







通过python来完成,更加的简单
#encoding=utf-8
import os
import tensorflow as tf
from PIL import Image
cwd = os.getcwd()
#图片文件夹目录,可有多层
classes = {'tensor'}
def create_record():
writer = tf.python_io.TFRecordWriter("train.tfrecords")
for index, name in enumerate(classes):
class_path = cwd +"/"+ name+"/"
for img_name in os.listdir(class_path):
img_path = class_path + img_name
img = Image.open(img_path)
img = img.resize((224, 224))
img_raw = img.tobytes() #将图片转化为原生bytes
example = tf.train.Example(
features=tf.train.Features(feature={
"label": tf.train.Feature(int64_list=tf.train.Int64List(value=[index])),
'img_raw': tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_raw]))
}))
writer.write(example.SerializeToString())
writer.close()
'''
data = create_record()
'''
这样会在当前目录下生成一个traintfrecords二进制文件
------------------------------------------------------------------------------------------------------------------
下面一篇是我转的一篇通过C++来操作的
文章链接: http://blog.csdn.net/yhl_leo/article/details/50801226
说明一下,这是一篇在window下操作的,换到ubuntu下请各位自行解决,博客质量是不错的,自己制作很不错。
前一篇博客:C/C++ 图像二进制存储与读取中,已经讲解了如何利用C/C++的方法存储与读取二进制图像文件,本文继续讲述如何根据CIFAR-10的格式制作自己的数据集。
所述博文与代码均已同步至GitHub:yhlleo/imageBinaryDataset
主要代码文件有三个:
BinaryDataset.hBinaryDataset.cppmain.cpp
以main.cpp给出的一个小demo为例,首先指定一个原数据图片所在的文件夹:
- 1
- 1
然后,自动获得该文件下的所有图片文件名:
- 1
- 1
这里有一点需要说明一下,getFileLists()是按照文件名升序顺序读取(大家都知道,文件名为字符串,comparable),文件命名最好不要以1, 2, ..., 11, ...这种方式存储,因为这么存,你就会发现1之后的文件可能不是你想的2, 3, 4, ...,而是11, 12, 13, ...。
如果你想按照顺序的某一堆数据是一种类别(我是这么做的,因为便于产生对应的labels),建议使用等宽零位补齐的方式命名,例如:00001, 0002, ..., 0011, ...,那么文件读取的顺序就会如我们所设定。
总结一下实现方法(仅供参考):
- 采集样本的时候可以先类别存于不同的文件夹,命名就随意吧,如果是使用一些抠图软件,也不用纠结一个一个手工修改成自己想要的命名(这么做工作量很大,真的很蛋疼。。。);
- 每一类数据整理好后,依次将每一类的数据,用程序读取并另存一份(读取使用
getFileLists(),反正是一类的,也无所谓先后顺序):
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 后面的其他类别也可以这样,为了按照顺序区分,依次进行其他类别的时候,只需要在改动文件夹后,将
sprintf(curfile, "C:\\Samples\\class-1\\%04d.jpg", i);中的第三个参数i改为i+k,这里k是前面一类或几类的样本总数。 - 最后,将重新命名的文件,存在一个文件夹里,记清楚类别对应的区间范围,以便生成
labels。
读取上述最终文件内的所有文件,接下来,生成labels(labels一般用[0, 9]组成的整数字):
- 1
- 1
当然,你也可以用image_labels.push_back()把所有的labels设置,但是熟悉vector的话,就会明白使用初始化长度,比那种做法更加高效(可以阅读本人的博客: C++ 容器(一):顺序容器简介)。然后就相应地修改某些索引区间内的label值:
- 1
- 2
- 1
- 2
都准备好后,就可以开始生成想要的二进制文件了:
- 1
- 2
- 1
- 2
到这里,已经制作好了二进制数据集,我很懒,想直接基于tensorflow/models/image/cifar10模块的源码跑我定义的数据集,想想只要跟cifar10数据集类似,那肯定没什么问题,下面是官网上下载的cifar-10-binary.tar解压后内容:
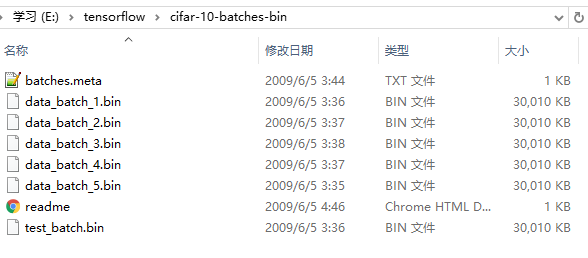
这份数据集比较大,训练样本有50000,测试样本10000(我的数据集并没有这么大,但是又有什么关系呢!)。
看,这是我的数据集:

是不是很迷你~
然后,将tensorflow/models/image/cifar10模块的拷贝中的部分参数修改成为适合自己数据集的,就OK了~
献上运行截图(训练测试集有5196张样本,所以5196*0.4 = 2078):
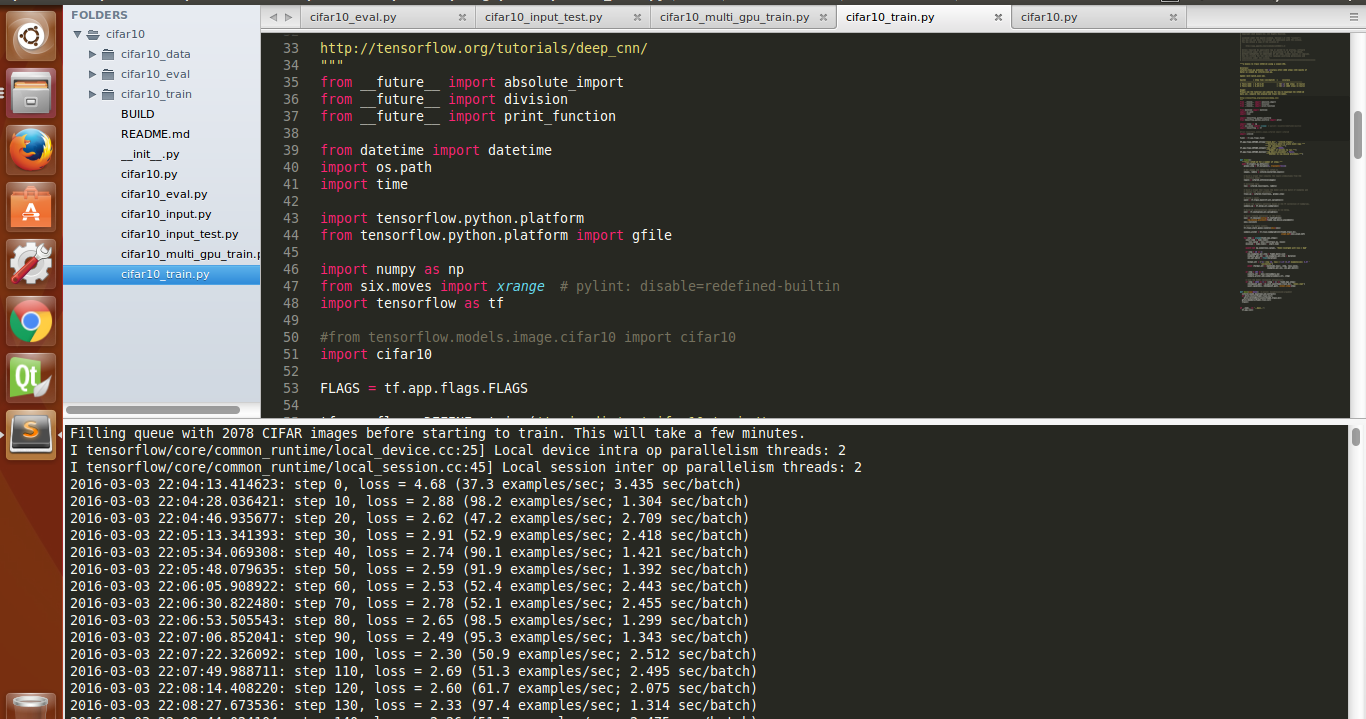
训练了两天,跑完后,评估精度为:0.896。















 3396
3396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









