







在现今的推荐技术和算法中,最被大家广泛认可和采用的就是基于协同过滤的推荐方法。
协同过滤(Collaborative Filtering, 简称CF) 是利用集体智慧的一个典型方法。换句话说,就是借鉴和你相关人群的观点来进行推荐。
MLlib中的协同过滤,常应用于推荐系统。
利用某兴趣相投、拥有共同经验之群体的喜好,来推荐使用者感兴趣的资讯,补充用户-商品(User-Item)效用矩阵中所缺失的部分
MLlib当前支持基于模型的协同过滤,其中用户和商品通过一小组隐语义因子进行表达,并且这些因子也用于预测缺失的元素。
为此, MLlib实现了交替最小二乘法(ALS) 来学习这些隐性语义因子。
基于用户的协同过滤(User CF)
基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。上述过程就属于User CF。
基于物品的CF(Item CF)
原理和基于用户的CF类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。
两者的计算复杂度和适用场景皆不同
图书推荐的例子

数据格式:“用户 书 打分”
用户1和5,具有相同的兴趣。他们都喜欢101这本书,对102的喜欢弱一些,对103的喜欢更弱
用户1和4,具有相同的兴趣,他们都喜欢101和103,没有信息显示用户4喜欢102。
用户1和2,兴趣好像正好相反,用户1喜欢101,但用户2讨厌101,用户1喜欢103而用户2正好相反。
用户1和3,交集很少,只有101这本书显示了他们的兴趣
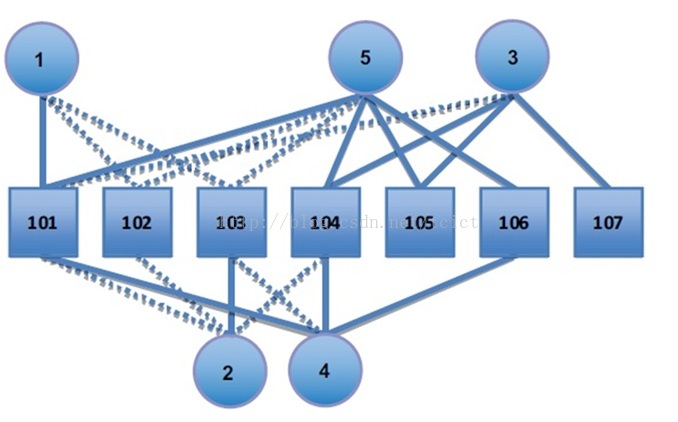
那么应该给用户1推荐哪本书?不是101, 102或者103,因为用户已购买,推荐系统需要发现新的事物。
直觉上,用户4、5与用户1类似,所以推荐一些用户4和5喜欢的书籍,给用户1是不错的。
这样使得104、105和106成为可能的推荐。
整体上看,104是最有可能的一个推荐,这基于104的4.5和4.0的偏好打分。
大部分的推荐系统,通过给item评价打分来实现。
评价推荐系统的一种方式,是评价它的评估偏好值的质量
评价评估偏好和实际偏好的匹配度。
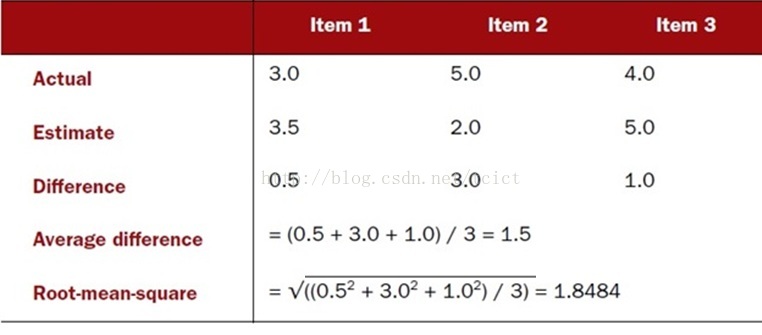
训练集和打分
计算评估值和实际值之间的平均距离,分值越低越好。
0.0表示非常好的评估 ,这说明评估值和实际值根本没有差距
可以通过和其它朋友共同喜欢某个或某类影片,来确定用户相似
通常是通过“距离”来表示相似
例如:欧几里得距离、皮尔逊相关度、曼哈顿距离、Jaccard系数等等。
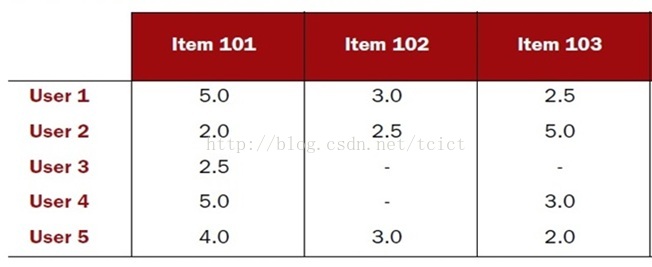
根据上述“距离”的算法,可以找出与自己“口味一样”的人了,但这并不是目的。目的是找出推荐的物品。
协同过滤(Collaborative Filtering, 简称CF) 是利用集体智慧的一个典型方法。换句话说,就是借鉴和你相关人群的观点来进行推荐。
MLlib中的协同过滤,常应用于推荐系统。
利用某兴趣相投、拥有共同经验之群体的喜好,来推荐使用者感兴趣的资讯,补充用户-商品(User-Item)效用矩阵中所缺失的部分
MLlib当前支持基于模型的协同过滤,其中用户和商品通过一小组隐语义因子进行表达,并且这些因子也用于预测缺失的元素。
为此, MLlib实现了交替最小二乘法(ALS) 来学习这些隐性语义因子。
基于用户的协同过滤(User CF)
基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。上述过程就属于User CF。
基于物品的CF(Item CF)
原理和基于用户的CF类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。
两者的计算复杂度和适用场景皆不同
图书推荐的例子
数据格式:“用户 书 打分”
用户1和5,具有相同的兴趣。他们都喜欢101这本书,对102的喜欢弱一些,对103的喜欢更弱
用户1和4,具有相同的兴趣,他们都喜欢101和103,没有信息显示用户4喜欢102。
用户1和2,兴趣好像正好相反,用户1喜欢101,但用户2讨厌101,用户1喜欢103而用户2正好相反。
用户1和3,交集很少,只有101这本书显示了他们的兴趣
那么应该给用户1推荐哪本书?不是101, 102或者103,因为用户已购买,推荐系统需要发现新的事物。
直觉上,用户4、5与用户1类似,所以推荐一些用户4和5喜欢的书籍,给用户1是不错的。
这样使得104、105和106成为可能的推荐。
整体上看,104是最有可能的一个推荐,这基于104的4.5和4.0的偏好打分。
大部分的推荐系统,通过给item评价打分来实现。
评价推荐系统的一种方式,是评价它的评估偏好值的质量
评价评估偏好和实际偏好的匹配度。
训练集和打分
计算评估值和实际值之间的平均距离,分值越低越好。
0.0表示非常好的评估 ,这说明评估值和实际值根本没有差距
可以通过和其它朋友共同喜欢某个或某类影片,来确定用户相似
通常是通过“距离”来表示相似
例如:欧几里得距离、皮尔逊相关度、曼哈顿距离、Jaccard系数等等。
根据上述“距离”的算法,可以找出与自己“口味一样”的人了,但这并不是目的。目的是找出推荐的物品。














 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









