类器的误差 ϵ=0.35 ,假设组合分类器通过对这些单个分类器进行多数表决的方法,同时假设基分类器是相互独立的(即他们的误差不想关),则只有超过一半的基分类器都分错,最后的结果才是错误的,因此错发的概率为:
这将远低于基分类器,如果基分类器的数目加大,则其会议指数下降,最终会降为0,但是这里是有条件的。
组合分类器性能优于单个分类器要满足两个条件:
- 基分类器之间应该相互独立(相关性不高也可)
- 基分类器应该好与随机猜测分类器(在二分类中应该高于0.5的准确率)
实际上很难保证基分类器上完全独立,因为基分类器是为解决同一个问题而训练出来的,他们显然不独立。但是我们仍然可以看到在基本类其轻微的相关下,组合方法仍然可以提供分类精度。
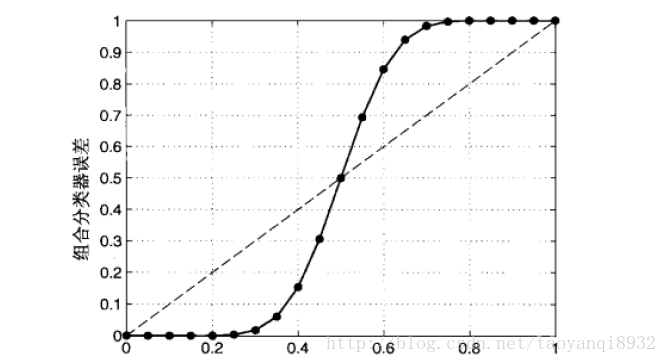
上图中虚线为基分类器,实线为组合分类器。
根据基分类器的生成方式,目前的集成学习可以分为两大类:
- 个体的学习器之间存在着很强的依赖关系,必须串行生成序列话的方法,代表的是Boosting
- 令一种不存在强的依赖关系,可以同时生成的并行化方法,代表Bagging,Random Forest
Bagging
Bagging(装袋)又称为自助聚集(bootstrap aggregating),其思想非常的简单,它得到不同数据集的方式是均匀的概率从训练集中重复的抽样,这里的抽样是有放回的抽样,因此有时一个样本可能被抽到很多次,而有的样本可能一次也没有被抽到。一般来说自助样本的包含设63%的原始训练数据,因为:
假设共抽取N个样本,则N次都为为抽到的概率为:
则一个样本被抽到的概率为:
因此当N很大时:
这样,在一次bootstrap的过程中,会有36%的样本为被采样到,它们被称为out-off-bag,oob,这是自助采样带给bagging的里一个优点,因为我们可以用oob进行“包外估计”out-of-bag estimate。
bagging的算法流程:

来源:数据挖掘导论
下面给出基于CART算法的分类结果:(关于CART参考: 统计学习方法–决策树 )
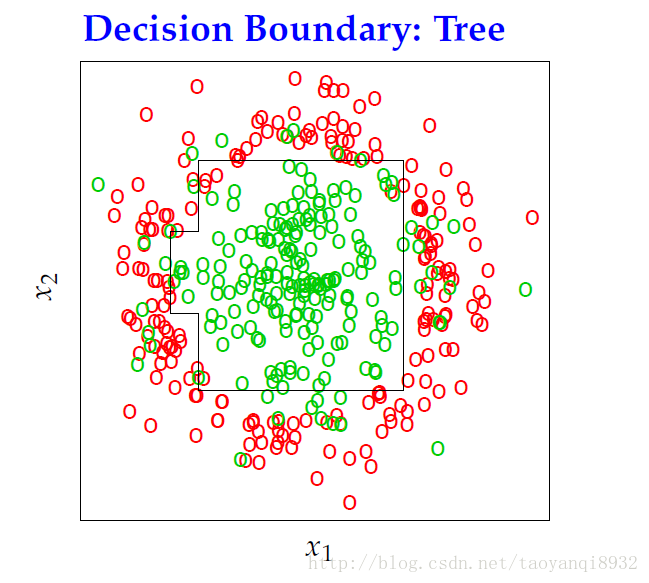
而用bagging给出的结果:
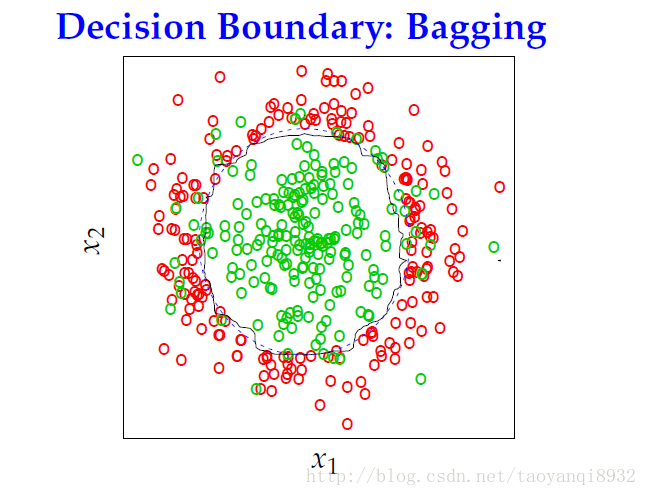
可以看出其明显的优于CART的一颗决策树,bagging平均了很多决策树,产生了更加灵活的决策边界。
小结:
bagging通过降低基分类器的方差改善了泛化误差,bagging的性能依赖与基本类其的稳定性。如果基分类器实不稳定的,bagging有助于减少训练数据的随机波动导致的误差,如果基分类器实问题定的,即对训练数据集中的微小变化是鲁棒的,则组合分类器的误差主要有基分类器偏移所引起的,这种情况下,bagging可能不会对基分类器有明显的改进效果,甚至可能降低分类器的性能。
Random Forest
随机森林(Random Forest)是bagging的一个扩展辩题,其实专门为决策树分类器设计的一种组合方法,它组合多颗决策树作出预测,一般采用的是让基分类器进行投票表决,从而得到最后的结果。
简单的来说,随机森林有两个随机的过程:
第一个随机过程为:随机的又放回采样,这里和bagging一样是有放回的采样方式。
第二个随机过程为:随机的从m个特征中选择k个特征作为决策树的训练。
关于在每一颗弱小的分类器中特征个数的选择,一般推荐 k=log2m 。
从上面可以看出随机森林的算法原来非常的简单,容易实现而且算法的开销小,但是它在实际的任务中展现的强大的实力,同时随机森林有效的避免了overfiting,注意因为它的两个随机的过程,因为每一个树都不一样,每个数都很弱小,即使数很多,也不会overfiting
小结
1. random forest的性能要高于decision tree,同时应当注意到决策树是一种确定性的算法,即无论跑多少遍程序,生成的都是同样的一个树,而随机森林每一次跑出的结果都是不同的。
2. random forest的收敛性与bagging相似,如下图所示:
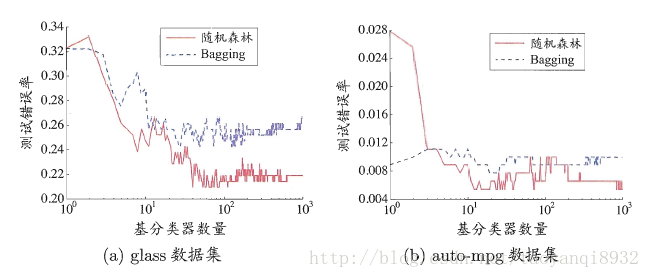
来源:机器学习
通过上图可以看到,随机森林在基分类器较少的时候性能低于bagging,很容易理解,因为随机森林加入了特征的干扰(随机的选择特征),但是随着学习数目的增加,随机森林通常会收敛到更低的泛化误差。
Boosting
提升(boosting)是一种常用的统计学习方法,它通过自适应的改变训练样本的权重,学习多个分类器,并将这些分类器进行线性的组合,提供分类的精度。booting学习得到的基本分类器具有很强的相关性。
提升方法两个关键性的问题:
1. 在每一轮的提升时,如何改变训练数据的权重或概率分布
2. 如何线性的组合每个分类器给出的预测
因此许多的提升算法大部分具有以上两个部分的差别。
下面将介绍一下boosting的方法。
AdaBoost
AdaBoost是boosting算法的代表性算法,AdaBoost对提升的两个关键性的问题中,其在每一轮的提升后,提高那些被前一轮弱分类其错误分类样本的权重,而降低那些被正确分类样本的权重,这样那些没有得到正确分类的数据,优于权重的加大而受到后一轮弱分类其的关注。
第二个问题,AdaBoost采取加权多数表决的方法,即加大误差错误率小的分类器的权重,使其在表决过程中起着主要的作用,而减少分类误差较大的权重。
令
{xj,yj|j=1,2,...N}
表示包含有N个样本的训练集,其中
xj
为第 j个训练样本,它是一个向量,包含许多的特征,
yj∈{−1,1}
。
其中基分类器
Ci
表示第
i
次提升的重要性有其分类的错误率
上述表达的意思是在第 i 轮提升是分类的错误率。
则基本类 Ci 的 重要性为,即最好线性组合是的权重:
其图形如下所示:
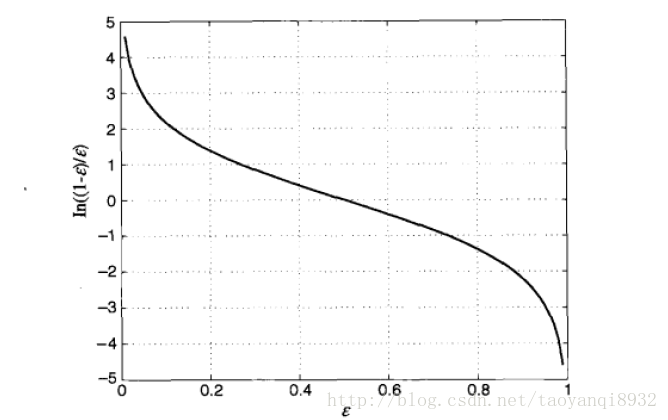
可以看到当错误率接近为0时,其
αi
是一个很大的正值,表明了它在最后的决策中占了主要的作用。
参数
αi
不仅会用到最后的决策过程,还用来更新训练样本的权值,假定
wji
表示第 j 轮提升时第 i 个样本的权值,则在下一轮:
上式中如果 yi=Cj(xi) 则相乘为1,否则为0,其中 Zj 是正规因子,用来确保 ∑iwj+1i=1 ,其值为:
最终的分类器为基本分类器的线性组合:
算法的流程如下图所示:

需要注意的是,每一轮的提出过程中要检验当前的基分类器是否满足条件,在第8行显示,如果误差大于0.5,则重新设置样本的权重,进行再次训练。
因为其更倾向于关于那些被错误分类的样本,因此提升技术很容易受到过拟合的影响。
GBDT

来源:七月在线
上图的意思为GBDT在计算每一轮的误差不是简单的判断是否相等,而是根据一种计算误差的方法如MSE去计算误差。

XGBOOST

为了不让其收敛的过于快和过拟合,因此加入正则化项,减少过拟合。

不同方法的比较
在上述的三种集成学习的方法中,bagging,random forest 不易过拟合,因为每棵树,基本不同,特别是随机森林,但是boosting会有过拟合的影响。
实验表明,随机森林的分类精度可以和AdaBoost相媲美,他对噪声更加鲁棒,运行速度比AdaBoost快的多。
下图给出三种方法的比较:
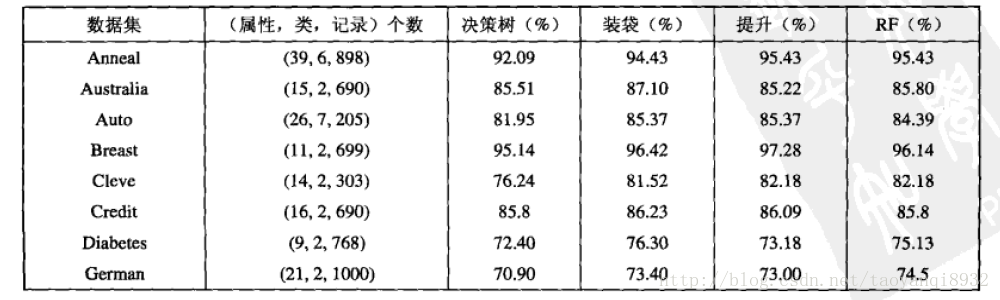
来源:数据挖掘导论
参考资料:
1.Ji Zhu, Michigan Statistics
2.统计学习方法
3.机器学习
4.数据挖掘导论
5.七月在线
6.http://blog.csdn.net/abcjennifer/article/details/8164315














 4235
4235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









